這篇介紹 computational graph (計算圖譜), 主要來源參考自李宏毅教授的課程內容. 並且我們使用 tensorflow 的求導函數 tf.gradients 來驗證 computational graph. 最後我們在 MNIST 上驗證整個 DNN/CNN 的 backpropagation 可以利用 computational graph 的計算方式訓練.
Computational Graph
主要就截圖李教授的投影片, 一個 computational graph 的 node 和 edge 可以定義如下

對於 chain rule 的話, 我們的計算圖譜可以這麼畫
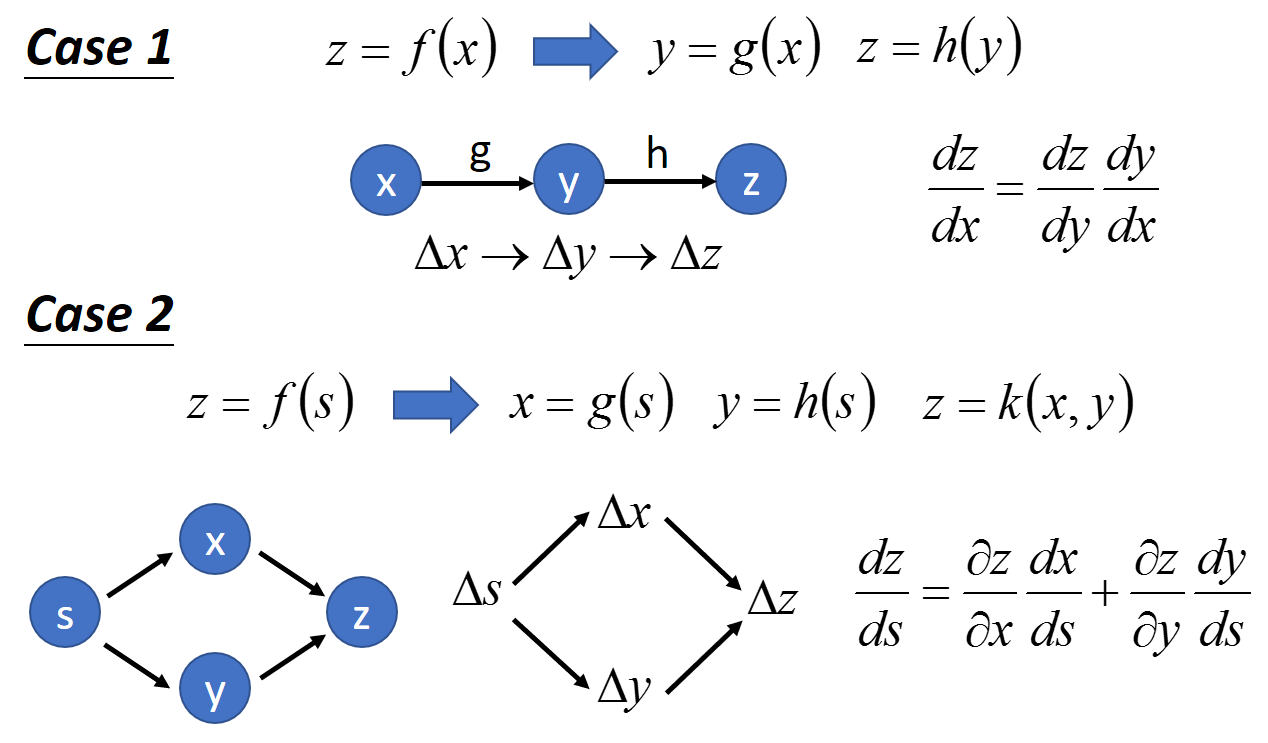
其實就是 chain rule 用這樣的圖形表示. 比較要注意的就是 case 2 的情況, 由於 $x$ and $y$ 都會被 $s$ 影響, 因此計算 gradients 時要累加兩條路徑.
