此篇文章為 IndexTTS2 論文 (arxiv, 官網, Github) 的筆記, 內容幾乎都是 AI 產出的, 而且也確實整理的很棒
LLM 的進步已經從根本上改變我讀論文的方式了
現在我都是想像有一個學生 (AI) 開始跟我報告, 先請他講論文的 whole (high-level) picture, 然後開始一點一點對話式的挖掘
整個過程絲滑舒服, 想聽什麼論文的報告隨時都可以, 想詢問多深入都可以, 也不用擔心學生報告整理太爛或沒準備好 😛
閱讀體驗正式進入 “Vibe Reading” 時代 … 😃
⚠️ 以下內容幾乎為 AI 口吻, 我依照結構整理起來而已(自己看的), 吃不下 AI 文的讀者請見諒左轉
整體架構設計 (High-Level Architecture)
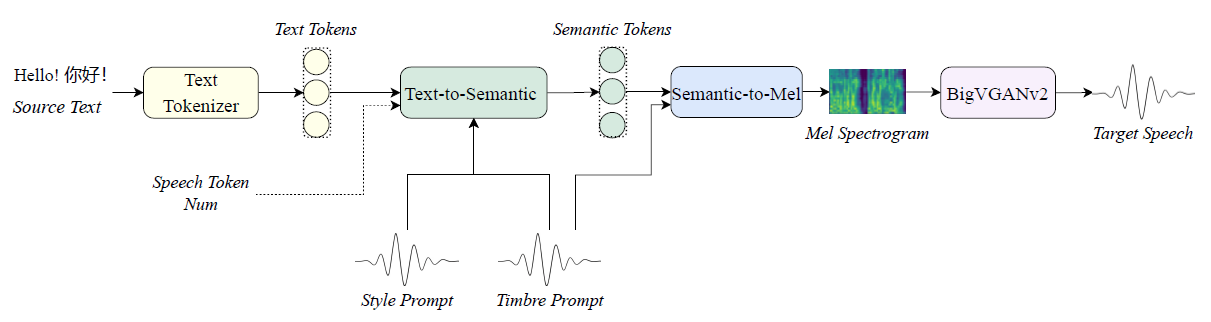 這邊的 Style Prompt 指的是 emotion 模組, 而 Timbre Prompt 指的是 speaker 特徵模組
這邊的 Style Prompt 指的是 emotion 模組, 而 Timbre Prompt 指的是 speaker 特徵模組
IndexTTS2 採用了串接式的架構,主要由三個模組組成 :
- Text-to-Semantic (T2S) 模組:
- 技術核心:基於 Autoregressive Transformer 。
- 功能:負責將文字轉換為語義 Tokens。
- 創新點 1 (時長控制):它引入了一個特殊的機制,讓使用者可以「明確指定」生成的 Token 數量,從而精確控制語音長度;同時也支援不指定長度的自由生成模式 。
- 創新點 2 (情感解耦):使用梯度反轉層 (GRL) 來分離「情感」與「說話者身分」,確保改變情感時不會影響到音色 。
- Semantic-to-Mel (S2M) 模組:
- 技術核心:基於 Conditional Flow Matching (非自回歸) 。
- 功能:將 T2S 生成的語義 Tokens 轉換為梅爾頻譜圖 (Mel-spectrogram)。
- 創新點 (GPT Latent 增強):為了避免在強烈情感表達時出現發音含糊的問題,它引入了 T2S 模型最後一層的 GPT 潛在特徵 (Latent Representations) 來增強語音的清晰度與穩定性 。
- Text-to-Emotion (T2E) 模組 (輔助功能):
- 技術核心:基於大語言模型 (利用 Deepseek-r1 蒸餾到 Qwen-3-1.7b) 。
- 功能:讓使用者可以用「自然語言描述」(例如:”悲傷且緩慢的語氣”)來控制情感,而不僅僅是依賴參考音檔 。
- Vocoder:使用 BigVGANv2 將頻譜圖轉為最終的波形聲音 。
Text-to-Semantic (T2S) 模組

輸入序列的構造 (Input Sequence Construction)
T2S 的輸入不僅僅是文字,而是一個精心設計的序列,包含了控制語音生成的所有必要條件。其輸入序列 $X$ 被定義為:
$$\begin{align*}
X = [c, p, e_{\langle BT\rangle}, E_{text}, e_{\langle BA\rangle}, E_{sem}]
\end{align*}$$ 各個符號的意義如下 :
- $c$ (Speaker Attributes):說話者特徵向量,控制音色。
- $p$ (Duration Embedding):時長控制向量,這是 IndexTTS2 的核心創新之一。
- $E_{text}$:輸入文字的 Embedding。
- $E_{sem}$:目標語義 Tokens 的 Embedding(訓練時來自 Ground Truth,推論時由模型逐個生成)。
