借用 MicroSoft NNI [1] 的分類, NAS 分成:
$\circ$ Multi-trail NAS
$\circ$ One-shot NAS (著重點)
我們著重在每個方法的介紹, 要解決什麼問題, 而實驗結果就不記錄
註: NAS 一直是很活躍的領域, 個人能力有限只能記錄自己的 study 現況
NAS Roadmap 介紹
早期的 NAS 必須先定義 model search space, 然後有個 architecture sampling 方法, 每次 sample 出一個架構從頭開始訓練起, 訓練完才能 evaluate 這個架構的表現. 重複此步驟直到找到最佳表現的架構為止.
這方法光想就知道很花時間, 所以怎麼讓 sample 出的架構高機率是好架構就會是效率的主因之一.
這種方法稱 Multi-trail NAS [1] (借用 NNI 的分類名稱), 如下圖 (圖來源):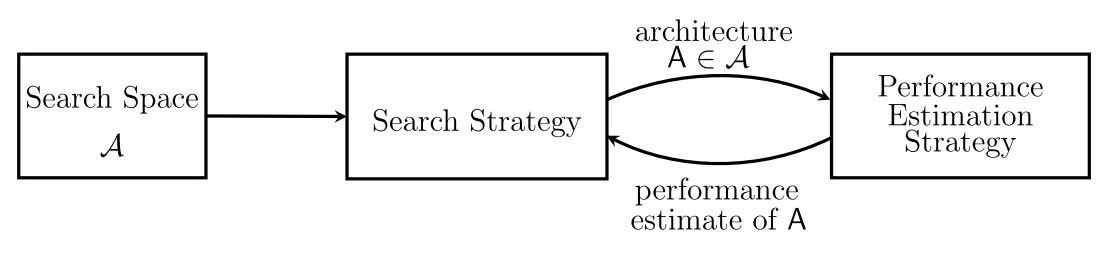
One-shot NAS
而 DARTS [2, 筆記] 這種 gradient-based 方法的出現使得 NAS 的整個速度變得快非常多 (不用每 sample 一個架構都要從頭訓練起), 最核心的想法就是訓練一個 supernet, 這個 supernet 包含所有想要搜尋的 NN subnet. 然後再賦予每條 path 都有一個 learnable 的參數表示選擇這條 path 的機率.
只要對 supernet 的 NN weights 和架構參數 (本文用 $\alpha$ 表示) 一起 jointly 訓練下去. 一次 (one-shot) 就搞定最佳的架構選擇和 NN 的 weights. 所以這方法稱為 One-shot NAS [1].
這個”一起訓練下去”細部講的話並不容易, 主要是因為 weights 訓練時使用 training set, 而架構參數的訓練使用(一部分) validation set, 變成一個 bi-level optimization 問題, 詳見 筆記
下圖中間子圖 (來源 [3]) 可以看到 one-shot NAS 訓練後, 選擇 B1 的架構參數有最高的機率, 因此在採樣要當作佈署的模型時, 高機率採樣出 B1 的架構 (下圖右).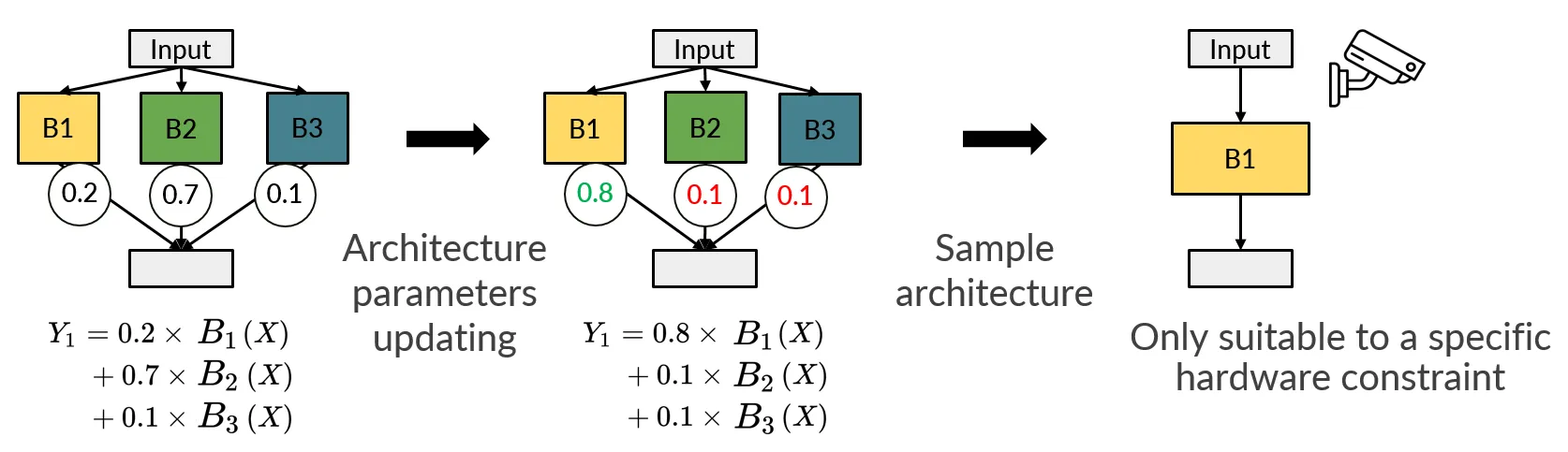
另外一種做法是 Stochastic approach, 也就是訓練過程中會真的根據目前 $\alpha$ 機率採樣出架構來做訓練, 但是”採樣”這個 op 是不可微, 因此必須使用 Gumbel softmax trick [4] 來讓模型可以做 back propagation. 典型的方法為: FBNet(V2) [5] [6], SNAS [7]