再來另一項要注意的是如果有 share variables 我們的計算圖譜該怎麼表示呢 ? 舉例來說如下的函式
$y=x\cdot e^{x^2}$
計算圖譜畫出來長這樣
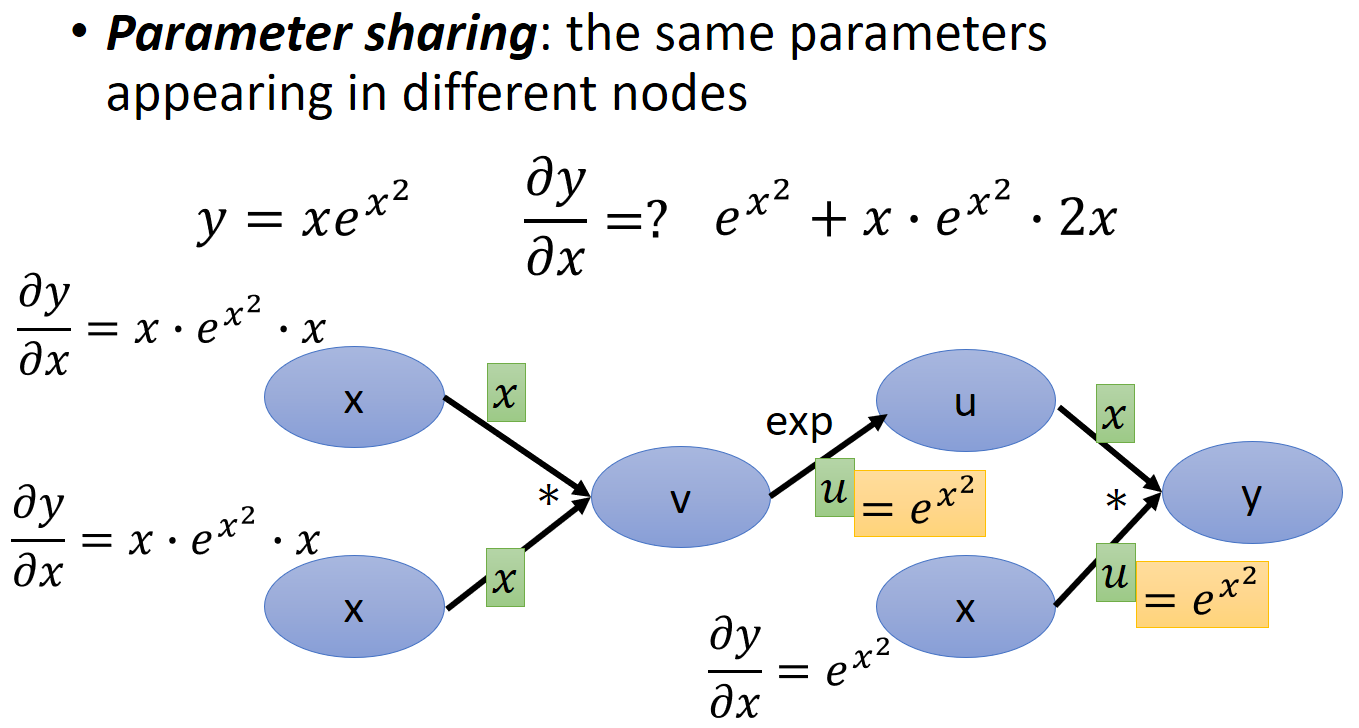
簡單來說把相同變數的 nodes 上所有的路徑都相加起來. 上面的範例就是計算 $\frac{\partial y}{\partial x}$ 時, 有三條路徑是從 node $x$ 出發最終會影響到 node $y$ 的, 讀者應該可以很容易看出來.
另外如果分別計算這三條路徑, 其實很多 edges 的求導結果會重複, 因此從 $x$ 出發計算到 $y$ 會很沒有效率, 所以反過來 (Reverse mode) 從 root ($y$) 出發, 反向找出要求的 nodes ($x$) 就可以避免很多重複運算.