- $e_{\langle BT\rangle}, e_{\langle BA\rangle}$:邊界 Tokens,用來區隔文字序列與語義序列。
在處理情感控制時,輸入會調整為 $[c+e, \dots]$,其中 $e$ 是情感 Embedding 。
精確時長控制機制 (Duration Control Mechanism)
這是 IndexTTS2 解決 AR 模型難以控制長度的關鍵技術。
- 原理:模型不只依賴文字內容預測何時結束,而是直接將「目標長度」作為輸入條件 $p$ 餵給模型。
- 數學定義:時長 Embedding $p$ 計算公式為: $$\begin{align*} p = W_{num}h(T) \end{align*}$$ 其中 $T$ 是目標語義 Token 的總長度,$h(T)$ 是將 $T$ 轉為 One-hot 向量的函數,$W_{num}$ 是一個 Embedding Table。
- 關鍵 Trick ($W_{sem} = W_{num}$):論文中使用了一個特殊的技巧,強制讓「時長 Embedding Table ($W_{num}$)」與「語義位置 Embedding Table ($W_{sem}$)」共享權重(Weight Sharing)。
- 技術意義:這在數學上強制模型將「目標總長度資訊」與「序列的位置資訊」對齊。這讓自回歸系統能夠精確感知「我現在生成到第幾個 Token」以及「我總共應該生成幾個 Token」,從而精確地在指定長度結束生成 。
- 推論模式 :
- 指定時長模式:輸入具體的 $T$ 計算 $p$,模型會生成精確長度的語音。
- 自由生成模式:輸入 $p=0$,模型將自動決定長度(類似傳統 AR TTS)。
情感與音色的解耦 (Emotion & Timbre Disentanglement)
為了讓模型能用「A 的聲音」講出「B 的情感」,T2S 必須確保提取的情感特徵 $e$ 裡面不包含說話者的音色資訊。
- 雙編碼器架構:
- Speaker Perceiver Conditioner:提取 $c$,專注於說話者的音色。被動依賴 Pre-trained 模型 的強健性,並透過 Freeze 防止其變質。(極有可能是作者團隊利用 55k 小時數據自行預訓練的內部組件,而非直接調用通用的開源模型)
- Emotion Perceiver Conditioner:從 Style Prompt 提取 $e$,專注於情感韻律。主動使用 GRL,強制去除說話者資訊,防止 $e$ 偷看 $c$ 的答案。
- 梯度反轉層 (Gradient Reversal Layer, GRL):這是在訓練階段使用的關鍵技術。
- 機制:在 Emotion Conditioner 後面接一個 GRL 和一個 Speaker Classifier(說話者分類器)。
- 目的:Speaker Classifier 試圖從 $e$ 中分辨出是哪個說話者,而 GRL 會在反向傳播時將梯度取負號。這迫使 Emotion Conditioner 去「欺騙」分類器,也就是學會去除 $e$ 裡面的說話者身分資訊。
- 結果:最終得到的 $e$ 只包含純粹的情感與韻律,與說話者無關,實現了完美的解耦。
三階段訓練策略 (Three-Stage Training Strategy)
為了讓上述機制穩定運作,T2S 模組並非一次訓練完成,而是分為三個階段 :
- Stage 1 (基礎能力建立):
- 使用完整數據集訓練。
- 關鍵操作:以 30% 的機率隨機將時長向量 $p$ 設為 0。這讓模型同時學會「依指令控制長度」和「自由生成」兩種能力。
- Stage 2 (情感解耦與細化):
- 輸入改為 $[c+e, \dots]$。
- Freeze 操作:凍結 Speaker Perceiver Conditioner ($c$),只訓練 Emotion Perceiver Conditioner ($e$)。
