From Sparse Vector to Embeddings with Encoder–Decoder Structure
- 求 Embeddings
- Encoder–Decoder 結構
字典向量
若我們字典裡有 $N$ 個 words, 第 $i$ 個字 $w^i$ 應該怎麼表示呢?
通常使用 one-hot vector 來表示: 把 $w^i$ 變成一個長度 $N$ 的向量 $x^i$。
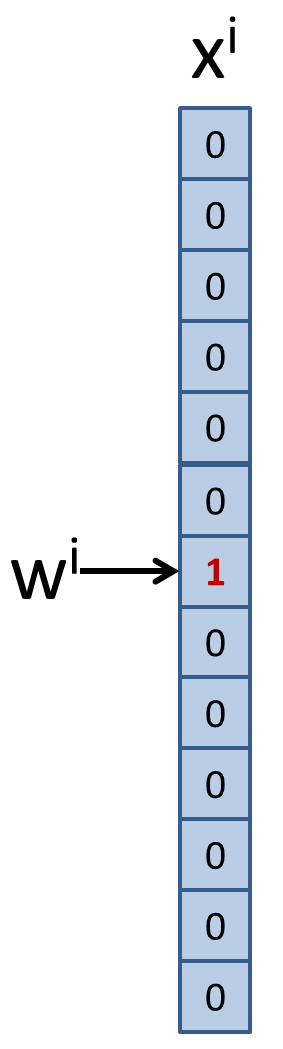
