這裡指的 “高手” 來自 Google DeepMind 的科學家 Sander Dieleman [blog], 而他的工作有多大影響力請自行查看 [google scholar] 就會知道.
這是筆者參加 ACDL 2025 MLSS 的其中一個 lecture, 也是私心認為最好的演講.
共分三堂, 前兩堂講了 diffusion models, 最後一堂講了他目前對神經網路訓練的各種心得/mindsets
能從這麼頂尖的 AI 科學家直接聽取經驗實屬難得!
有意思的是…這些經驗和目前主流技術, 有一些已經落實在自己的工作上, 這讓我感覺到自己確實也走在對的方向上.
但比較可惜的是過了一個月後才開始想要紀錄一下當時聽到的內容, 因此以下筆記或許會跟原本的意思有偏差, 對此情況則會融入自身的理解來記錄.
分四個部分 (擷取自演講投影片內容)
- Process: 點出該用什麼心態和工作流程, 來產生模型
- Architecture: 針對 NN backbone 設計的一些說明
- Training: 訓練 NN 的一些心得和技巧
- Miscellany: 其他各種雜項心得
Process (mindset 和工作流程)
大部分想法都沒用, 多嘗試就對了:
當我們在開啟一個 ML 研究問題時, Sander Dieleman 劈頭就先說大部分的想法都沒用, 但大家不用因此而沮喪
需要的僅僅是嘗試大量的想法, 且不要在同一個方向投資太多 (鑽牛角尖)
先決定 metric 是什麼並盡量自動化:
當一個 metric 包含了人工流程, 絕對會拖慢整個研發進度
也不用太擔心 metric 不夠”精準”, 就算比較簡單粗暴的 metrics (e.g. FID or BLEU) 也很有用
另外注意到 metric $\neq$ loss, 我們不能僅僅看訓練的 loss 來挑模型, 也要根據 metric 來挑選實驗的 Iteration 速度是關鍵:
別急著把 dataset/model 等等 scale up, 先讓自己在一個合適的 scale 上快速做實驗
這裡的快速是重點, 誰能更快做出更多實驗, 誰就更有可能達到目標
有個例外: O(10B) 參數量以上的等級, 因為有可能小模型的結論在這個等級以上不適用擁抱不確定性:
並不是每項實驗都必須做到 100% 確定有效, 該方法才有效, 有時候依靠直覺輔以一些實驗就能判斷並且前進, 這時候會更有效率
因此策略就是: commit & revisit (自己的解釋: 稍微驗證後, 方法先上, 後續回顧驗證、補充)不要忽略工程上的投資:
基於速度和實驗數量才是王道的理由, 我們要能瞭解訓練或是推論時的 bottelneck 在哪裡
善用 profiler 來分析哪個節點拖慢速度
並且要注意不要被 training iteration 數量誤導, 要看的是 wall-clock time (牆上的時間)
意思是真正一次實驗的 ”物理時間” 有沒有縮短
還有 matrix multiplications 很快速, 盡量什麼運算都用矩陣乘法完成
他還舉個例, 在做一個 CV 題目時, 為了處理 rotation invariant 問題還特地寫了底層的 CUDA 程式來加速
他說那是他第一次寫 CUDA codes, 雖然還要花時間學, 但獲得的收益讓他覺得是個相當划算的投資!
