Udacity SDC term 3 第二個 Project 做的是使用 Deep Learning 學習識別 pixel 等級的路面區域. 簡單講就是有如下的 ground truth data, 標示出哪邊是正確的路面, 然後用 Fully Convolutional Network 去對每個 pixel 做識別.


Fully-Convolutional-Network (FCN)
主要是實作這篇論文 “Fully Convolutional Networks for Semantic Segmentation“
換言之, 全部都是 convolution layers, 包含使用 1x1 convolution 替換掉原來 Convnet 的 fully-connected-layer, 和使用 deconvolution 做 upsampling. 架構圖如下:
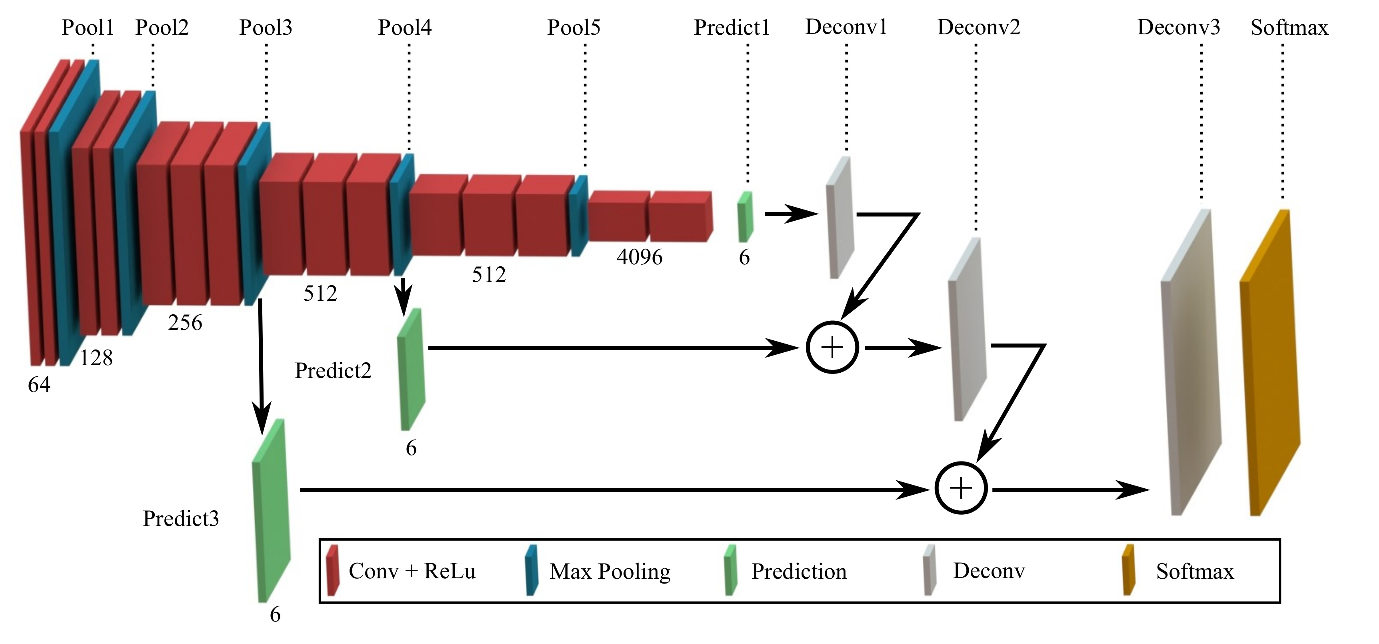
分成 Encoder 和 Decoder 部分. Encoder 使用 pre-trained 好的 VGG16 network, 負責做特徵抽取. 抽取出來的特徵後, 接上 deconvolution layers (需訓練) 搭建而成的 decoder part. 有一個特別之處是使用了 skip 方法. 這個方法是在 decoder 做 upsampling 時, 會加上當初相對應大小的 Encoder layer 資訊. 這樣做論文裡提到會增加整個識別效果.
Results
效果有點讓我小驚豔, 因為只使用少少的 289 張圖片去訓練而已. 跑出來的測試結果如下:






另外還有一點是縱使已經有 dropout 了, 如果沒有加上 l2 regularization 的話, 會 train 不好! (l2 regularization 真讓我第一次看到有這麼重要), 同樣設定下, 有和沒有 l2 regularization 的差別:
