不打算長篇大論, 精簡聊一下 SpinQuant 這篇論文, 來杯咖啡 ☕ 開始吧.
從前面一篇 blog “隨機旋轉的量化魔法: 去去極值走” 我們知道隨機旋轉可以把 outlier 去除, 或甚至旋轉矩陣直接針對 loss 用學的 (本篇 SpinQuant 的作法, 使用 Cayley SGD 去學)
針對一個簡單的線性層 $Y=XW$ (這裡使用右乘), 我們使用一個正交矩陣 $R$ 同時對 input activation $X$ 和 weight $W$ 旋轉, 讓他們同時好量化:
$$\begin{align}
Y &=XW=(XR)(R^TW) \\
&\approx Q(XR)Q(R^TW)
\end{align}$$ 其中 $Q(\cdot)$ 表示量化 op. 對照參考下圖應該不難理解
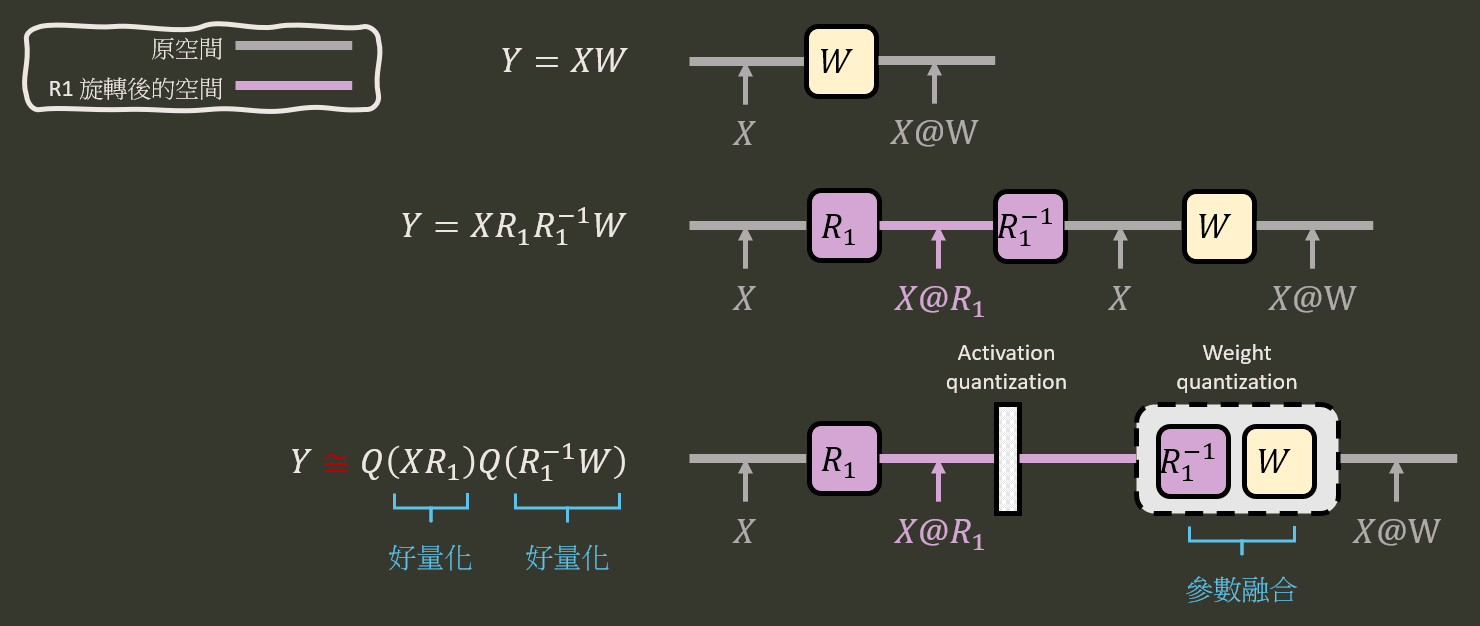 那麼接著來看看 SpinQuant 全架構的旋轉量化圖
那麼接著來看看 SpinQuant 全架構的旋轉量化圖