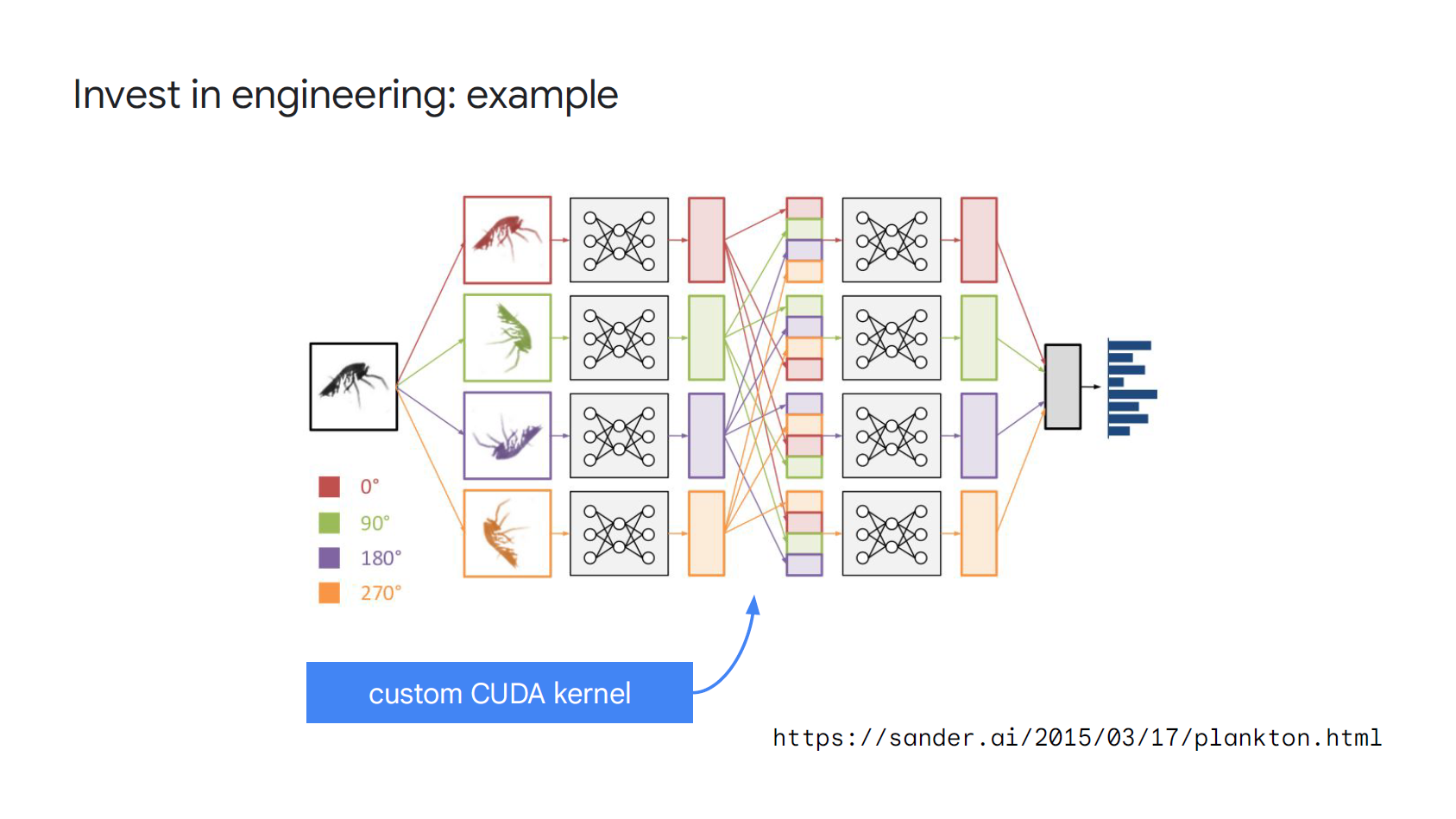
 (CUDA 的幾行 codes 卻大大加速了實驗速度)
(CUDA 的幾行 codes 卻大大加速了實驗速度)時刻思考兩個問題, 什麼能讓 metric 進步, 以及為什麼可以?