恭喜! 有了 vector 我們就可以套用數學模型了。
問題是這樣的向量太稀疏了,尤其是當字典非常大的時候。
稀疏向量對於模型訓練很沒有效率。
我們需要轉換到比較緊密的向量,通常稱為 embedding。
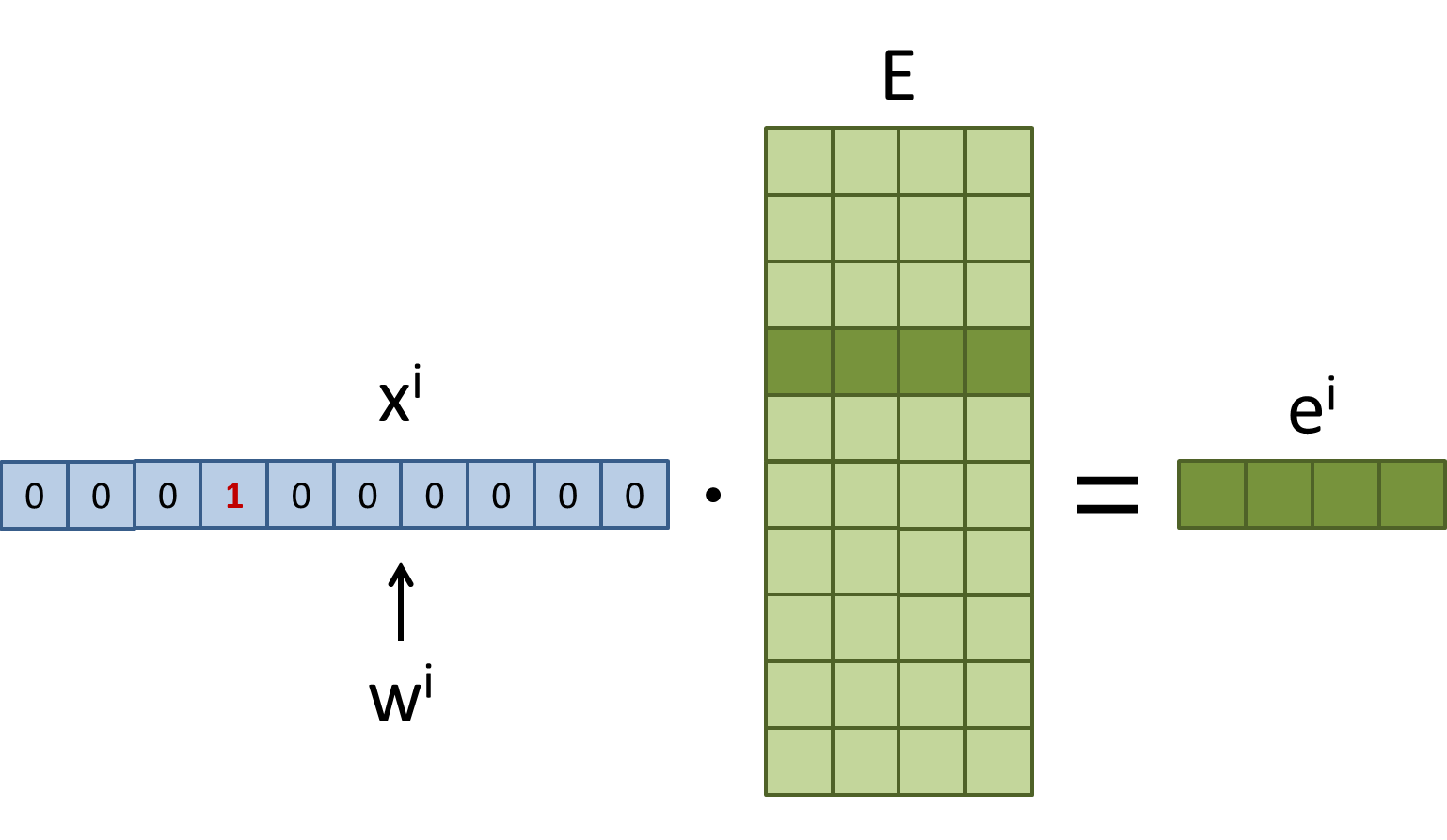
下圖舉例將 $x$ 對應到它的緊密向量 $e$, 緊密向量有 embed_dim 維度
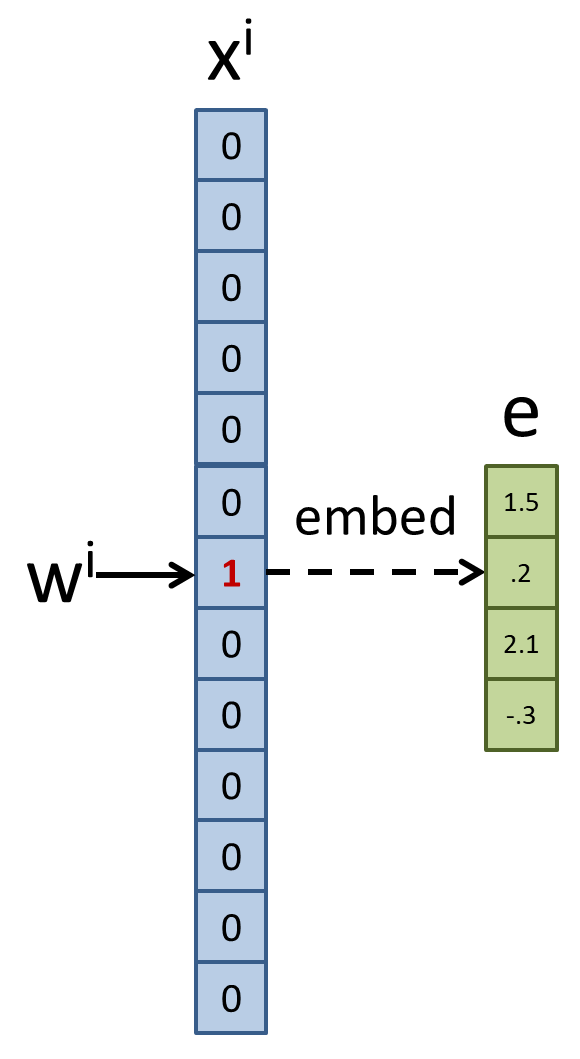
先假設已知如何對應到緊密向量