但是 DARTS 也不是毫無缺點, 至少有以下三點問題:
- 降低 Supernet Memory 需求:
Supernet 太大, 導致訓練的 memory 變成 bottleneck: Proxyless NAS [8], Single-path NAS [9], 嘗試解決此問題 - Skip Connection 過多導致效果變差:
這會導致架構變得很 shallow, RobustDARTS [10], Fair DARTS [11], DARTS- [12], DARTS+ [13] 嘗試解決此問題 - 拆開 Weight 訓練和架構搜索:
由於 one-shot NAS 讓 weights 和架構參數一起訓練出來, 如果要佈署在不同 devices 上 (有不同 HW constraints), 都要重新訓練 supernet, Once-for-All [14] 和 Single Path One-Shot (SPOS) [15] 嘗試解決此問題
本文接下來的部分主要探討以上這 3 點 DARTS 的改進
另外內文也會提到以下兩點:
- 由於所有的 subnet 的 weights 都是共享的, 但不同架構的 subnet 有可能需要不同的值才能有好效果, Once-for-All 裡面有對 sharing weight 在多做一個 transformation 來增加彈性.
- 訓練和佈署時存在 mismatch, 譬如訓練後每條 path 機率都差不多, 但佈署時硬要選一個就可能會有落差. DARTS 論文的 future work 提到 softmax 可以使用 annealing 控制 temperature 使得愈來愈像 argmax. 另外若使用 Stochastic approach 的話可以考慮用 Hard (Binary) Concrete Distribution [16] 來讓 distribution 純 0 或 1 的值機率變大.
降低 Supernet Memory 需求
Supernet 相當於 search space 中所有 subnet 的聯集, 通常也不會太小, 太小的 supernet search space 就不夠大可能影響 NAS 的效果. 我們知道 NN 需要的 memory 不是只有 weights 而已, 還有 gradients 和 optimizer 的 states 要存. 如下圖 microsoft/DeepSpeed [17] 的論文圖顯示: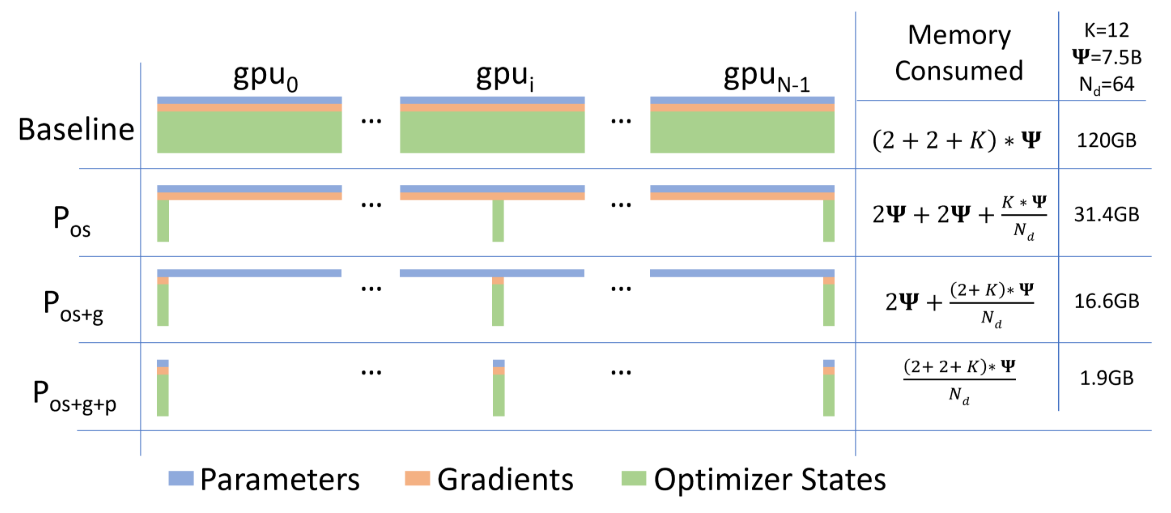 其中 optimizer states 以 Adam 為例, 需要存 fp32 copy of the parameters, momentum and variance, 所以比 fp16 的 parameters 大 6 倍.
