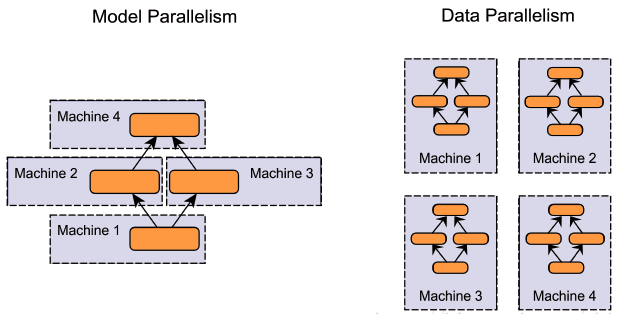
訓練時候的平行化可分為:
- Model Parallel: 所有 GPUs 跑同一個 batch 但是各自跑模型不同部分
- Data Parallel: GPUs 跑不同的 batches, 但跑同一個完整的模型
由於 Data Parallel 跑同一個完整模型且各 GPU 都用自己複製的一份, 在 update 參數時要如何確保更新一致? 可分為 synchronous 和 asynchronous update. (文章後面會詳細討論)
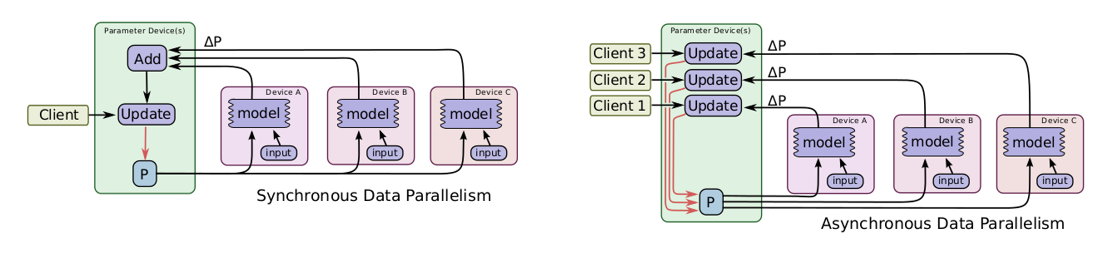
本文討論 Data Parallel with Synchronous update.
既然要做 data parallel, 第一件事情便是如何對不同 GPU 分派不同的 batches, 接下來我們就使用 PyTorch 做這件事.
指派不同 Batch 給不同 GPU
直接上一個 toy example (minimal_distributed_data_example.py)
|
|
[Line 23~27 有關 Dataset/DataLoader]
- Line 24
dataset只是一個 0 到 23 的 int list. - Line 27
DataLoader在分配 batches 給不同 GPUs 時只需要將 sampler 使用DistributedSampler創建就可以.DistributedSampler在分配一個 batch 除了會指定資料是那些 index 之外, 還會指定該筆 batch 是要分到哪個 gpu.
[Line 14~22 有關 Distributed Settings]
在執行這個檔案的時候, 我們會使用 torch.distributed.launch, 範例指令如下:
|
|
此時 PyTorch 會開啟兩個 processes 去執行你的 .py, 這裡注意不是 threads, 這是因為 python Global Interpreter Lock (GIL) 的原因, 使用 thread 效率會不高.
另外使用 --use_env 則會在各自的 process 裡設定環境變數:
WORLD_SIZE(範例 = 2)LOCAL_RANK(範例 = 0 or 1)
因此 line 17 我們便可藉由 world_size 得知是否為 distributed 環境. 是的話 line 20 就可以拿到這個 process 的 local_rank (可以想成是 worker 的編號, 也就是第幾個平行的單位), 接著 line 21, 22 就可以根據 local_rank 設置 gpu.
[Line 28~36 有關 go through all data]
在執行時, 各個 process 會拿到相對應個 batches. Line 35 模擬處理該筆資料所花的時間. Line 36 為確認自己這個 process 總共拿到那些 batches. 以範例來說, 兩個 gpus 應該要拿到 exclusive 的兩個 sets 其聯集是 {0,1, …, 23}. 結果如下:
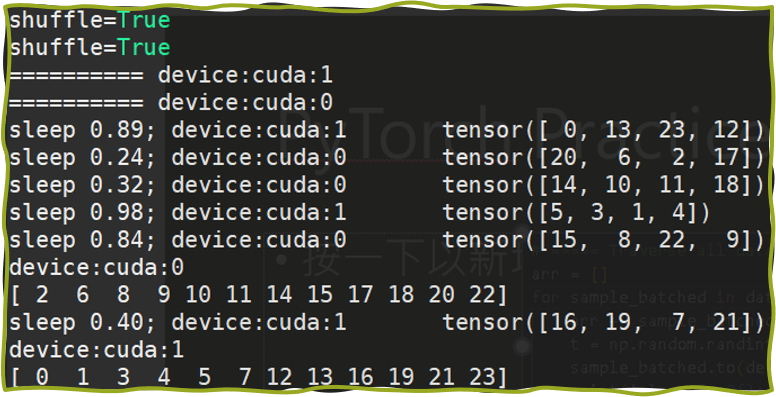
Good Job! 現在我們會把每個 GPU 都分配不同的 batches 了, 不過還有一個關鍵的問題: 該怎麼各自計算 gradients 然後 update?