Verify with Tensorflow
考慮以下範例, 其中 $<,>$ 表示內積, $a$, $b$, 和 $1$ 都是屬於 $R^3$ 的向量. 它的計算圖譜如下:
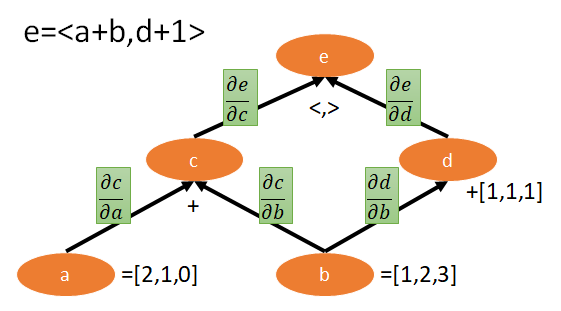
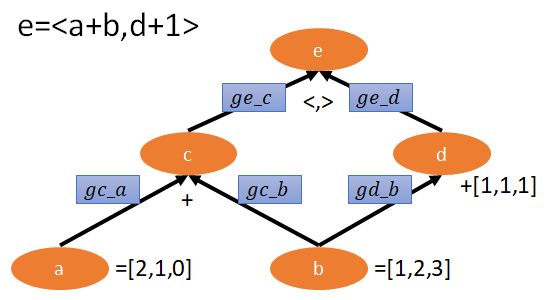
在 Tensorflow 中, tf.gradients 可以幫助計算 gradients. 舉例來說如果我們要計算 $\frac{\partial e}{\partial c}$, 我們只要這樣呼叫即可 ge_c=tf.gradients(ys=e,xs=c). 為了方便, 我們將 $\frac{\partial y}{\partial x}$ 在程式裡命名為 gy_x.
下面這段 codes 計算出上圖 5 個 edges 的 gradients:
|
|
計算結果為
|
|
可以自己手算驗證一下, 結果當然是對的 (使用 Jacobian matrix 計算)
所以我們如果要得到 $\frac{\partial e}{\partial b}$, 我們只要算 ge_c*gc_b + ge_d*gd_b 就可以了. 不過這樣自己把相同路徑做相乘,不同路徑做相加, 太麻煩了! 其實有更好的方法.
對於同一條路徑做相乘, tf.gradients 有一個 arguments 是 grad_ys 就可以很容易做到.
tf.gradients(ys=,xs=,grad_ys=)
以下圖來說明
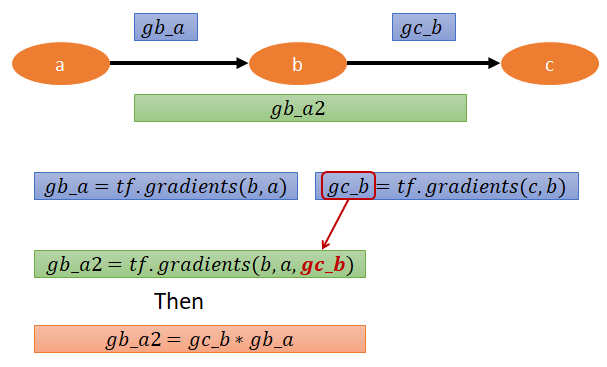