其中 optimizer states 以 Adam 為例, 需要存 fp32 copy of the parameters, momentum and variance, 所以比 fp16 的 parameters 大 6 倍.
以下介紹兩篇做法來降低 supernet 訓練的計算量
- ProxylessNAS [8]
- Single-path NAS [9]
ProxylessNAS
如果說我們一個 cell 有 $N$ 個 candidate ops (見下圖), 那都要為這所有 ops 保留 parameters, gradients, optimizer states 的空間. ProxylessNAS 主要想法就是, 每次只 active 一條 path, 因此只有一條 path 會需要 memory 這樣就很省了
架構參數 $\alpha$ 和 weights 則交錯 update, 每次要 update 時都要重新採樣 active path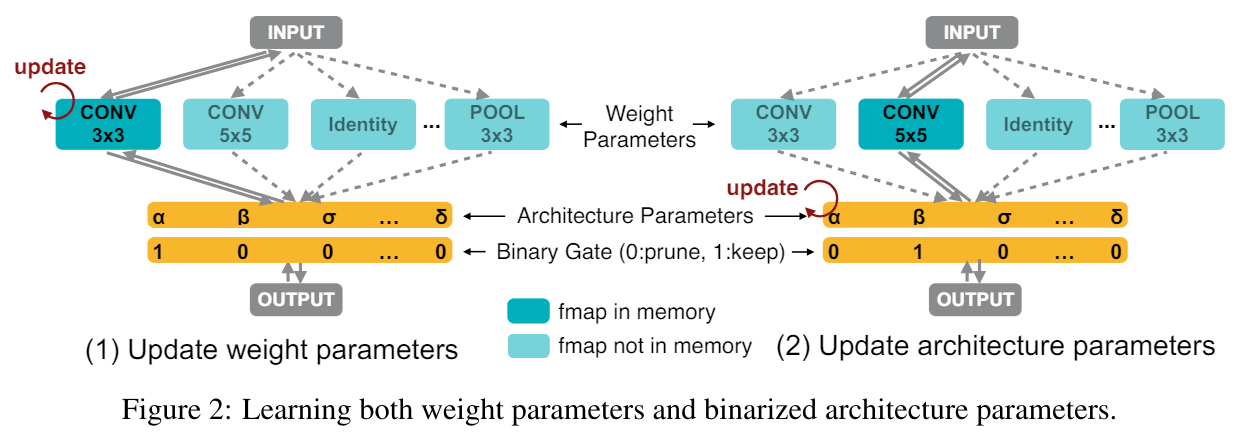 但其實在 update 架構參數 $\alpha$ 的時候 (上圖右子圖), 也還是需要 non-activate 的那些 output tensors, 這樣記憶體需求還是沒省到.
但其實在 update 架構參數 $\alpha$ 的時候 (上圖右子圖), 也還是需要 non-activate 的那些 output tensors, 這樣記憶體需求還是沒省到.
論文的做法就是乾脆先假裝只有 2 條 candidate ops (從 $N$ 先隨機採樣出 2 條), 更新這 2 條 ops 的 $\alpha$(所以一條是 active 另一條是 non-active path), 其他非這 2 條 op 的 $\alpha$ 不動.
舉個例子, 假設 $(\alpha_1,\alpha_2,\alpha_3,\alpha_4)=(0.3, 0.1, 0.4, 0.2)$, 我們採樣到 $\alpha_2=0.1$ 和 $\alpha_4=0.2$ 這兩條 paths, 所以不管 $\alpha_2$ 和 $\alpha_4$ 在這次 iteration 怎麼更新, 例如變成 $\alpha_2=0.05,\alpha_4=0.25$, 兩個加起來的機率仍要維持不變 $=0.3$, 至於其他架構參數則不動, e.g. $\alpha_1$ 和 $\alpha_3$ 不動.
Single-path NAS
另一個做法是針對 convolution kernel 優化降低 memory 需求, 如 Single-path NAS, 核心思想見論文的圖: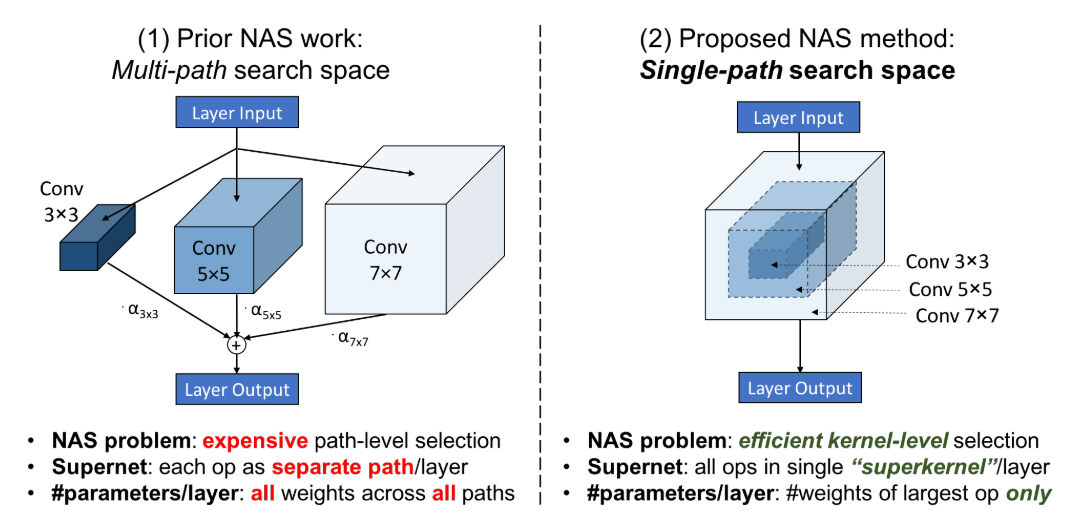 可以看到直接訓練一個最大 size 的 kernel 就可以, 小的 kernel 就 share 大 kernel 中間的 weights 即可. 這樣 memory 需求只需要一個大個 kernel size 就好
可以看到直接訓練一個最大 size 的 kernel 就可以, 小的 kernel 就 share 大 kernel 中間的 weights 即可. 這樣 memory 需求只需要一個大個 kernel size 就好
同樣的 output channel 也可以這麼做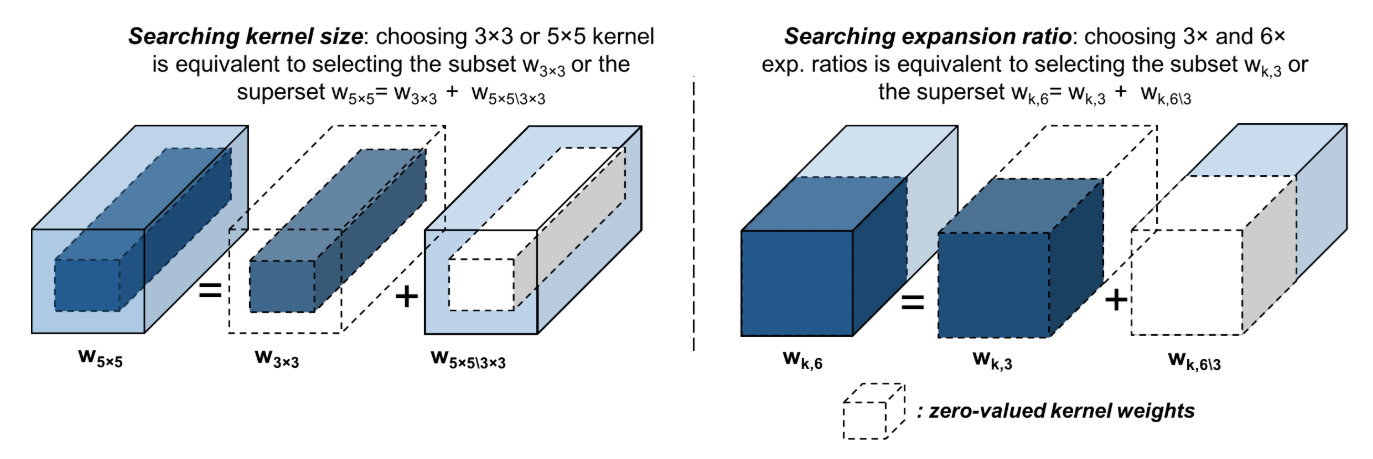 那麼就要有方式來決定各自的 layer 要用哪種 size 的 kernel weights, 以下式來說就是要有方法決定要不要留 $\mathbf{w}_{5\times5\backslash3\times3}$:
那麼就要有方式來決定各自的 layer 要用哪種 size 的 kernel weights, 以下式來說就是要有方法決定要不要留 $\mathbf{w}_{5\times5\backslash3\times3}$:
$$\begin{align}
\mathbf{w}_k=\mathbf{w}_{3\times3}+\mathbb{I}(\text{use }5\times5)\cdot\mathbf{w}_{5\times5\backslash3\times3}
\end{align}$$ 其中 $\mathbb{I}(\cdot)$ 是 indicator function 決定了要不要用更大 shape 的 kernel, 如果成立 $k=5$ 否則 $k=3$, 作者直接使用 L2-norm 的 weights 來當條件:
$$\begin{align}
\mathbf{w}_k=\mathbf{w}_{3\times3}+\mathbb{I}(\|\mathbf{w}_{5\times5\backslash3\times3}\|^2>{\color{orange}{t_{k=5}}})\cdot\mathbf{w}_{5\times5\backslash3\times3}
\end{align}$$ 當 L2-norm 大於某個 trainable threshold $t_{k=5}$ 就表示用大 kernel. 但作者希望 $t_{k=5}$ 能跟著 supernet 自己訓練起來, 也就是說自己決定 kernel size, 問題是 $\mathbb{I}(\cdot)$ 不可微, 所以在計算 gradient 時, 作者就用 sigmoid function $\sigma(\cdot)$ 替代: $\mathbb{I}(x>t)\approx\sigma(x-t)$
forward 仍使用 $\mathbb{I}(\cdot)$, 但 backward 用 $\sigma(\cdot)$ 替代, 相當於 STE 作法
另外, 感覺可以在訓練後半段把 sigmoid function 變得更 sharp (接近 indicator function)
其實我讀到這有個疑問, 如果某個小 kernel size 是最佳解 (loss 最低), 由於小 kernel size 只是大 kernel 的 subset, 直接對大 kernel 優化, 最理想狀態就是得到小 kernel 的結果 (外層 weights 優化完得到 0)
所以理想上直接訓練大 kernel 會得到更低的 loss, 架構選擇上一定會傾向選大 kernel 了, 這樣還需要上面 learnable 的 threshold 嗎?