這就開始討論 update 的兩種 case, synchronous and asynchronous update.
Asynchronous Update
- Synchronous: 每一次模型 update 要等到所有 device 的 batch 都結束, 統合後 update
- Asynchronous: 每個 device 算完自己的 batch 後即可直接 update
可以想像非同步的化可以更新的比較有效率, 但可能效果會不如同步的方式.
Asynchronous 會遇到的狀況是算完 gradient 後要 update parameters 時, parameters 已經被其他 process update 過了, 那為什麼還可以 work?
Asynchronous 狀況 1
範例假設兩個 GPU (1&2) 其參數空間都在 $\theta_a$.
Step 1. 假設 GPU2 先算完 $\Delta P_2(\theta_a)$ 並且 update 到 $\theta_b$:
$$\begin{align} \theta_b = \theta_a + \Delta P_2(\theta_a) \end{align}$$Step2. 這時候 GPU1 算完 gradient 了, 由於當時算 gradient 是基於 $\theta_a$, 因此 gradient 為 $\Delta P_1(\theta_a)$, 但是要 update 的時候由於已經被 GPU2 更新到 $\theta_b$ 了, 所以會更新到 $\theta_c$:
$$\begin{align} \theta_c = \theta_b + \Delta P_1(\theta_a) \end{align}$$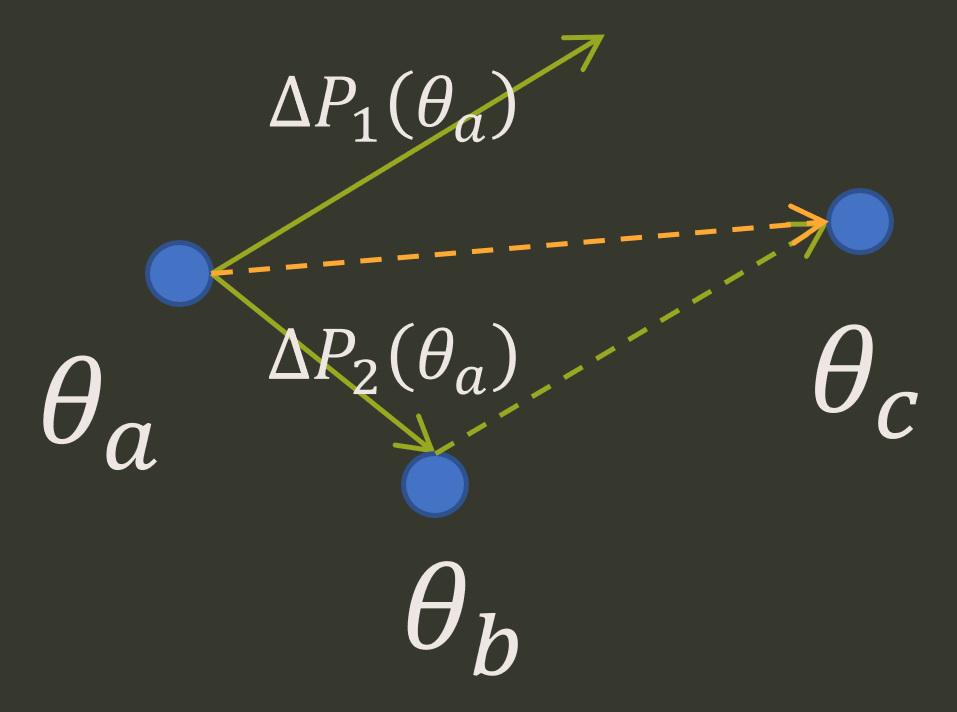
這裡讀者可能會疑問, 計算 gradient 與 update 時根據的參數是不同, 這樣 update 會不會出問題? 以上面這個例子來說, 還剛好沒事. 原因是其實等同於 synchronous update:
$$\begin{align} \theta_c = \theta_a + \left[ \Delta P_2(\theta_a) + \Delta P_1(\theta_a) \right] \end{align}$$那可能會繼續問, 這只是剛好, 如果一個 GPU 比另一個慢很多, 會怎樣? 我們看看 case 2
Asynchronous 狀況 2
GPU2 太快了… 已經 update 好幾輪

好吧… 想成類似有 momentum 效果吧
實務上會在幾次的 update 過後強制 synchronize update 一次, 可以想像如果一些條件成立 (譬如 gradients 是 bounded), 應該能保證收斂 (這邊我沒做功課阿, 純粹猜測)
Synchronous Update
每個 gpu 都算完各自 batch 的 gradients 後, 統一整理 update parameters, 常見兩種方式:
Parameter Server

Ring Allreduce
接著介紹的這兩種方法圖片主要從 Baidu: Bringing HPC techniques to deep learning [Andrew Gibiansky] 筆記下來.