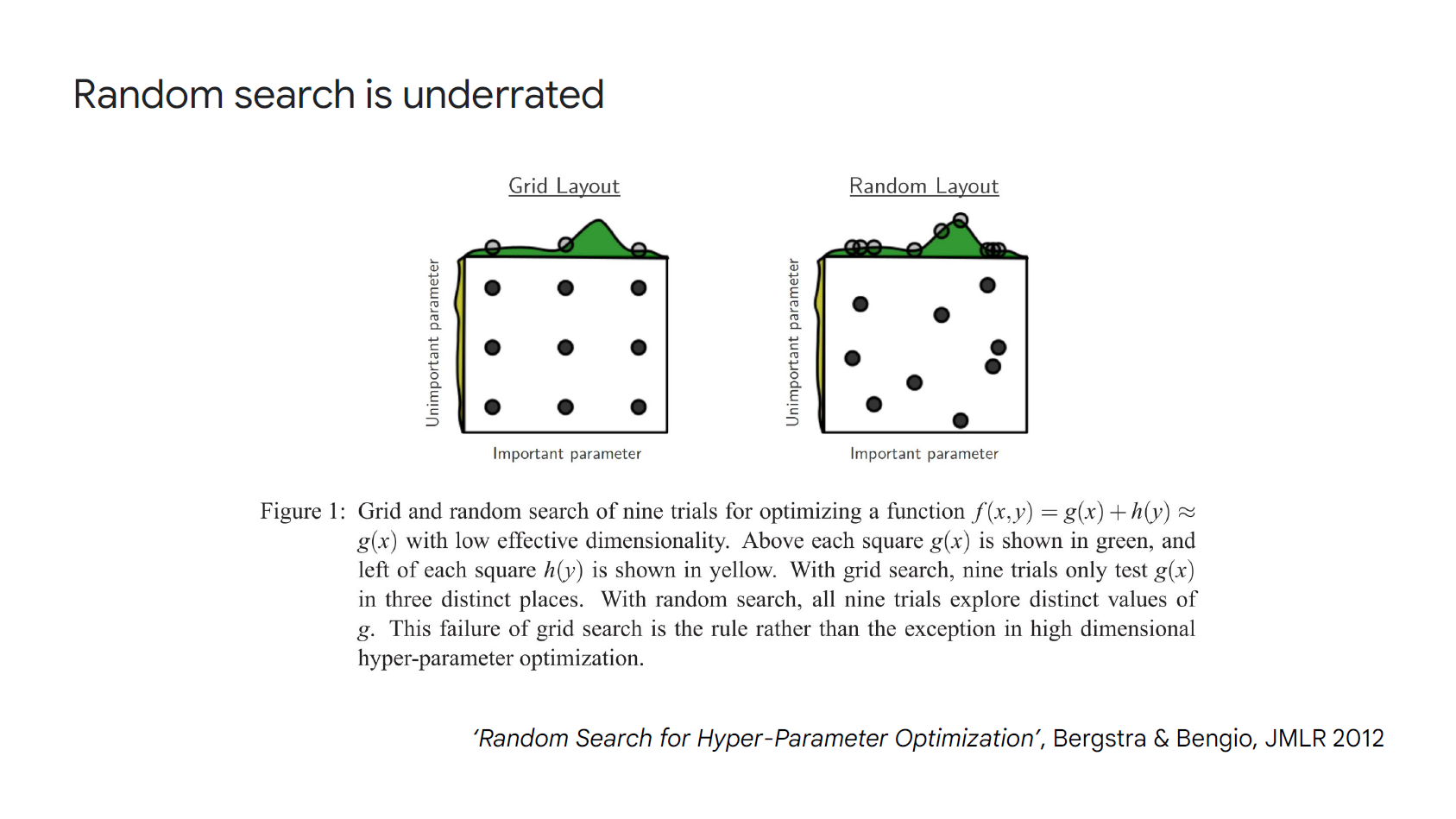
Hyperparameter 的尋找, Grid V.S. Random:
大部分超參數可以採用 logarithm scale, e.g. …, 0.1, 0.3, 1.0, 3.0, 10.0, …
Gird search 有助於我們理解那些超參數有作用
而 random search 有助於我們最後達到 SoTA 的模型
下圖雖然是 2-dim 的超參數, 但很形象的展示出 random search 能找到最大點的 metric
Architecture (NN backbone)
省略說明基本 layers, 如 linear, ReLU, GeLU, conv., pooling, attention, initialization, … etc.