我自問自答, 作者有加入 HW constraints, 由於小 kernel 的 latency 較小, 對 HW 的 loss 來說比較傾向小 kernel, 所以才能取得平衡.
另外, 由於所有的 subnet 的 weights 都是共享的, 但不同的 subnet 可能需要不同的參數值, 大小 kernel 共 share 參數值可能 performance 會被限制住. Once-for-All [14] 論文裡有對 sharing weight 在多做一個 transformation 來增加彈性. 例如下圖左子圖: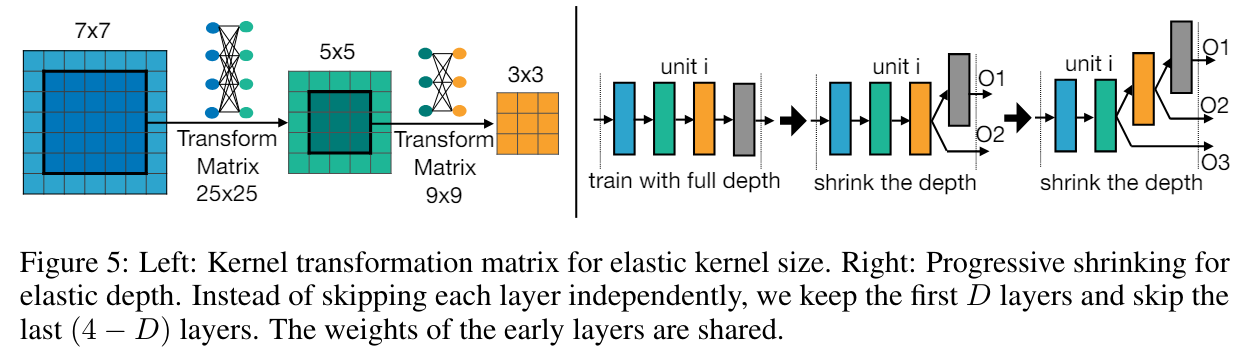 kernel $5\times5$ 的 weights 是 kernel $7\times7$ 中間 $5\times5$ 的 weights 在經過一個 transformation 得到. 因此大 kernel 中間的 weights 可以跟小 kernel 的 weights 數值不一樣.
kernel $5\times5$ 的 weights 是 kernel $7\times7$ 中間 $5\times5$ 的 weights 在經過一個 transformation 得到. 因此大 kernel 中間的 weights 可以跟小 kernel 的 weights 數值不一樣.
然後這個 transformation matrix 對所有 layers 都共用一個, 所以也沒有增加額外很多參數量.
Skip Connection 過多導致效果變差
如果某條 path 什麼事都不做, i.e. identity op, 就相當於跳過這層 layer, 也就是 skip connection. DARTS 訓練到後期會容易發現 skip connection 過多導致架構很淺而影響 performance.
Fair DARTS [11] 這篇論文分析了造成這個現象的底層原因: 架構參數 $\alpha$ 比起 weights 參數更新得更快
為什麼呢? 這不難想像, 以 convolution 的 kernel 假設 $7\times7$ 舉例, weights 就有 $49$ 個要調整好才能有作用, 在調整好之前, 對應的架構參數很容易就覺得這個 convolution OP 不好所以重要性要下降, 而 skip connection 沒啥 weights 參數要訓練, 所以相較之下容易做得好 (skip connection 具有 unfair advantage), 因此 skip connection 對應的架構參數就會上升.