但事實上根本也不用這麼麻煩, 除非是遇到很特殊的狀況, 否則我們直接呼叫 tf.gradients(c,a), tensorflow 就會直接幫我們把同樣路徑的 gradients 做相乘, 不同路徑的 gradients 結果做相加了! 所以上面就直接呼叫 tf.gradients(c,a) 其實也就等於 gb_a2 了.
最後回到開始的 e=<a+b,b+1> 的範例, 如果要計算 $\frac{\partial e}{\partial b}$, 照原本提供的 codes 需要計算三條路徑各自相乘後再相加, 其實只要直接呼叫 ge_b=tf.gradients(e,b) 就完成這件事了 (ge_c*gc_b + ge_d*gd_b)
MNIST 用計算圖譜計算 back propagation
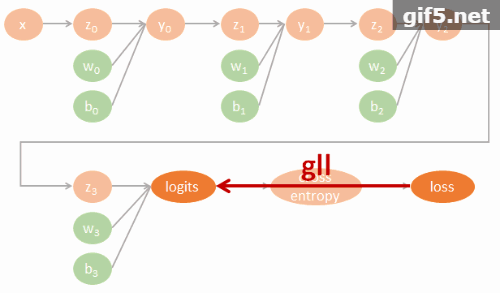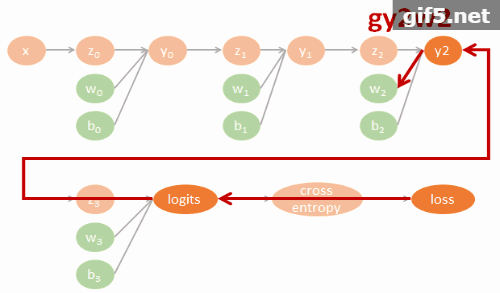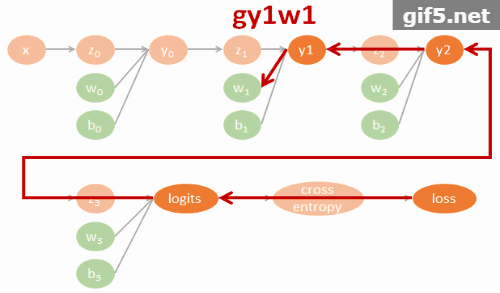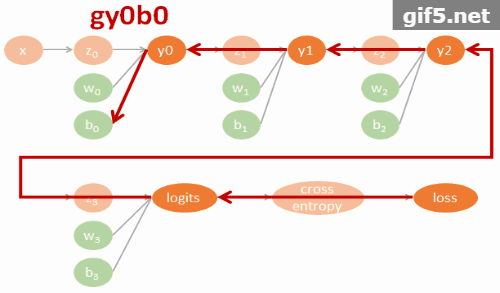
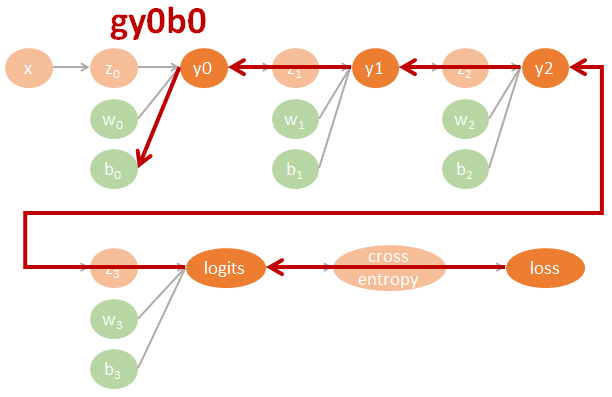
DNN 的計算圖譜
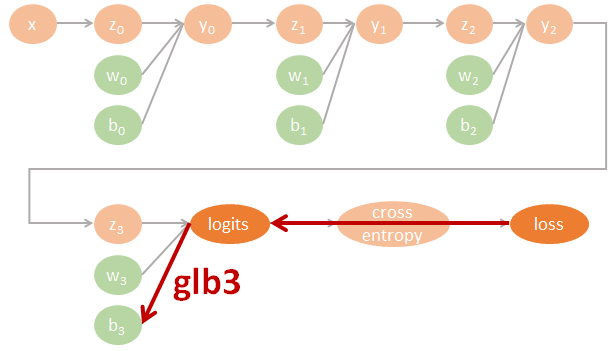
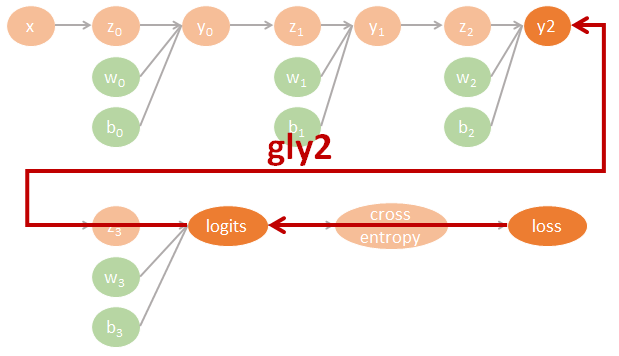
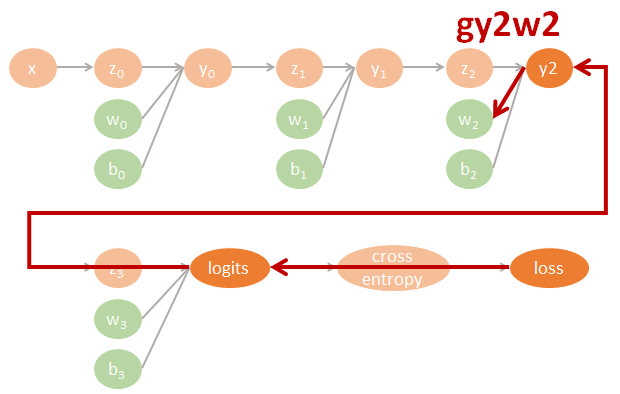
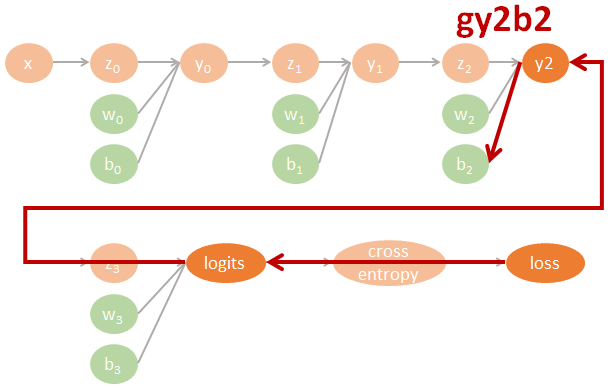
