這篇文章實作了官網的 同步式 data Parallelism 方法 ref,並且與原本只用一張GPU做個比較。實驗只使用兩張卡,多張卡方法一樣。主要架構如下圖 by TF 官網:
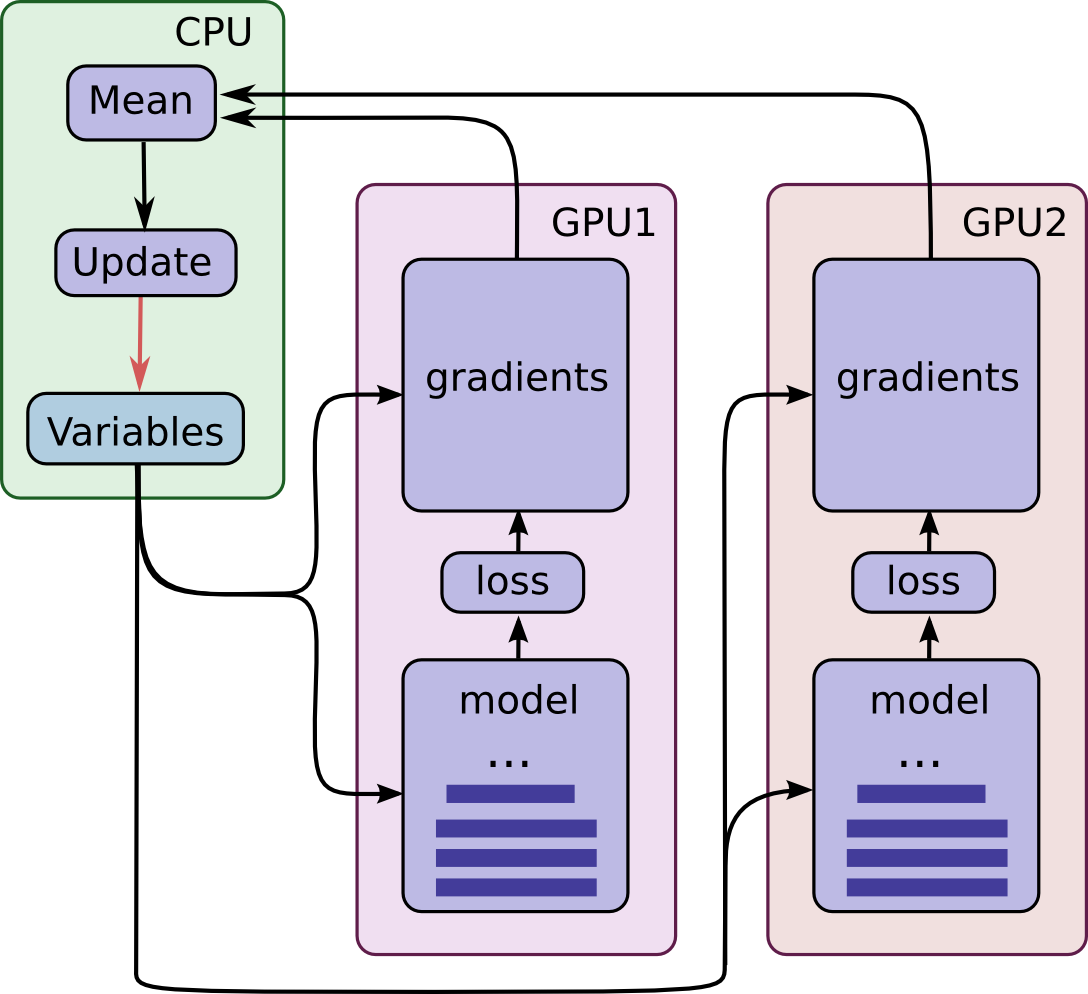
兩張卡等於是把一次要計算的 mini-batch 拆成兩半給兩個 (相同的) models 去並行計算 gradients,然後再交由 cpu 統一更新 model。詳細請自行參考官網。下面直接秀 Codes 和結果。
Machine Spec.
GPU 卡為 Tesla K40c
CPU 為 Intel(R) Xeon(R) CPU E5-2680 v3 @ 2.50GHz
單 GPU 跑 MNIST
直接上 Codes
|
|
同步式 data Parallelism 在兩張 GPU 跑 MNIST
一樣直接上 Codes
|
|
幾個注意處:
- 記得建立 variables (tf.get_variable) 時要使用
with tf.device('/cpu:0'):確保變量是存在 cpu 內 可以跑一小段 code:
12with tf.Session(config=tf.ConfigProto(log_device_placement=True)) as sess:sess.run(tf.global_variables_initializer())來觀察變量是否正確放在 cpu 上。
- 延續 2. 若使用 jupyter notebook 可以這樣做
jupyter notebook > outputlog,執行完 2. 的 code 接著cat outputlog | grep 'cpu'觀察變量是否存在。 - 使用
collections(如下) 來確認變數有正確分享 (養成好習慣)123trainable_collection = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES)global_collection = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES)print('Without Scope: len(trainable_collection)={}; len(global_collection)={}'.format(len(trainable_collection),len(global_collection)))
Benchmark Results
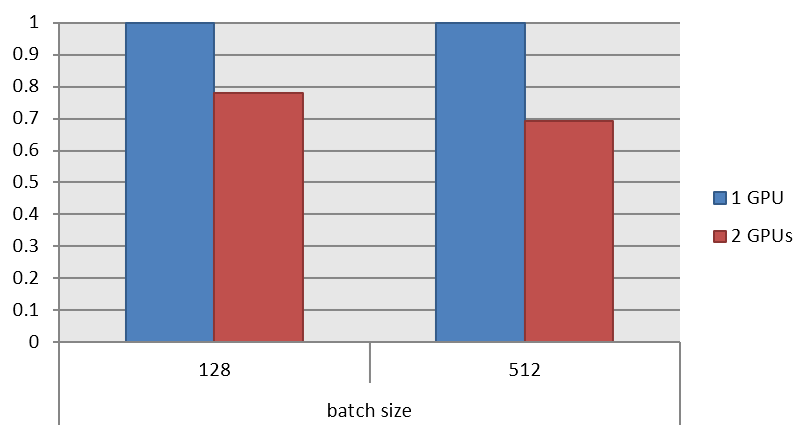
batch size = 128 時,使用兩張 GPU 花的時間為一張的 0.78 倍。而 batch size = 512 時的效果更明顯,為 0.69 倍。
一點小結論
這種同步的架構適合在 batch size 大的時候,效果會更明顯。實驗起來兩張卡在 512 batch size 花的時間在一張卡的 0.7 倍。
不過相比使用兩張卡,一張卡其實有一點優勢是在變量全部放在 GPU 上,因此省去了 CPU <–> GPU 的傳輸代價。這也是主要只到 0.7 倍,而沒有接近 0.5 倍的關鍵原因。