Residual connections 非常有效:
這是最簡單且有效的模型設計技巧 (或許 dropout 也是)
他能有效保證 gradient 流通並且層數可以很深
Morden version: divided by $\sqrt{2}$, or residual 初始化為 $0$. (這我不清楚, 有機會找找來源)Normalization layers 設計:
不管 BatchNorm, LayerNorm, GroupNorm, InstanceNorm, RMSNorm 或是 FiLM 都用以下公式:
$$\begin{align*} \mathbf{y}=a\cdot\frac{\mathbf{x}-\mu}{\sigma}+b \end{align*}$$
BatchNorm 漸漸淡出:
說的一個原因是太多可能的 bug 出現在 deploy 階段了
(看看筆者之前這篇筆記就知道 BN 確實比較複雜, 但自己目前的工作上還是很多地方依賴 BN layer…)使用 FlashAttention:
Transformer 加速必不可少的技巧是使用 FlashAttention
(目前已經出到 ver. 3 了, 另外 Jia-Bin Huang 的這部影片: How FlashAttention Accelerates Generative AI Revolution 解說精準清晰, 推薦觀看)大模型使用 QK normalization:
在超過O(10B)參數的大模型 logits 會長得非常大使得訓練不穩, 一個簡單作法是把 Q, K 再過一個 LayerNorm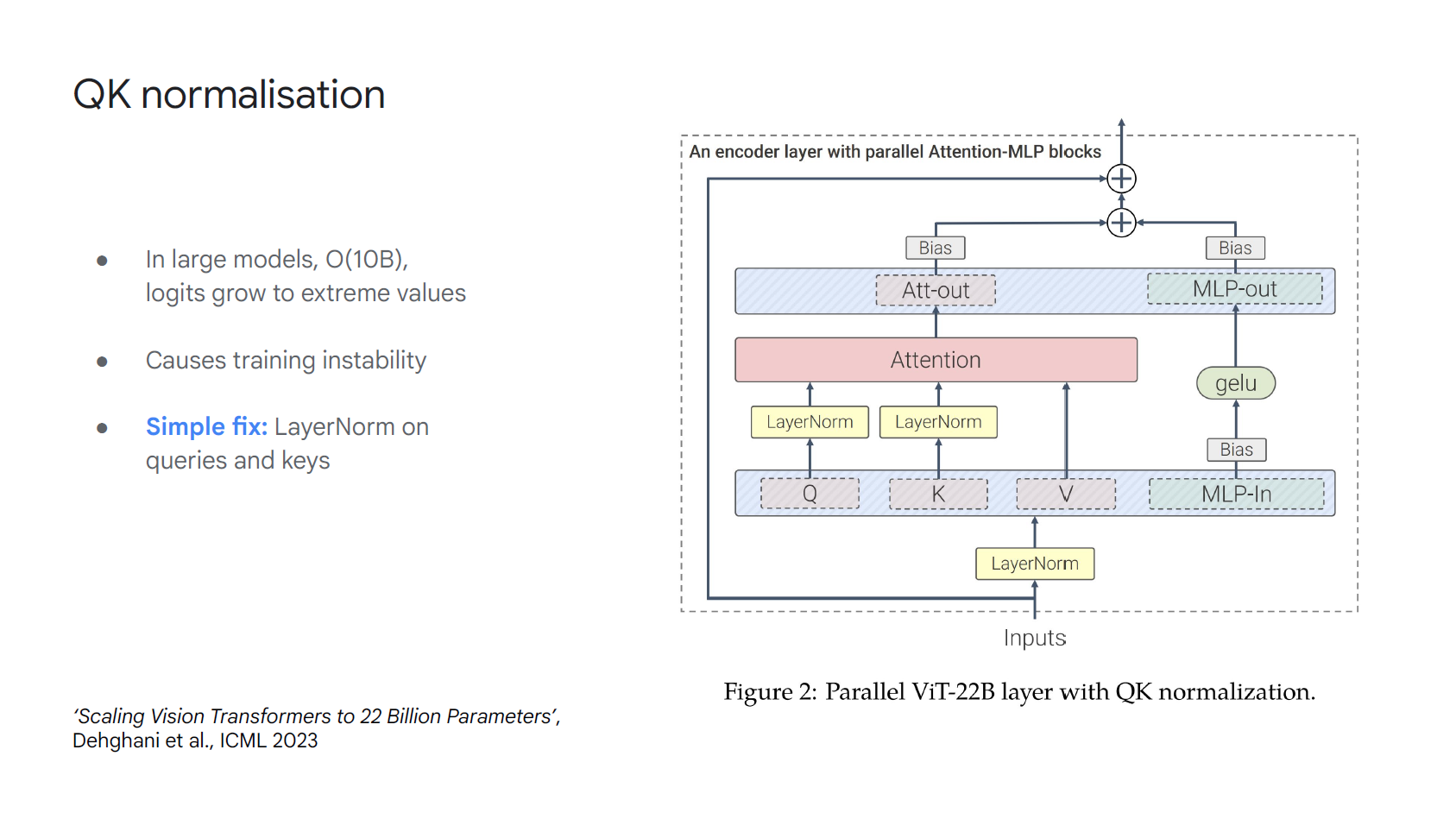
注意模型中的 Information bottlenecks:
例如假設在你的模型裡有使用 Gumbel-softmax, Concrete distribution, VQ (as in VQ-VAE), KL penalty (as in VAE), …, 要特別注意這些技巧帶來的準確度損失
例如可能要增加 VQ 的 table size, KL penalty 的權重等等.
Gumbel-softmax 或是 VQ (Vector quantization) 都要使用 STE 技巧, 有關 STE (Straight Through Estimator) 筆者以前文章有紀錄不少, 參考索引.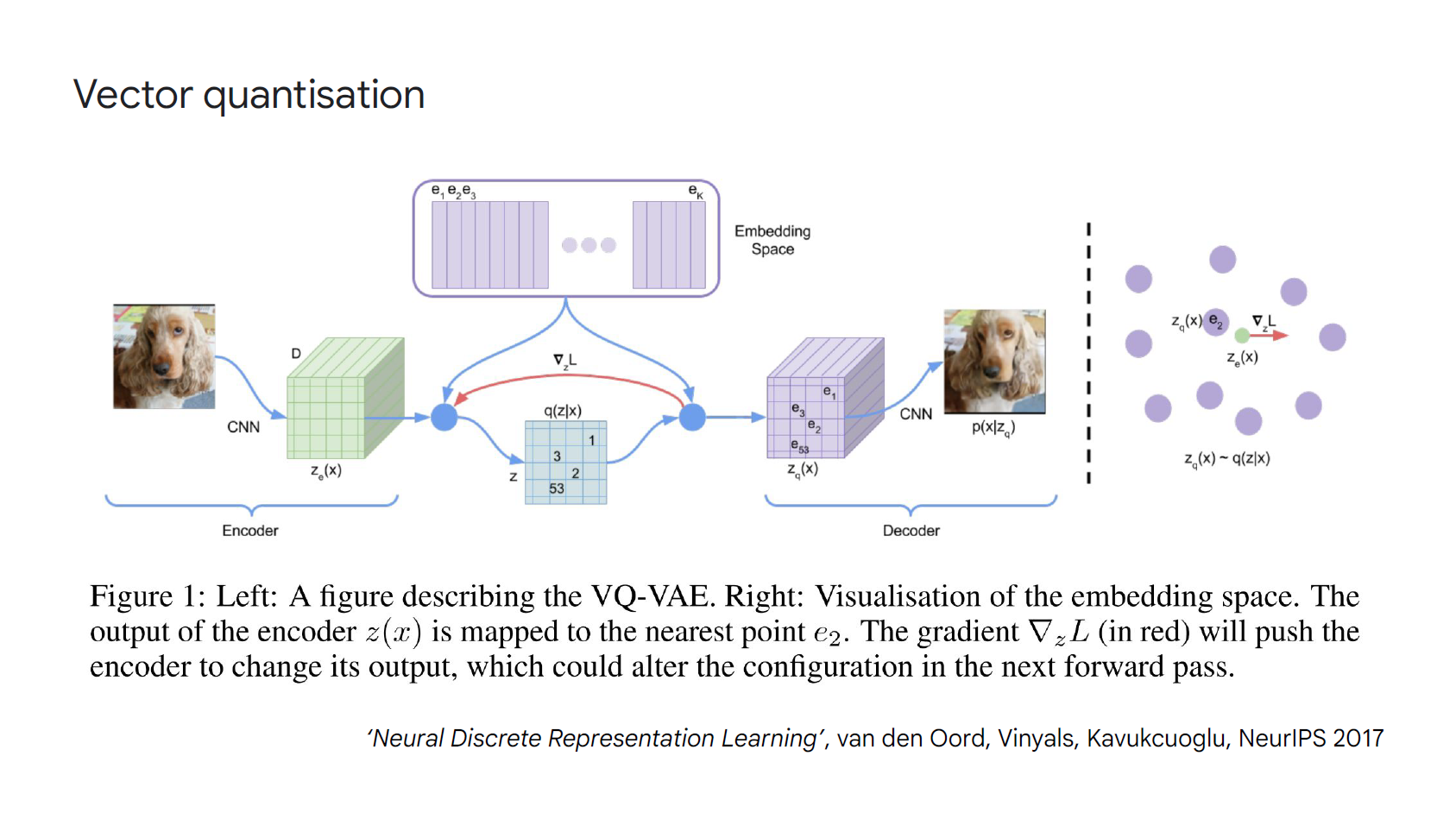
Training (心得和技巧)
Optimizers 心得:
沒其他理由就用 Adam
(筆者認為應該用 AdamW, 參考 Jia-Bin Huang 的這部解說: The Algorithm that Helps Machines Learn)
注意到超參數 $\beta_2$ (adaptive step size 的控制) 也是很重要的, 需要調整
別忽略另一個可條的超參數 $\epsilon$! (這其實也影響到 step size 的控制)

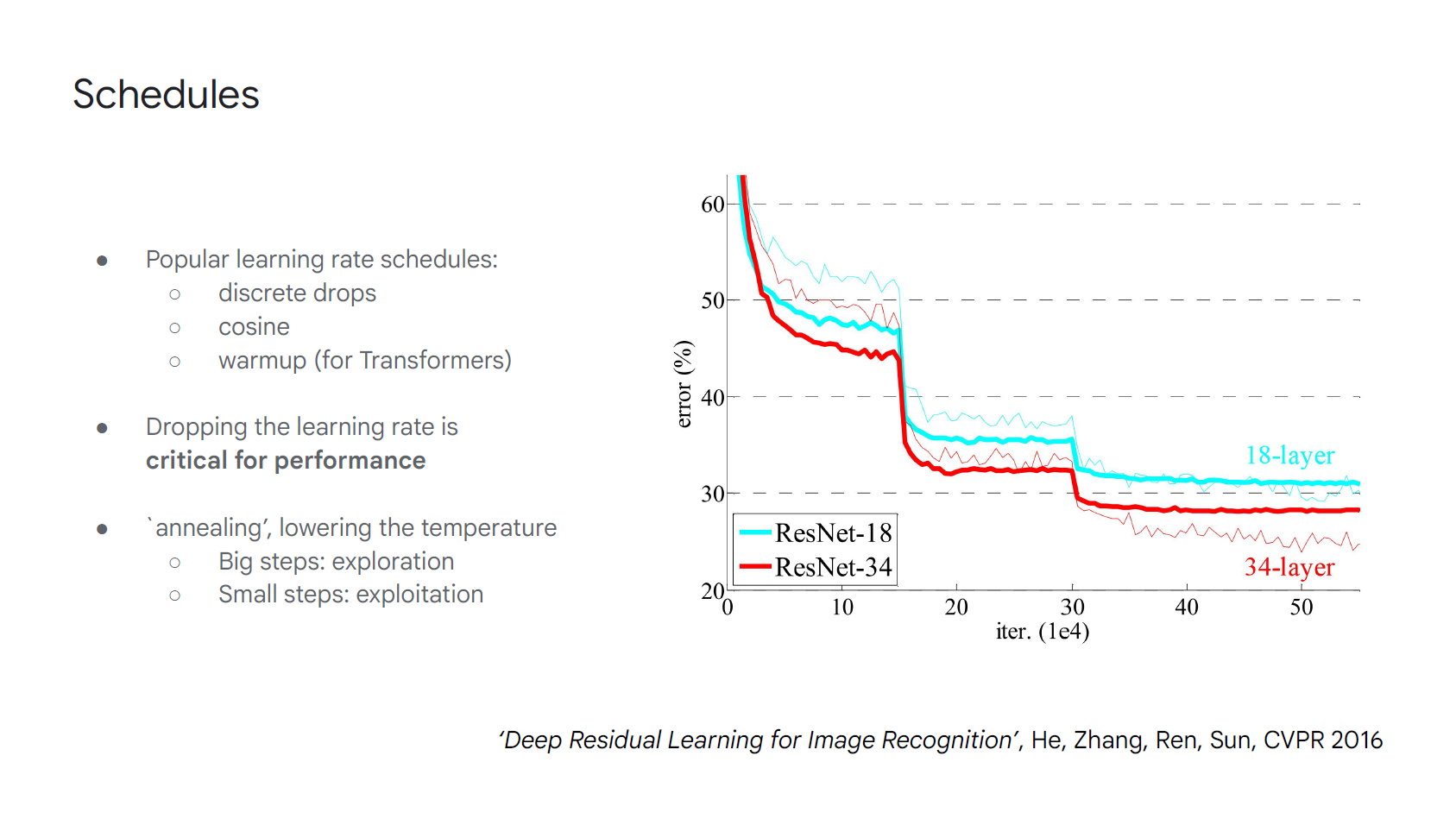
Scheduler 心得:
Sander Dieleman 提醒到利用 scheduler 把 learning rate 階梯式的降低很關鍵, 可以大大進步
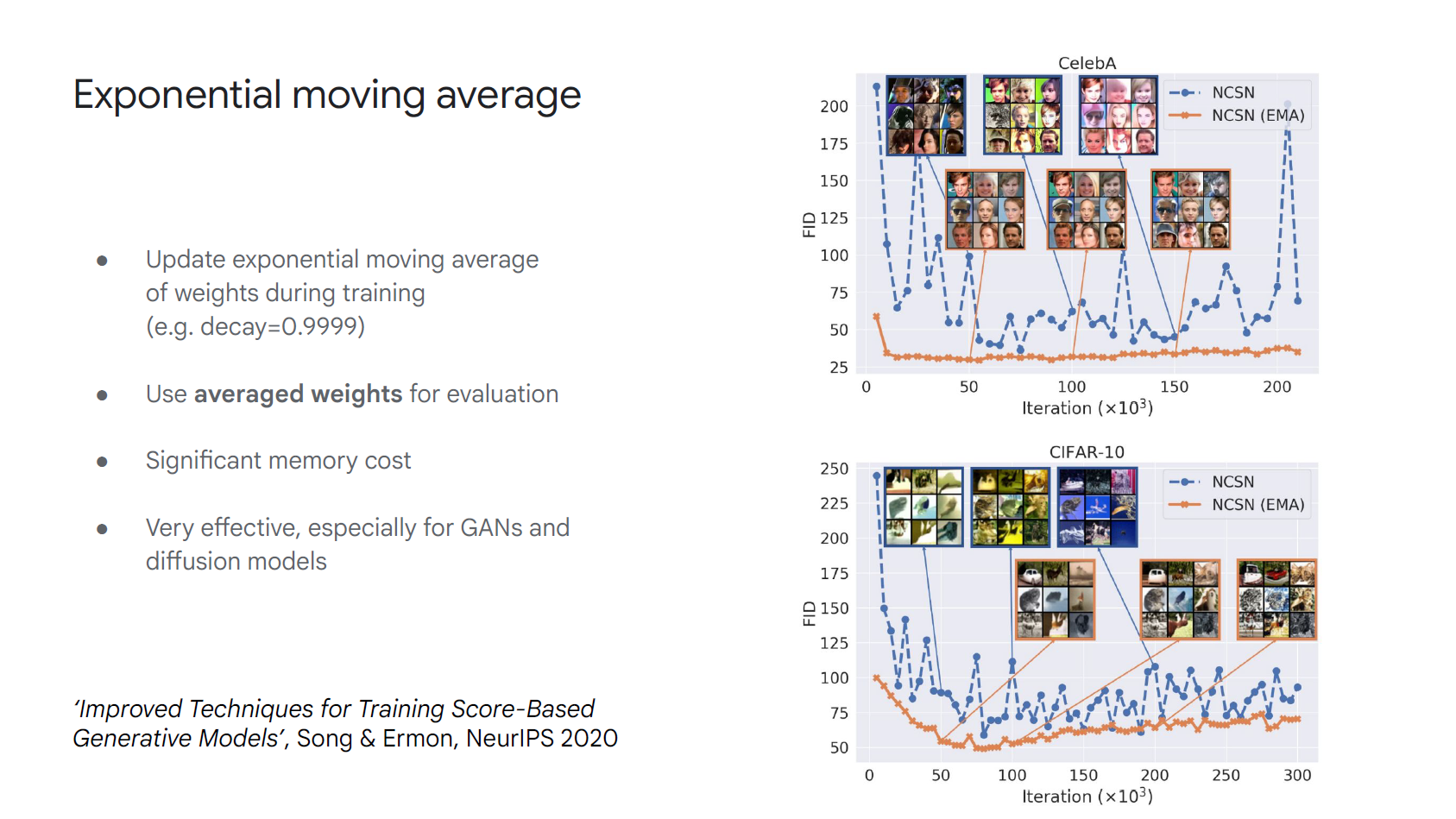
模型上的 Exponential Moving Average (EMA):
筆者以前這篇文章: Why Stochastic Weight Averaging? averaging results V.S. averaging weights 解釋到 model 的 aggregation 會得到不錯且 robust 的結果
呼應了 Sander Dieleman 實務上的心得
Scaling across devices: parallelism and sharding
Data parallelism 通常就很夠用且運作很好了 (模型小於 O(10B))
Model parallelism 已經愈來愈容易實現了 (e.g. jax.jit)
基本原則就是減少 devices 之間的通訊開銷
(推薦看 Song Han 教授的課程: TinyML and Efficient Deep Learning Computing 的 Chapter III: Efficient Training)有時候重算比較快:
因為 memory access 比起計算來說更慢, 所以與其從 memory 拿上次算過的內容, 或許乾脆考慮重算就好 (FlashAttention有用到的技巧之一)Low-precision arithmetic:
訓練時使用 half precision (float16, bfloat16) 可以省記憶體和更快速
不過要小心由於使用 low precision 可能在 rescaling 和 stochastic rounding 這些 op 帶來的 performance drop 或不穩定
在 quantization 時要特別觀察 outliers, 這也是 Transformer 的 PTQ 效果不好的主要挑戰!
