這篇是個小練習, 就兩點:
- 了解什麼是 deconvolution, 並在 tensorflow 中怎麼用
- 實作一個 CNN AutoEncoder, Encoder 用
conv2d, Decoder 用conv2d_transpose
What is deconvolution?
破題: Deconvolution 的操作就是 kernel tranpose 後的 convolution. 使用李宏毅老師的上課內容, 如下圖:
![]()
其實圖已經十分明確了, 因此不多解釋.
另外在 tensorflow 中, 假設我們的 kernel $W$ 為 W.shape = (img_h, img_w, dim1, dim2). 則 tf.nn.conv2d(in_tensor,W,stride,padding) 會將 (dim1,dim2) 看成 (in_dim, out_dim). 而 tf.nn.conv2d_transpose(in_tensor,W,output_shape,stride) 會將 (dim1,dim2) 看成 (out_dim, in_dim), 注意是反過來的. 有兩點多做說明:
tf.nn.conv2d_transpose會自動對 $W$ 做 transpose 之後再 convolution, 因此我們不需要自己做 transpose.tf.nn.conv2d_transpose需要額外指定output_shape.
更多 conv/transpose_conv/dilated_conv with stride/padding 有個 非常棒的可視化 結果參考此 github
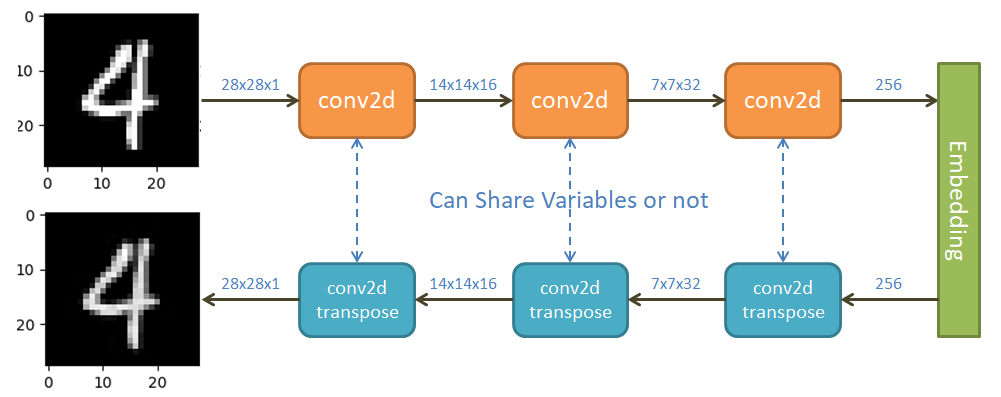
CNN AutoEncoder
結構如下圖
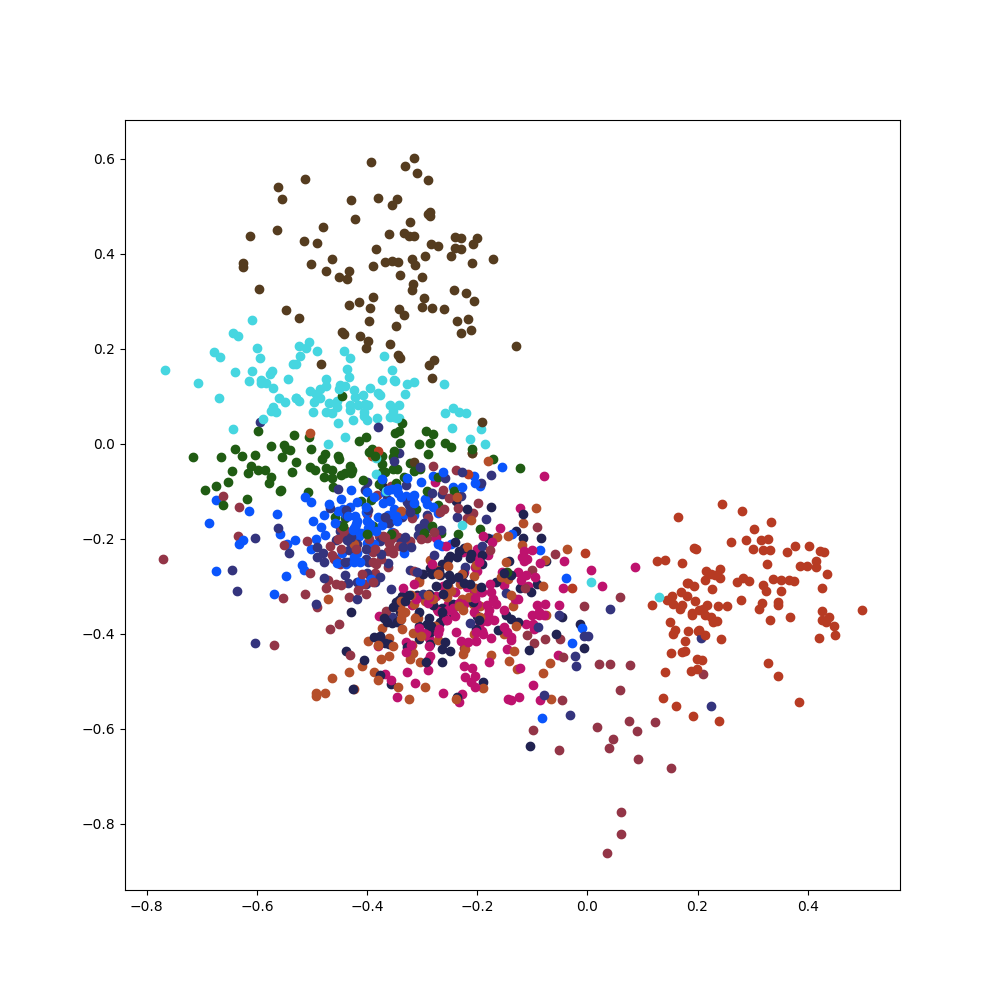
直接將 embedding 壓到 2 維, 每個類別的分布情形如下:
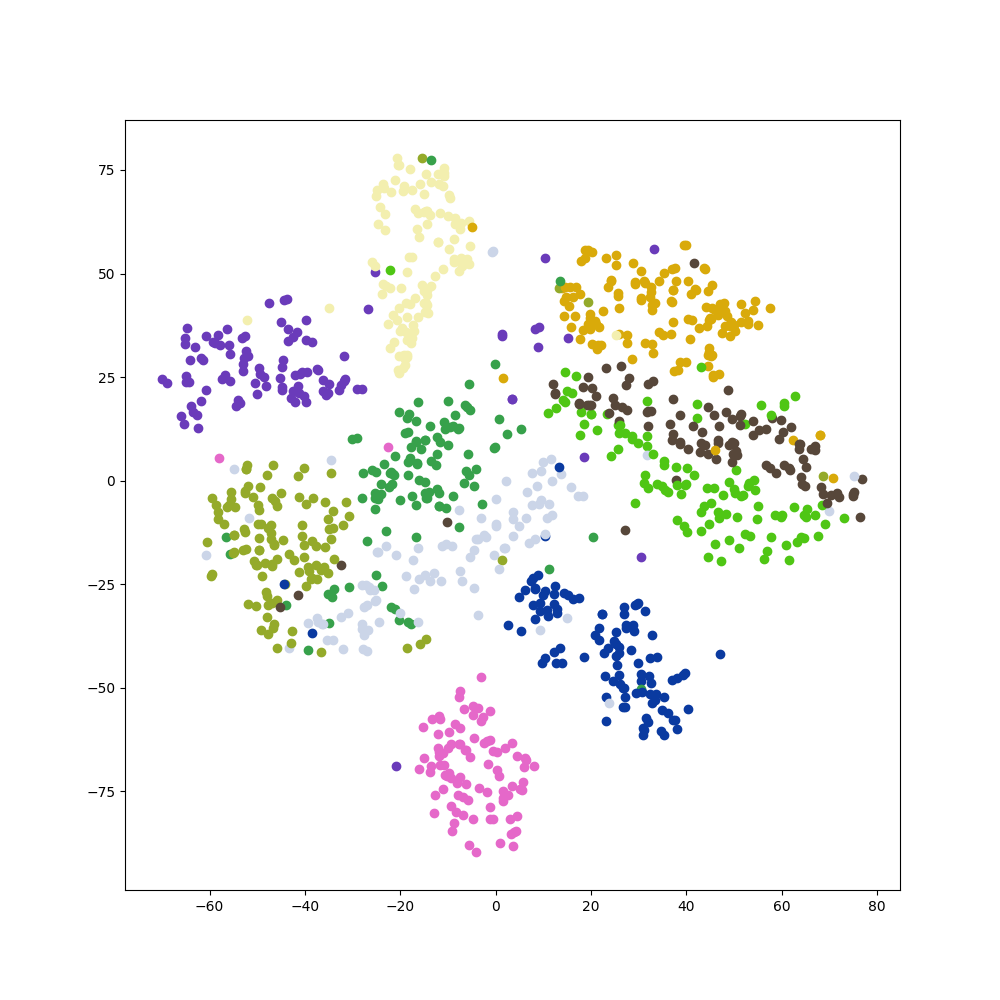
embedding 是 128 維, 並使用 tSNE 投影到 2 維畫圖如下:
Encoder 如下:
|
|
Decoder 如下:
|
|
AutoEncoder 串起來很容易:
|
|
完整 source codes 參考下面 reference
Reference
- 李宏毅 deconvolution 解釋
- tf.nn.conv2d_transpose 說明
- conv/transpose_conv/dilated_conv with stride/padding 可視化: github
- 本篇完整 source codes