加上最後在 softmax 只能 $N$ 選 $1$ 的條件影響下 (exclusive competition), 自然而然 skip connection 的架構參數很容易就愈來愈大
論文的解決方法
- 解決 exclusive competition: 從 one-hot 變成 multi-hot, i.e. softmax 變成 $N$ 個 sigmoid $\sigma(\cdot)$
(但這樣就沒辦法 ProxylessNAS or Single-path 來降低 memory 了?)
$$\bar{o}_{i,j}(x)=\sum_{o\in\mathcal{O}}\sigma(\alpha_{o_{i,j}})o(x)$$ 每個 OP 都各自決定要不要留, 因此論文用一個 threshold $\sigma_{threshold}$ 來決定 - 解決 unfair advantage of skip connection: Architecture loss 多加一個 0-1 loss $\mathcal{L}_{0-1}$ ($\lambda$ 是常數)
$$\min_\alpha\mathcal{L}_{val}(w^\ast(\alpha),\alpha)+\lambda\mathcal{L}_{0-1} \\ \text{, where}\quad \mathcal{L}_{0-1}=-\frac{1}{N}\sum_{i=1}^N(\sigma(\alpha_i)-0.5)^2$$ $\mathcal{L}_{0-1}$ 在一開始機率是 0.5 的時候 gradient 很小, 目的是希望 architecture 參數不要更動太快, 先讓 weights 參數比較容易 update, 然後當架構參數跑到 0 or 1 的方向變得 gradient 比較大, 這目的是希望架構參數要不就是 0 要不就是 1, 這樣在最後用 argmax 選 subnet 的時候讓 training 與 inference 比較一致
見下圖綠色的 curve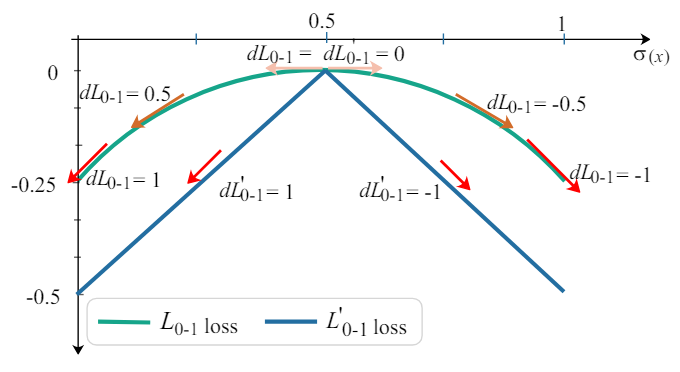
另外 RobustDARTS [10], DARTS- [12], DARTS+ [13] 也是嘗試解決這個問題, 透過一些 early stop 方法
拆開 Weight 訓練和架構搜索
One-shot NAS, 使用 supernet 將 weights 和架構參數一起訓練出來 (jointly train)
但如果要佈署的 devices 非常多, 且各自有不同的 HW constraints, 變成都要重新訓練 supernet
如果我們能將 supernet 的 weights 訓練和後續佈署的架構搜索拆開成獨立兩步驟, 那麼 supernet 只要訓練一次就好, 後續各種不同 device 的架構搜索都基於不動 weights 情況下找出好的 subnet
參考下圖 (SongHan Lab3)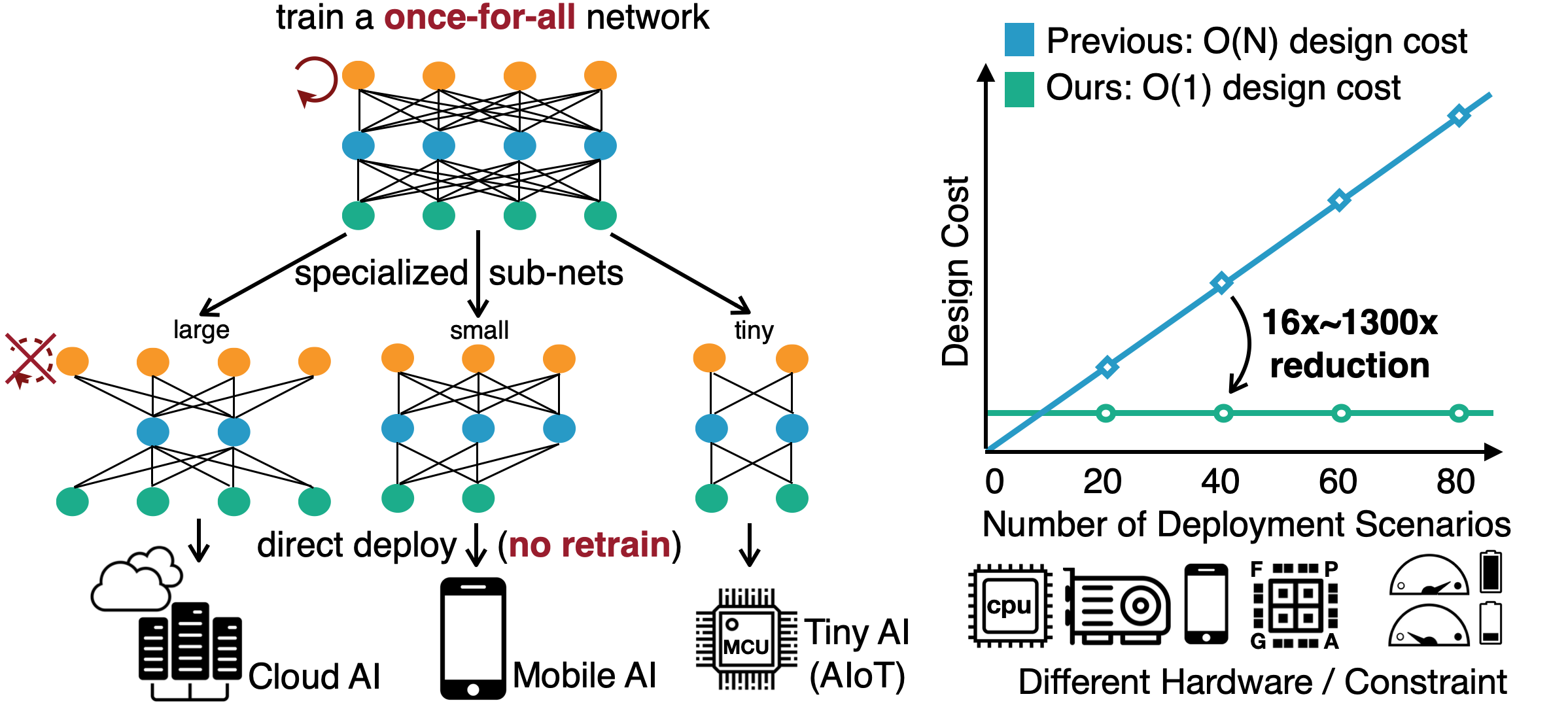 Once-for-All [14] 和 Single Path One-Shot (SPOS) [15] 是兩篇嘗試解決這個問題的做法
Once-for-All [14] 和 Single Path One-Shot (SPOS) [15] 是兩篇嘗試解決這個問題的做法