已知一個 N * embed_dim 的矩陣 $E$,第 $i$ 個 row $e^i$ 就是 $w^i$ 的 embedding。
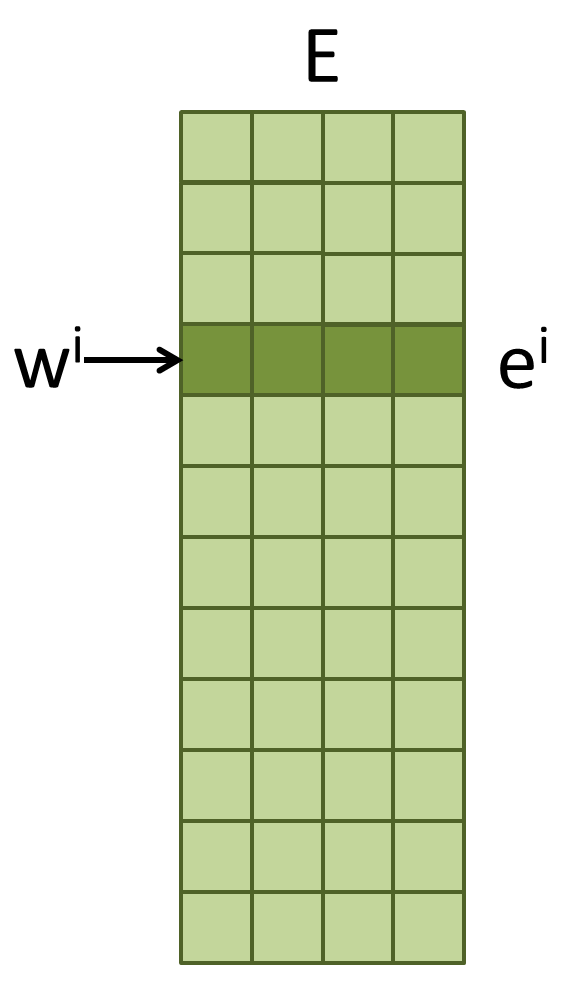
我們就可以使用 $e$ 來代替原先的稀疏向量 $x$ 進行訓練,讓訓練更好更容易。
以一個語言模型來說,使用 LSTM 模型如下:
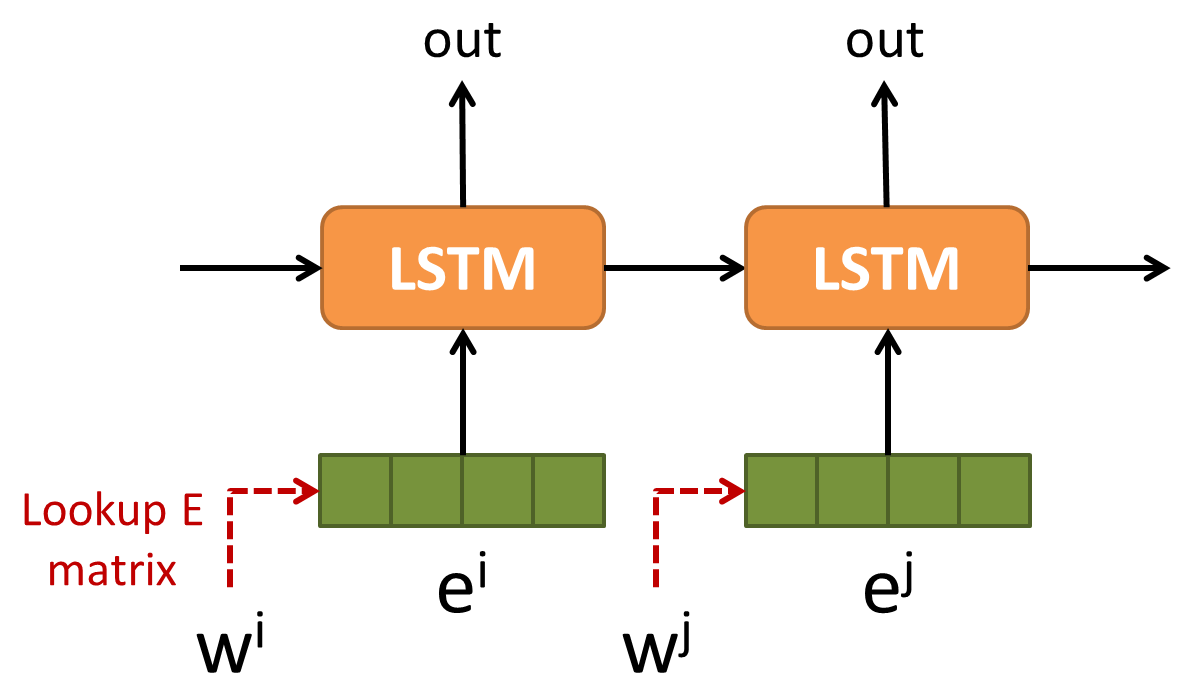
恩,這樣大功告成,我們的模型可以順利訓練 …. ??
不對,$E$ 這個 lookup table 怎麼決定?