- 加入 GRL:此階段引入 GRL 進行對抗式訓練,專門優化情感特徵的純淨度 。
- 數據:使用 135 小時的高品質情感數據子集 。
- Stage 3 (整體微調):
- 凍結所有特徵提取器 (Conditioners),對 T2S 主體進行全量數據微調,提升整體魯棒性 。
總結來說,T2S 模組透過權重共享的 Embedding 解決了 AR 模型的長度控制問題,並透過 GRL 對抗訓練 解決了情感與音色糾纏的問題,是 IndexTTS2 最具技術含量的部分之一。
Semantic-to-Mel (S2M) 模組
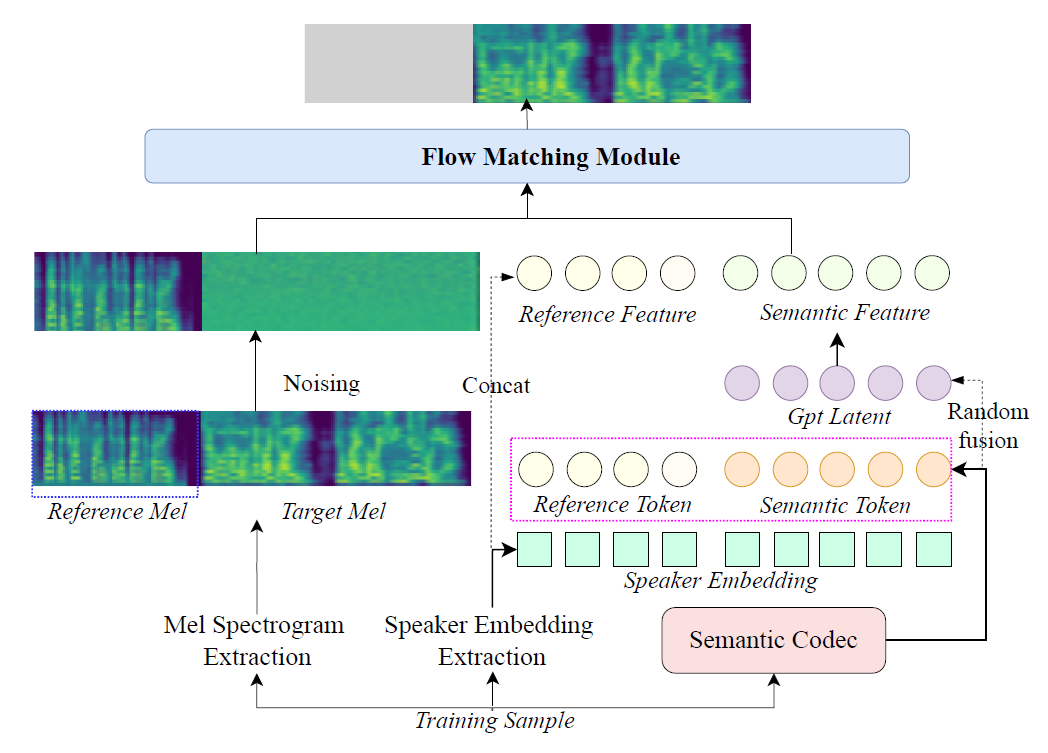 上圖為 training/inference 階段的圖
上圖為 training/inference 階段的圖
(人類): 其中 reference token 應該是用 T2S 模組 (吃 reference Mel) 產生出來的, 而 reference feature 指的是將 reference token 跟 speaker embedding concat 後的結果.
Speaker embeddings 是透過 speaker perceiver-based conditioner 抽取得到的
Guided CFM 的 “Guided” 部分為 Reference Mel + Reference Feature + Semantic Feature
- Reference Mel
- Reference Feature: reference token concate with speaker embedding
- Semantic Feature: semantic token fused with GPT latent then concate with speaker embedding
(人類): 具體可能要看 codes 怎麼寫, 這邊只看 paper 可能不準
CFM loss 選用 L1-norm (Target Mel $y_{tar}$ V.S. CFM predicted Mel $y_{pred}$), (CFM loss codes 片段, 或論文中 eq (2) 的描述)
$$\begin{align*} \mathcal{L}_{L1} = \frac{1}{F \cdot D} \sum_{f=1}^{F} \sum_{d=1}^{D} |(y_{pred}){f,d} - (y_{tar})_{f,d}| \end{align*}$$ (人類): 訓練完後, inference 就是解 ODE 了, 這邊就沒啥好說, 自行參考筆記
(人類): 一般來說 CFM 選用的是 L2-norm, 這能數學上保證 CFM 等價於 FM, 但也能推導如果用 L1-norm 則 CFM loss $\geq$ FM loss (參考)
因此最小化 CFM 也能盡量讓 FM 變小
L2 Loss (MSE) 傾向於懲罰大誤差,容易導致生成的頻譜圖過於平滑(模糊),因為它在平均化不確定性。L1 Loss (MAE) 對異常值較不敏感,能保留更多高頻細節(頻譜紋理),這對語音的清晰度和音質至關重要 。
Text-to-Emotion (T2E) 模組 (輔助功能)
這是一個非常巧妙的模組,它體現了目前 AI 領域將 Large Language Models (LLM) 的語義理解能力「跨界」應用到 Speech Synthesis 任務的趨勢。
Text-to-Emotion (T2E) 模組的目標是:讓使用者可以直接用自然語言(例如:「請用一種壓抑且帶有恐懼的語氣說…」)來控制語音的情感,而不需要提供一個真實的「恐懼錄音檔」作為參考