Single-path One-shot (SPOS)
One-shot NAS 的缺點是 architecture 跟 weight 的參數訓練耦合很強, 造成不同 architectures (subnet) 訓練時充分度各不相同, 而 gradient 又使用 loss 來引導, 可能導致問題愈來愈嚴重.
如果要拆開 weight 訓練和架構搜索的話, supernet 訓練就要想辦法緩解上述問題: 如果 supernet 訓練完後, subnets 之間訓練充分度不同, 這樣在後續架構搜索出來的 subnet 可能效果會不一, 有些好有些差.
SPOS 作法就相當直接了當, 取消掉架構參數 $\alpha$ 了 (沒有架構參數要學, 也就可以拆開 weight 訓練和架構搜索), 同時訓練 supernet 的時候不同 subnet 的採樣固定要 uniform distribution (or a fixed prior), 希望保證不同 subnet 的訓練都一樣充分
沒了, 方法就這樣
再多說一點的話, 反正都沒有 architecture 參數要訓練了 (全部都 uniform 採樣), 乾脆連 kernel 的 channel size, quantization bits 都直接採樣下去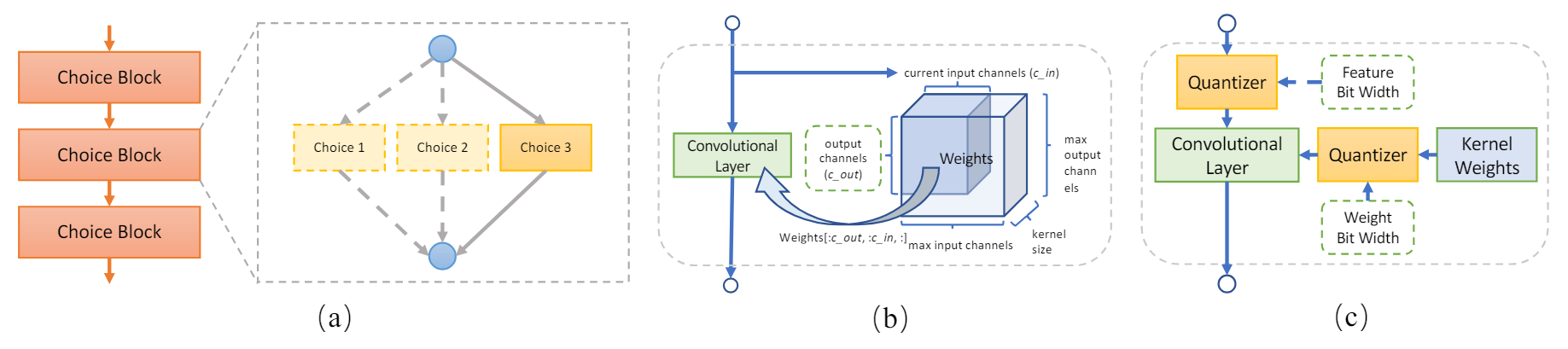 MicroSoft NNI 的 SPOS 也說明的滿清楚的, 可以參考一下
MicroSoft NNI 的 SPOS 也說明的滿清楚的, 可以參考一下
Once-for-All (OFA)
與 SPOS 主要差異在 OFA 的 supernet training 使用 Progressive Shrinking (PS) 作法, 描述如下:
Supernet 採樣 subnet 訓練時, 全部都先 train 最大的設定 (subnet 只採樣到最大的設定), e.g. kernel size, depth, width 都選最大, 然後接著開放可以選小一點的 kernel size (大的一樣有機會 sample 到), 再來依序開放 depth and width. 其中 resolution 從頭到尾都開放從小到大的採樣. 好處是, 大的 subnet 如果是 well-trained 的話, 小的 subnet 就會從一個比較好的 initial 開始 (因為 share weights)
好處是, 大的 subnet 如果是 well-trained 的話, 小的 subnet 就會從一個比較好的 initial 開始 (因為 share weights)
另外同時大小 subnet 一起 train 表示共同 share 的小 size weights 那部分會愈重要
PS 方法在 kernel size, depth 和 width 有一些 trick 如下 kernel 有個 transform matrix (不同層之間 shared) 的好處是, 由於小 kernel 只是大 kernel 的一部分 weights. 造成大 kernel 的 subnet 在優化的時候要遷就小 kernel size 的 subnet, 因此多一個 transform matrix 可以有一些彈性, 讓中間小 kernel 用到的 weights 可以做些變化.