Lookup Table 使用矩陣相乘
答案是讓模型自己訓練決定。要更了解內部運作,我們先將 lookup table 使用矩陣相乘的方式來看。
所以使用 lookup table LSTM 的語言模型變成如下
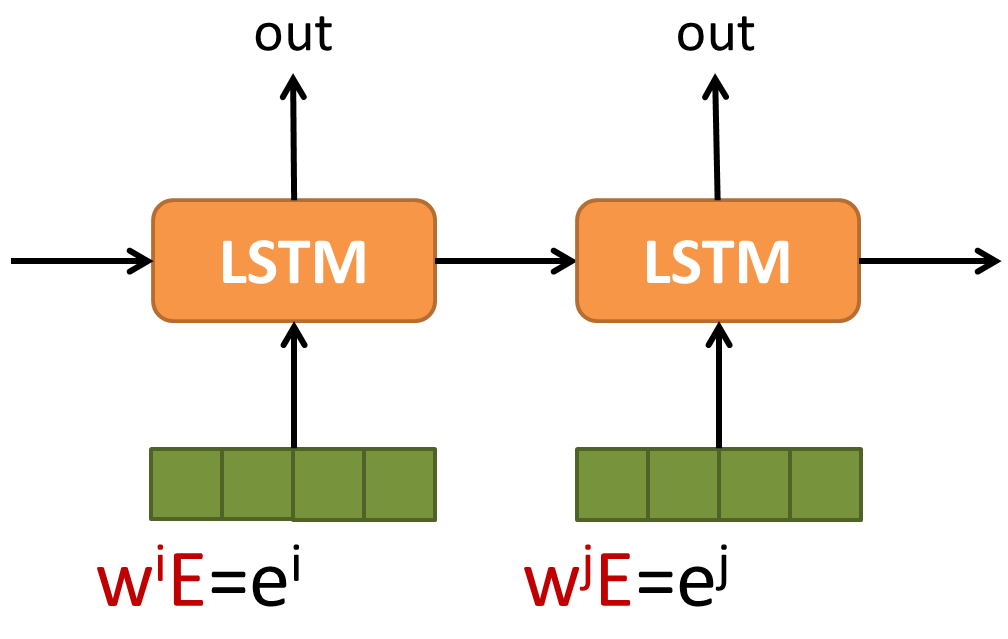
等等,矩陣相乘不就跟 neural net 一樣嗎?
這樣看起來這個 lookup table $E$ 就是一層的類神經網路而已 (沒有 activation function)。
我們用 LL (Linear Layer) 來代表,$E$ 就是 LL 的 weight matrix。
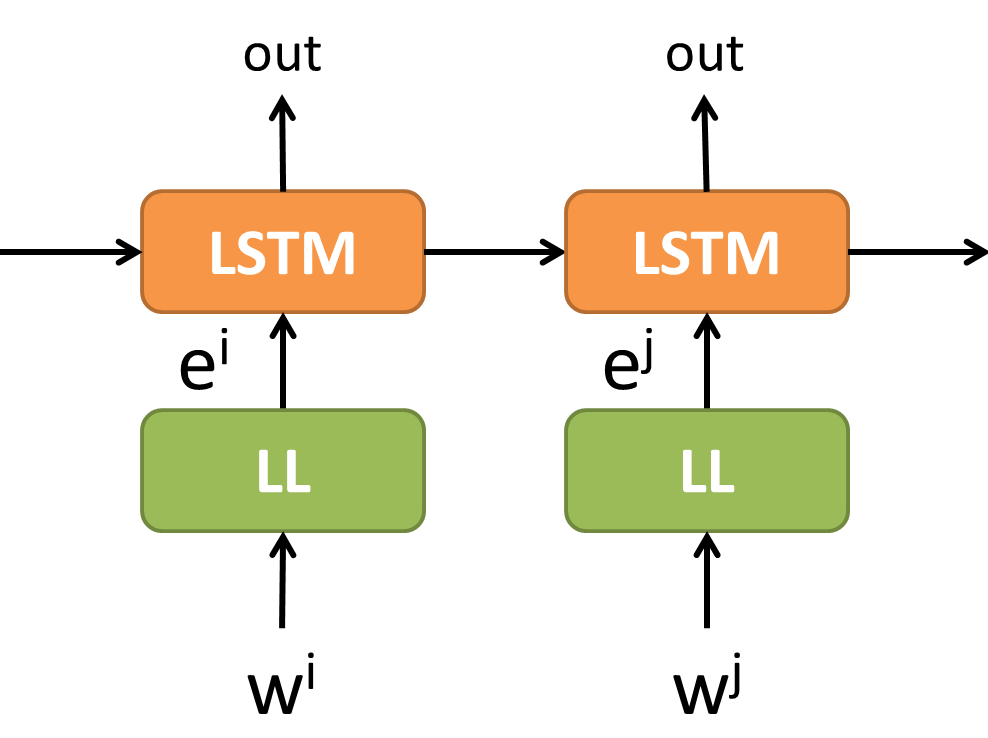
表示成 neural net 的方式,我們就直接可以 Backprob 訓練出 LL 的 weight $E$ 了。而 $E$ 就是我們要找的 embeddings。
- Tensorflow 中做這樣的 lookup table 可以使用 tf.nn.embedding_lookup()。
- Embedding 的作法可參考 tf 官網此處。
LL很弱怎麼辦?