注意到 Transformer 的 outlier 底層原因由 Qualcomm 這篇論文分析的結果可得知原因 (PS: attention sink 也同樣解釋了一樣的原因). 解法可用論文裡的 clipped softmax 或 gating 方法, 又或者使用 softmax1 的 QuietAttention 作法 (實務上相當於 Q 和 K 都增加一個 zero vector 的 token).這部分詳見筆者的筆記: 不要逼 Attention 選擇, 留個出口吧.
有提到 QAT (int8, int4) 已經開始是個趨勢了
(這邊有點不確定有沒有理解錯? 如果是的話就太好了, 不然對 LLM 還要花很多精力 PTQ, 還不如大廠一開始就鎖定 QAT 的 LLM model, 這樣對下游廠商最友善, 也利於推廣 edge 應用)
Miscellany (其他各種雜項心得)
可以嘗試 distillation 各種用法:
降低模型大小, 從大模型蒸餾給小模型
模型重鑄, 意思是直接重新蒸餾出另一個一樣大小的新模型 (可能效果更好?)
換架構, 例如 teacher model 是 transformer 而 student model 是 RNNAutodiff 是項偉大的工具:
理解底層 autodiff 如何運作是非常有幫助的 (例如從比較底層理解 computation graph [以前筆記], 到底層 PyTorch 的一些實作)
對於 debug 會很有幫助, 其中要注意 gradients of gradients
NN 大部分情況都很 linear, 意思是 second order gradients 很 sparseSprinkling epsilons (除零, sqrt 等都要加上):

Neural nets have low Lipschitz constants:
呼應到上面提到 second order gradients 很 sparse, 數學一點就是具有很小的 Lipschitz constants.
而 Sander Dieleman 提到, 如果想要增加 nonlinear 程度可以使用 positional encodings, random Fourier features 或是 activation 使用 sin(x) (SIREN)

總結
- Process (mindset 和工作流程)
- 大部分想法都沒用, 多嘗試就對了
- 先決定 metric 是什麼並盡量自動化
- 實驗的 Iteration 速度是關鍵
- 擁抱不確定性
- 不要忽略工程上的投資
- 時刻思考兩個問題, 什麼能讓 metric 進步, 以及為什麼可以?
- Hyperparameter 的尋找, Grid V.S. Random
- Architecture (NN backbone)
- Residual connections 非常有效
- Normalization layers 設計
- BatchNorm 漸漸淡出
- 使用 FlashAttention
- 大模型使用 QK normalization
- 注意模型中的 Information bottlenecks
- Training (心得和技巧)
- Optimizers 心得, 用 Adam, AdamW 以及調整它們的超參數
- Scheduler 心得, learning rate 要階梯式降低
- 模型上的 Exponential Moving Average (EMA)
- Scaling across devices: parallelism and sharding
- 有時候重算比較快
- Low-precision arithmetic, 訓練使用 half precision, transformer 注意 outliers 並使用 QuietAttention
- Miscellany (其他各種雜項心得)
- 可以嘗試 distillation 各種用法
- Autodiff 是項偉大的工具, 理解底層原理對於 debug 很有幫助
- Sprinkling epsilons (除零, sqrt 等都要加上)
- Neural nets have low Lipschitz constants, 如果要增加非線性程度, 可以考慮 positional embeddings 或 sin(x) (SIREN)