為了清楚了解 Neural network 的 backpropagation 如何用 computational graph 來計算 gradients 並進而 update 參數, 我們不使用 tf.optimizer 幫我們自動計算. 一個 3 layers fo MLP-DNN 的計算圖譜我們可以這樣表示:
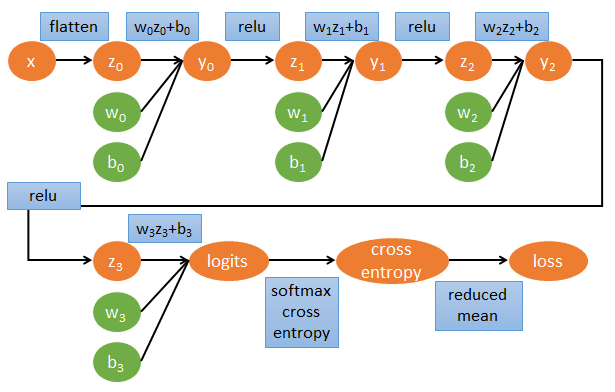
圖裡的參數直接對應了程式碼裡的命名, 因此可以很方便對照. 其中 tensorflow 裡參數的名字跟數學上的對應如下:
$$\begin{align} gll=\frac{\partial \mbox{loss}}{\partial \mbox{logits}} \\ gly2=\frac{\partial \mbox{logits}}{\partial y2}gll \\ gy2y1=\frac{\partial y2}{\partial y1}gly2 \\ gy1y0=\frac{\partial y1}{\partial y0}gy2y1 \\ (glw3,glb3)=(\frac{\partial \mbox{logits}}{\partial w3}gll,\frac{\partial \mbox{logits}}{\partial b3}gll) \\ (gy2w2,gy2b2)=(\frac{\partial y2}{\partial w2}gly2,\frac{\partial y2}{\partial b2}gly2) \\ (gy1w1,gy1b1)=(\frac{\partial y1}{\partial w1}gy2y1,\frac{\partial