只用一層線性組合 (LL) 就想把特徵擷取做到很好,似乎有點簡化了。
沒錯,我們都知道,特徵擷取是 Deep neural net 的拿手好戲,所以我們可以將 LL 換成強大的 CNN。
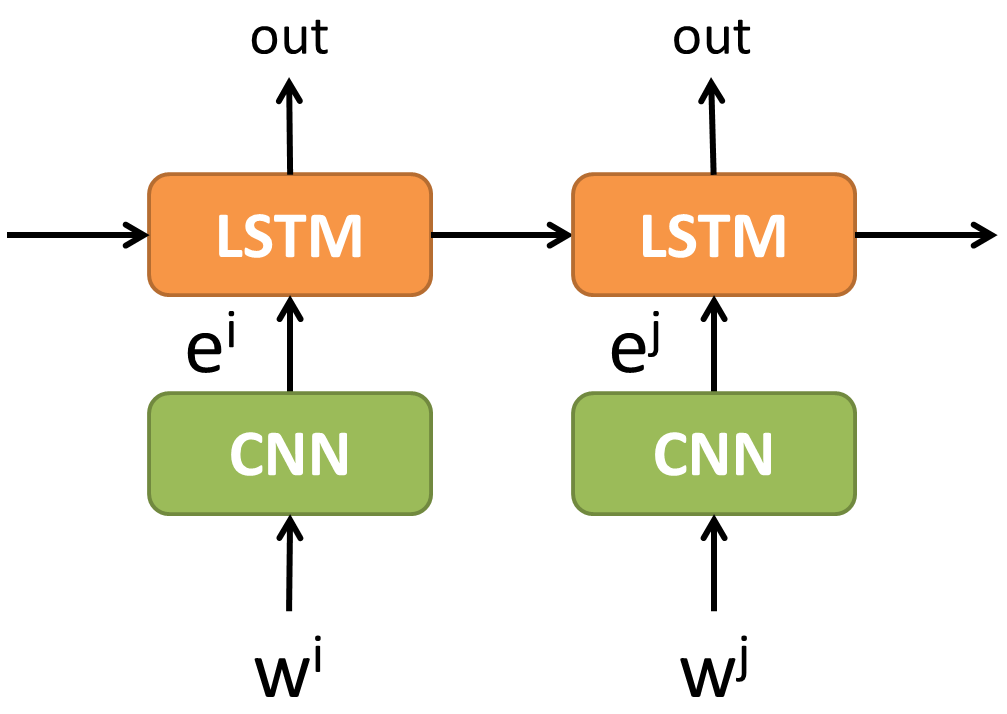
這種先經過一層特徵擷取,再做辨識,其實跟 Encoder – Decoder 的架構一樣。
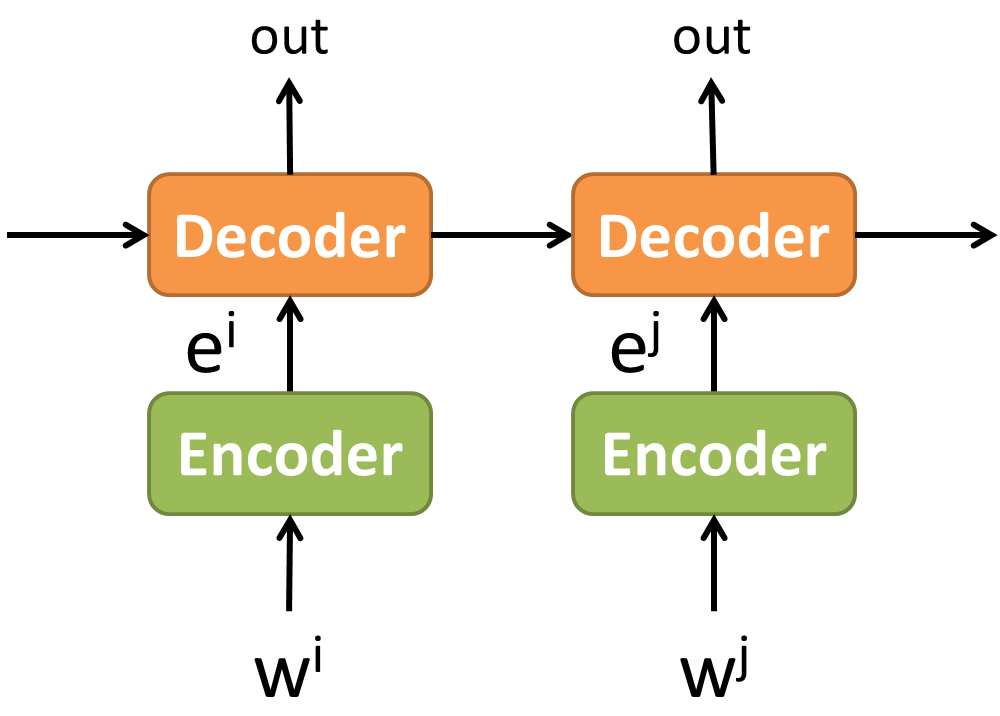
都是先經過 Encoder 做出 embeddings,接著使用 Embeddings decode 出結果。