Parameter Server 的 Synchronous Update
一次 Update 分兩步驟
- GPU 0 全部都拿到 GPU 1~4 的 Gradients 後, 更新 parameters
- GPU 0 把 model 發送給 GPU 1~4
假設有 $N$ 個 GPU, 通信一次花費時間 $K$, 則 PS 方法成本為:
- Gradients passing: $(N-1)K$
- Model passing: $(N-1)K$
Total $2K(\color{orange}{N}-1)$, 跟 GPU 數量正比
Ring Allreduce 比較多圖, 特別拉出一個 section 說明
Ring Allreduce 的 Synchronous Update
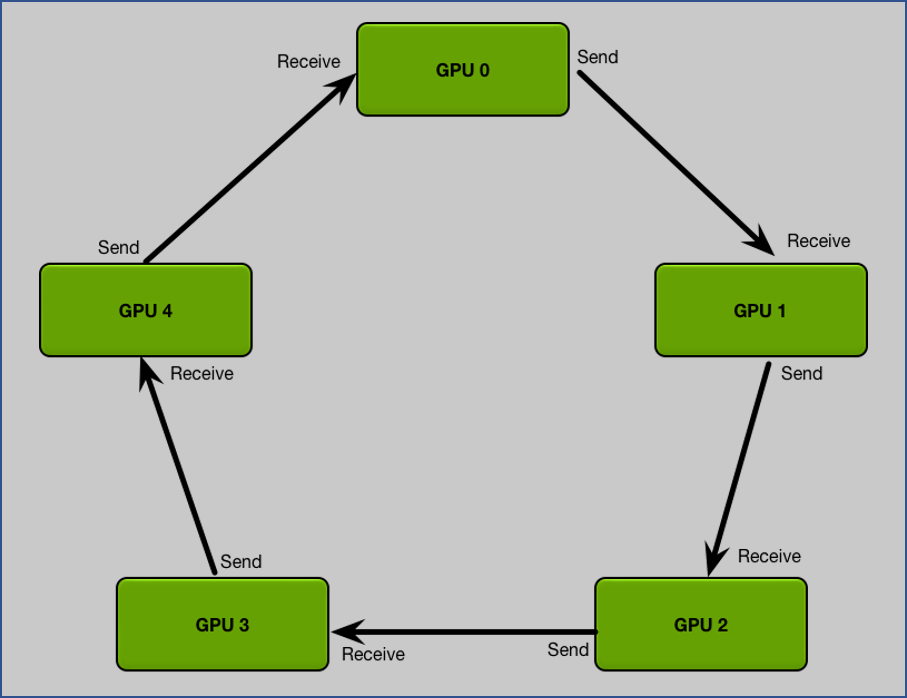
每一個 GPU 都分別有一個傳送和接收的對象 GPU, 分配起來正好形成一個環. 假設每個 GPUs 都算好 gradients 了, 並且我們將 gradients 分成跟 GPU 數量一樣的 $N$ 個 chunks:
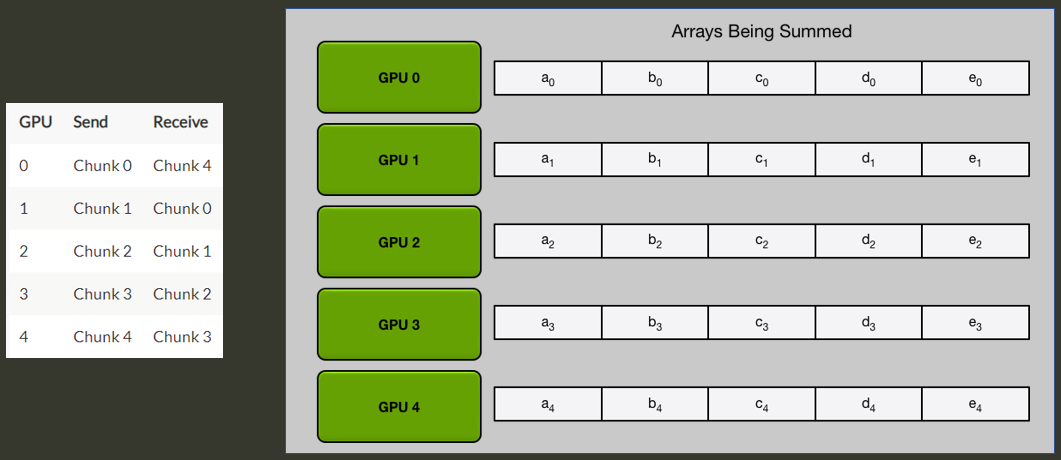
這方法分兩步驟:
- Scatter Reduce
- All Gather
1. Scatter Reduce
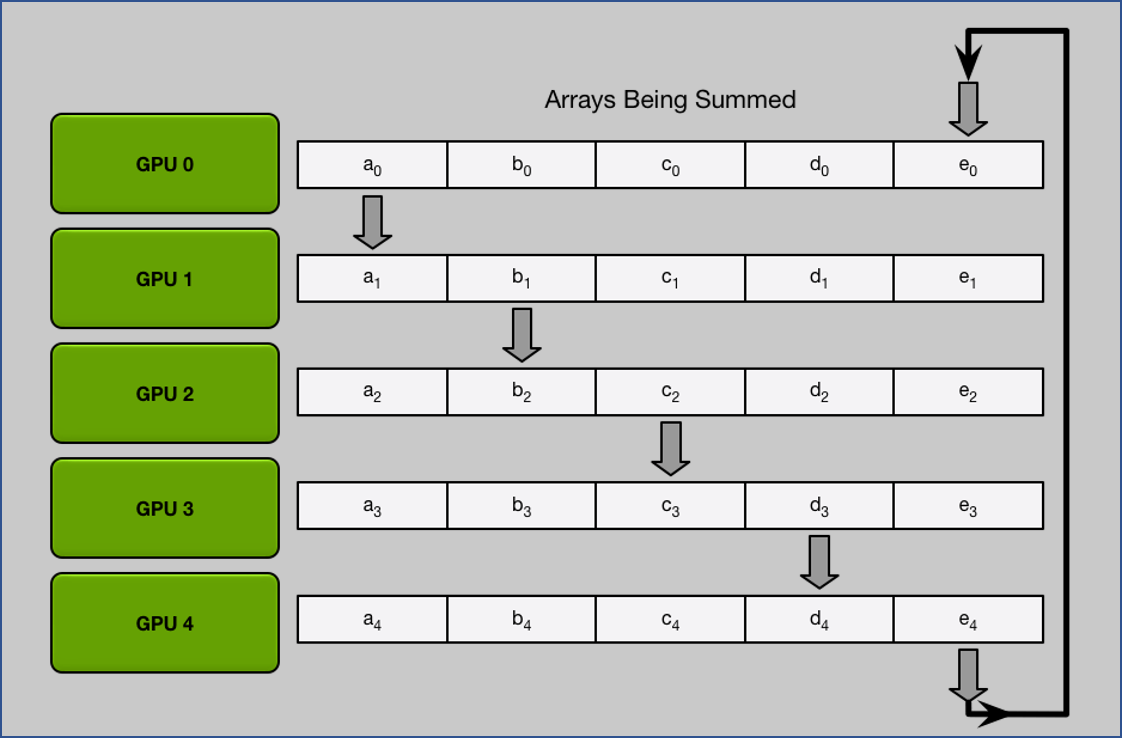

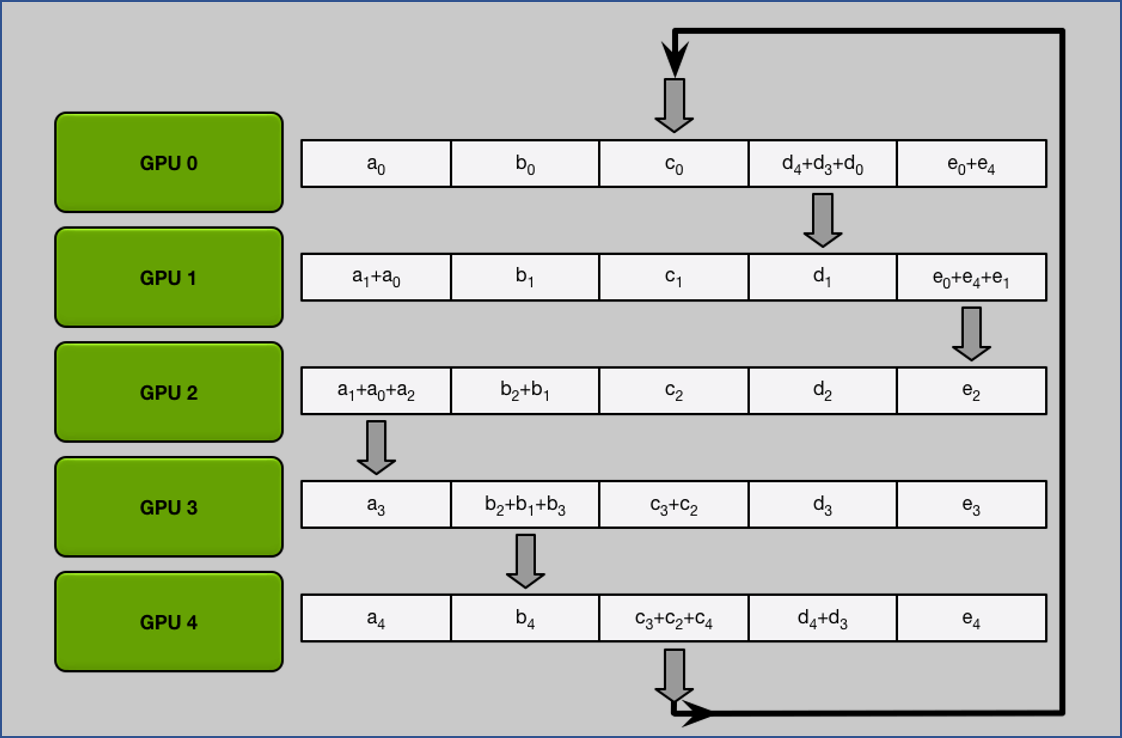
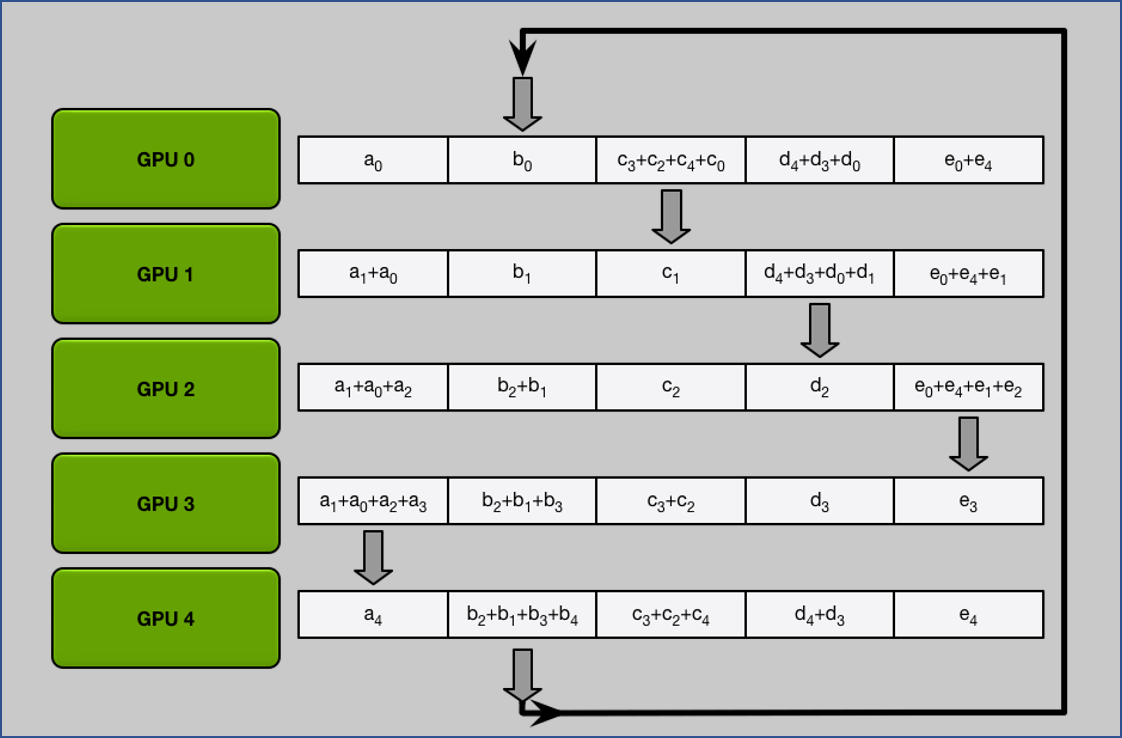

做完 $N-1$ 次 iteration 後可以發現每張 GPU 都會有一個是完整的 chunk.