Depth 的做法看上圖應該很清楚了
再來 width 對應到 output channels, 因此每次 fine tune 後會根據重要性做個排序 (見下圖), 這樣選 sub-channels 比較方便. 重要性就用 L1 norm of a channel’s weight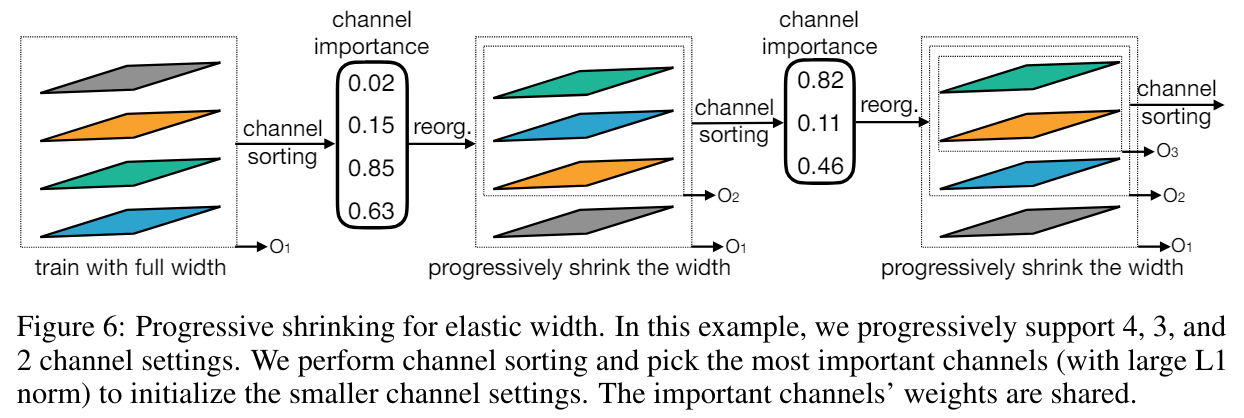 Supernet 訓練完後, 架構搜尋可以用 Evolution Method, 如下圖就不多說, 想法就適者生存找出好架構而以
Supernet 訓練完後, 架構搜尋可以用 Evolution Method, 如下圖就不多說, 想法就適者生存找出好架構而以 註: MIT SongHan Lab 的課程作業 Lab3 (Course, Lecture 7 and 8) [14] 有讓我們練習 OFA 的 evolution method (但沒有 progressive shrinking training)
註: MIT SongHan Lab 的課程作業 Lab3 (Course, Lecture 7 and 8) [14] 有讓我們練習 OFA 的 evolution method (但沒有 progressive shrinking training)
References
- MicroSoft NNI: Multi-trail NAS, One-shot NAS
- DARTS: Differentiable Architecture Search [arxiv] [筆記]
- 提煉再提煉濃縮再濃縮:Neural Architecture Search 介紹
- Gumbel-Max Trick [筆記]
- FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search [arxiv]
- FBNetV2: Differentiable Neural Architecture Search for Spatial and Channel Dimensions [arxiv]
- SNAS: Stochastic Neural Architecture Search [arxiv]
- ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware [arxiv]
- Single-Path NAS: Designing Hardware-Efficient ConvNets in less than 4 Hours [arxiv]
- Understanding and Robustifying Differentiable Architecture Search [arxiv]
- Fair DARTS: Eliminating Unfair Advantages in Differentiable Architecture Search [arxiv]
- DARTS-: Robustly Stepping out of Performance Collapse Without Indicators [arxiv]
- DARTS+: Improved Differentiable Architecture Search with Early Stopping [arxiv]
- Once-for-All: Train One Network and Specialize it for Efficient Deployment [arxiv] [SongHan Lab3]
- Single Path One-Shot Neural Architecture Search with Uniform Sampling [arxiv] (NNI 的 Single Path One-Shot (SPOS))
- L0 Regularization 詳細攻略 [筆記]
- microsoft/DeepSpeed 的論文