Encoder 如果也採用 RNN 的話基本上就是 sequence-to-sequence 的架構了。
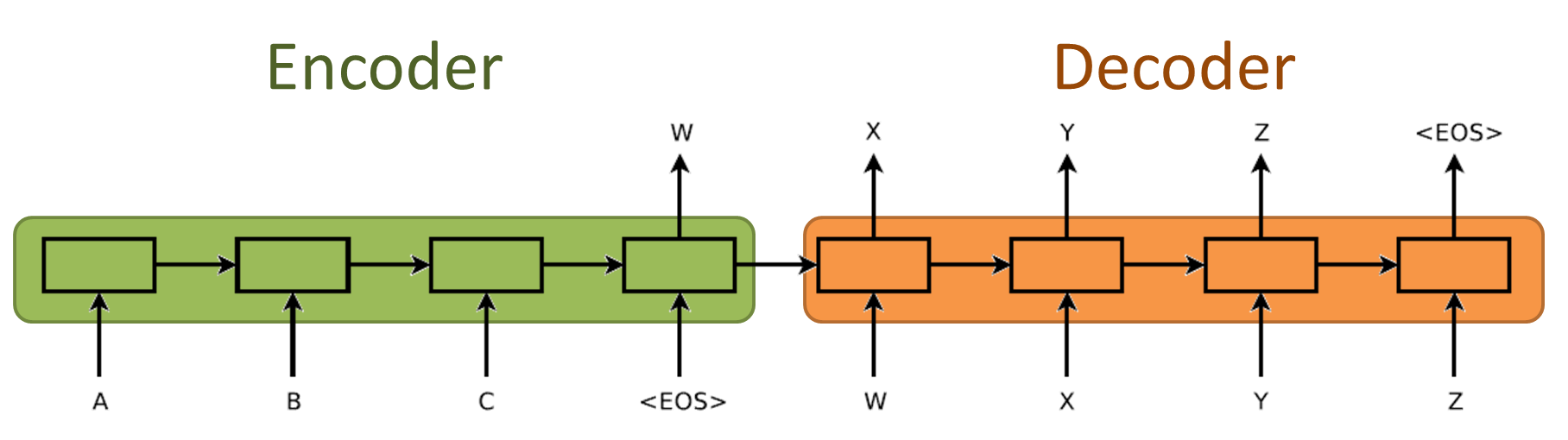
基本上拓展一下,對圖或影像做 Encode,而 Decoder 負責解碼出描述的文字。或是語言翻譯,語音辨識,都可以這麼看待。
Reference
- Embedding tf 官網 link
- Sequence to sequence learning link
- Udacity lstm github
- colah lstm