2. All Gather

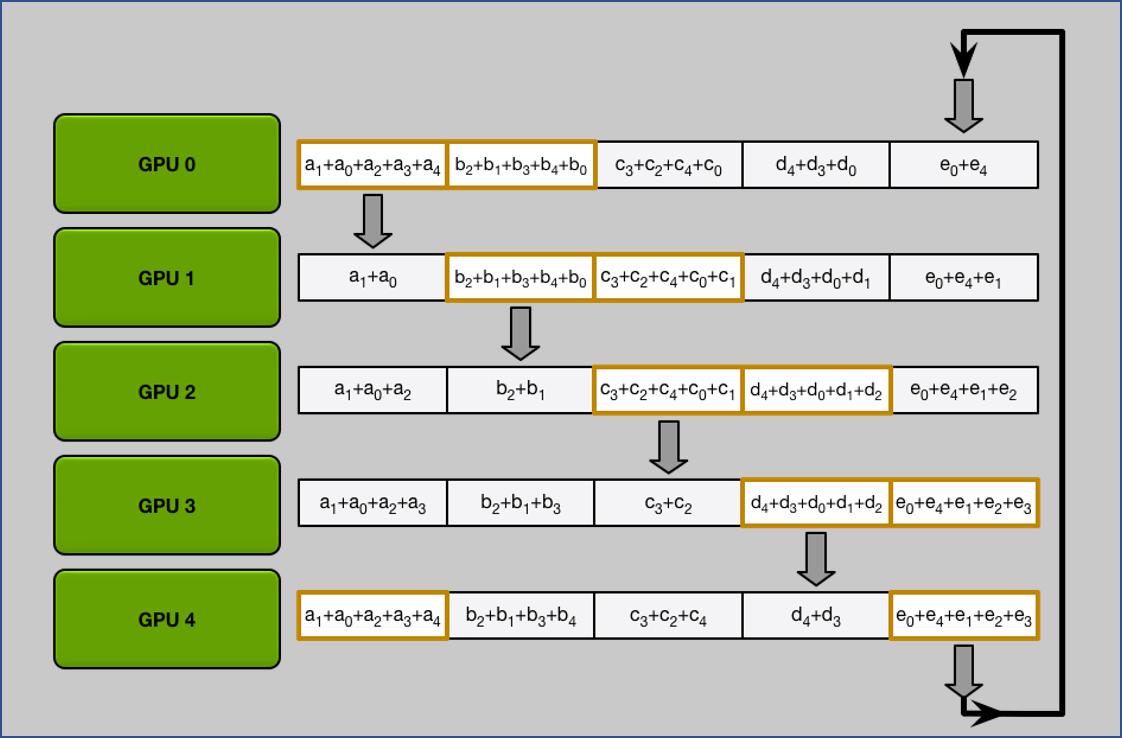
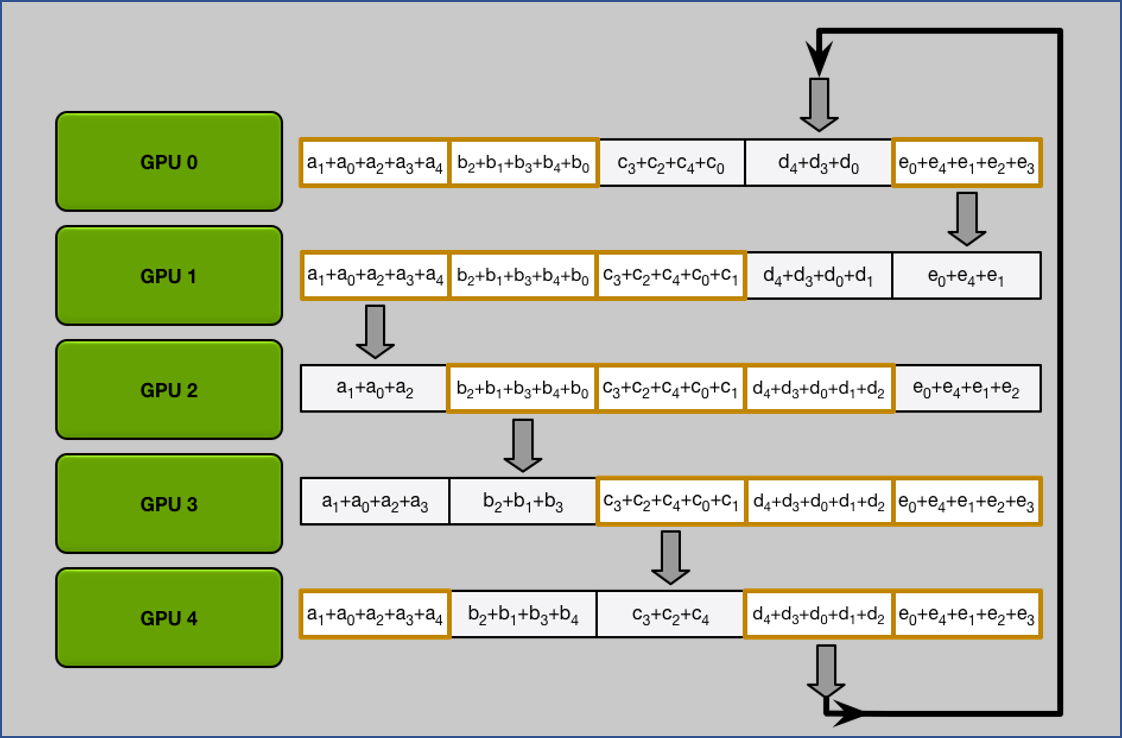
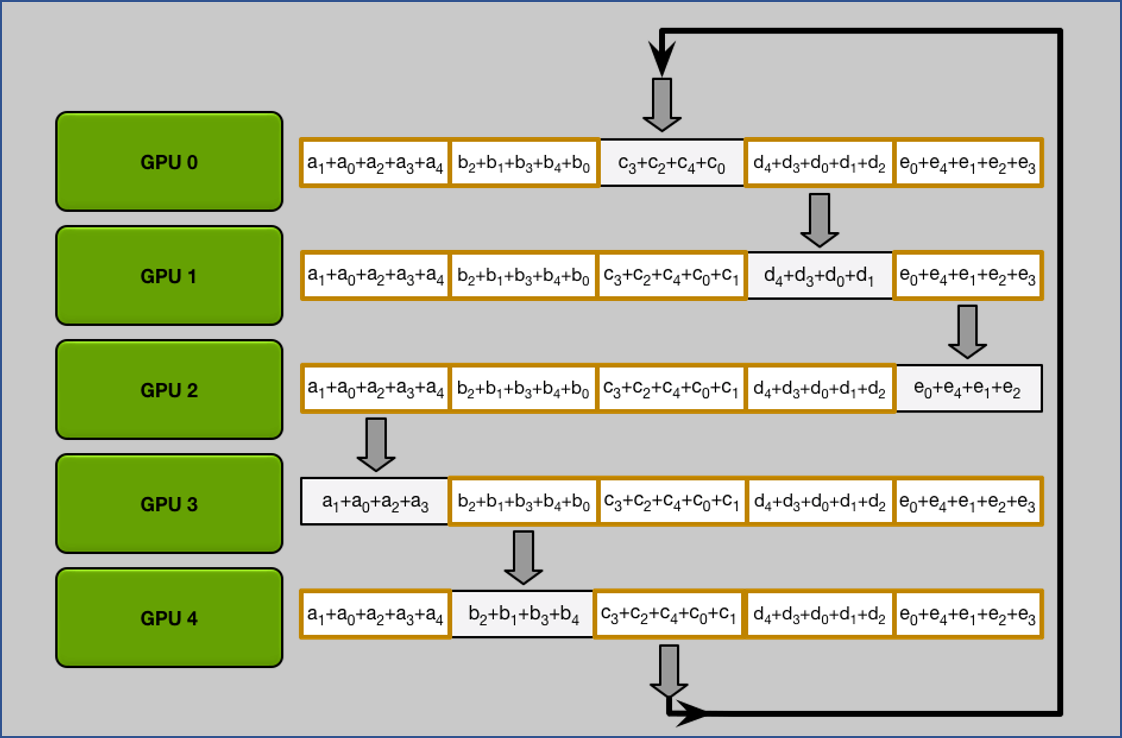
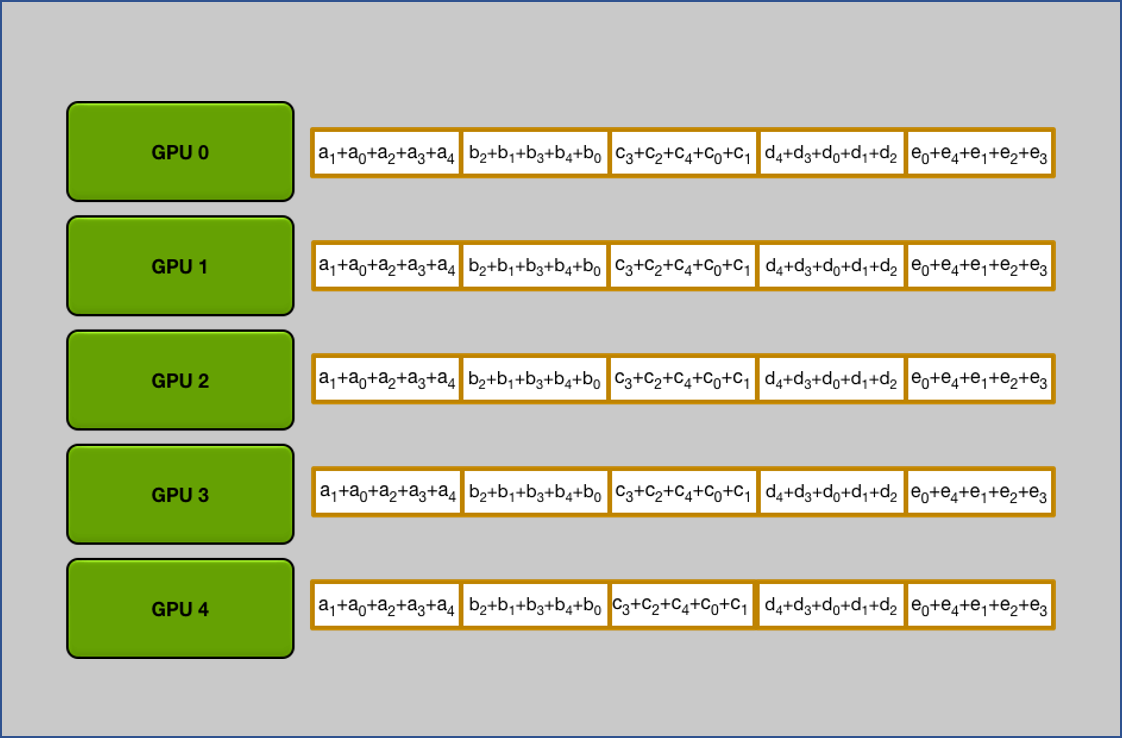
做完 $N-1$ 次 iteration 後可以發現每張 GPU 都拿到所有完整的 chunk.
All Gather 流程跟 Scatter Reduce 是一樣, 只是將累加行為變成取代而已.
成本
每個 GPUs 都得到統合後的 gradients, 因此 各個 GPU 上的 model 可以各自 update (gradients 相同, 所以 update 後的 models 也相同)
假設有 $N$ 個 GPU,則成本為:
- 通信一次花費時間 $K/N$ (因為我們分成 $N$ 個 chunks 同時傳輸)
- Scatter reduce: $(N-1)K/N$
- All gather: $(N-1)K/N$
Total $2K(\color{orange}{N}-1)/\color{orange}{N}$, 跟 GPU 數量無關
PyTorch: Model with DDP
還記得最開頭的範例嗎? 我們做到了把每個 GPU 都分配不同的 batches, 但還不會將各自計算 gradients 統合然後 update.