y1}{\partial b1}gy2y1) \\ (gy0w0,gy0b0)=(\frac{\partial y0}{\partial w0}gy1y0,\frac{\partial y0}{\partial b0}gy1y0) \end{align}$$相對應的 tensorflow 代碼如下:
用圖來表示為:
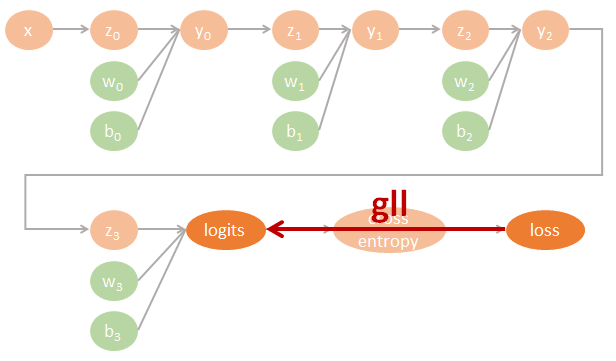
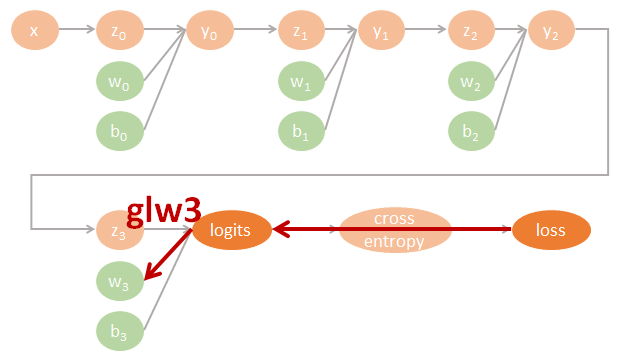
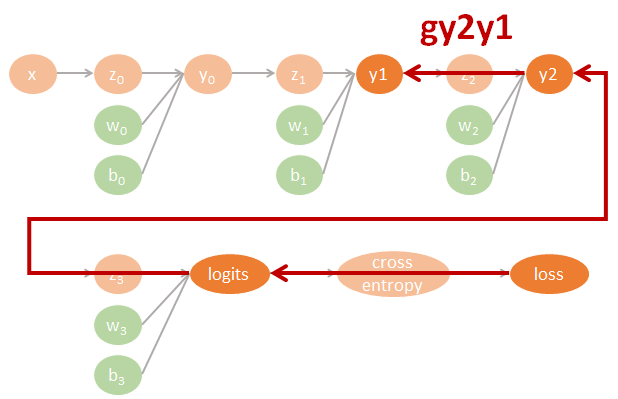
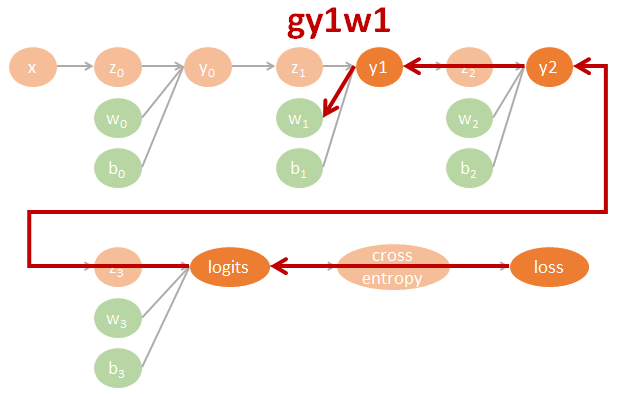
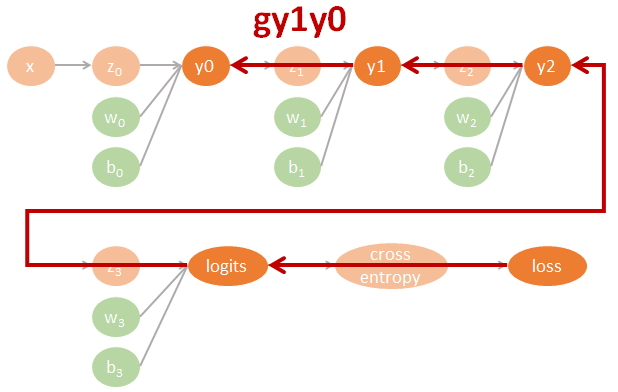
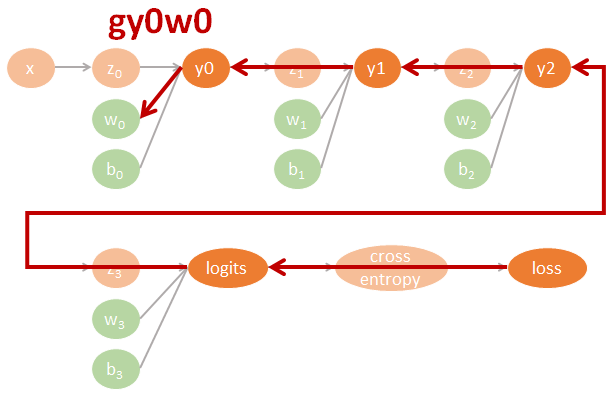
Tensorflow 程式碼
用上面一段的方式計算出所需參數的 gradients 後, update 使用最單純的 steepest descent, 這部分程式碼如下
|
|
完整程式碼如下
|
|
訓練結果如下:
|
|
這速度果然明顯比用 Adam 慢很多, 但至少說明了我們的確使用 Computational graph 的計算方式完成了 back propagation!
結論
Tensorflow 使用計算圖譜的框架來計算函數的 gradients, 一旦這樣做, 神經網路的 backprop 很自然了. 事實上, 所有流行的框架都這麼做, 就連 Kaldi 原先在 nnet2 不是, 但到 nnet3 也改用計算圖譜來實作.