其實我們只需要針對上面範例的 minimal_distributed_data_example.py 做點修改就可以.
針對 model 作如下改動:
|
|
這樣就使得 model 的 backward() 成為 sync op. 也就是在呼叫 loss.backward() 會等到每張 GPU 的 gradient 都算完且 sync 了 (PS or All Gather 都可以) 才會接下去執行.
注意事項
- 由於每個 process 都有自己的 optimizer(scheduler), 而 momentum 會根據當前的 gradient update, 如何確保每個 optimizers 都相同?
Ans: 由於 .backward() 是 sync op, 因此 opt.step() 時每個 processes 的 gradients 已經同步了, 所以 momentum 會根據相同的 gradient update - Batch-norm 的 statistics 同步?
Ans: See torch.nn.SyncBatchNorm - Save checkpoint 時在一張卡上存就可以 (通常用 LOCAL_RANK=0 的那個 process)
- 怎麼確保每個 process 上的 model random initial 相同的 weights?
Ans:DistributedDataParallel在 init 時就會確保 parameters/buffers sync 過了, see here - model 經過
DistributedDataParallel包過後 name 會多一個前綴module., 如果訓練和加載模型一個使用 DDP 一個沒有load_state_dict有可能會因此出錯, 需自行處理 - 一些 metrics 如 accuracy/loss 由於在各個 GPUs 計算, 可以利用
torch.distributed.all_reduce,torch.distributed.all_gather等來 sync
See DISTRIBUTED COMMUNICATION PACKAGE - TORCH.DISTRIBUTED and Appendix
有一個不錯的 DDP 範例 [2]
如果可以的話, 推薦使用 PyTorch Lightning, 直接幫你把這些繁瑣的細節包好, 告訴它要用幾張 GPUs 就結束了.
Reference
[1] Bringing HPC Techniques to Deep Learning
[2] A good example of DDP in PyTorch
Appendix
使用 torch.distributed.all_reduce 來同步不同 GPU 之間的 statistics
與本文上面的範例 codes 雷同, 主要增加 AvgMetric 當範例說明
|
|
Output 為:

Cheers! 👏