以下是 T2E 模組的詳細運作流程與技術拆解:
核心概念:從「文字描述」到「情感向量」的映射
T2E 並不是直接生成語音,而是充當一個「翻譯官」。它將人類的文字指令翻譯成 T2S 模組看得懂的 情感嵌入向量 (Emotion Embedding, $e$)。
為了實現這一點,IndexTTS2 採用了一種 「Teacher-Student 知識蒸餾 (Knowledge Distillation)」 的策略,將超大模型(Deepseek-r1)的推理能力濃縮到輕量級模型(Qwen-3-1.7b)中 。
詳細運作步驟
Step 1: 建立情感的聲學錨點 (Acoustic Anchors)
首先,系統定義了 7 種基本情感:憤怒、快樂、恐懼、厭惡、悲傷、驚訝、中性 ( $\mathcal{E} = \{Anger, Happiness, \dots, Neutral\}$ ) 。
- 作法:從真實錄音數據中,挑選這 7 種情感的代表性音檔。
- 提取:使用 T2S 模組中預訓練好的 Emotion Perceiver Conditioner,從這些音檔中提取出固定的 Embeddings。
- 結果:形成一個固定的「情感嵌入集合」$V$,可以視為情感空間中的 7 個基準座標 。
Step 2: Teacher Model 生成「軟標籤」 (Soft Labels)
利用 Deepseek-r1 強大的文本理解能力,將文字描述映射為機率分佈 。
- 輸入:文字描述 $t$(例如 “His voice trembled with fear”)。
- 輸出:一個 7 維的機率分佈向量 $p$(例如:[0.8 恐懼, 0.1 悲傷, 0.1 中性, …]),且總和為 1。
- 數據生成:作者使用 Deepseek-r1 生成了 1000 筆訓練資料,包含「描述性文本」和「劇本式文本」,並要求 Deepseek-r1 自行標註這 7 種情感的機率 。
Step 3: Student Model 的蒸餾與微調 (Distillation via LoRA)
為了推論效率,不能每次都跑 Deepseek-r1。因此,作者訓練了一個較小的 Qwen-3-1.7b 來模仿老師的行為。
- 技術:使用 LoRA (Low-Rank Adaptation) 進行微調 。
- Loss Function:最小化 Student 預測分佈與 Teacher 生成分佈之間的 Cross-Entropy Loss 。
- 目的:讓 Qwen-3-1.7b 能夠根據輸入文字,快速且準確地預測出那 7 個情感的混合比例 。
Step 4: 向量加權融合 (Weighted Average)
這是最關鍵的一步,將「語義機率」轉為「聲學向量」。
- 計算:最終輸入給 T2S 的情感向量 $e_{input}$,是上述 7 個基準情感向量 $V$ 的加權平均。
- 公式:其中 $p_i$ 是 Qwen 預測的第 $i$ 個情感的機率, $v_i$ 是第 $i$ 個情感的聲學 Embedding。
$$\begin{align*} e_{input} = \sum_{i=1}^{7} p_i \cdot v_i \end{align*}$$.
為什麼這個設計很聰明?
- 解決了數據標註困難:
要收集「帶有精確情感強度標籤(例如:70% 快樂 + 30% 驚訝)」的語音數據極其困難。這個方法利用 LLM 的常識推理來「憑空創造」出這些細膩的標籤。 - 支援混合情感 (Mixed Emotions):
因為輸出的是機率分佈 $p$,而非單一類別(One-hot),系統可以合成出「苦笑」(悲傷+快樂)或「驚喜」(驚訝+快樂)等複雜情感,透過向量加權平均實現平滑過渡。 - 推論效率與部署 (Model Compression):
這直接對應到您職缺中的「模型壓縮」與「實務經驗」。將 Deepseek 的能力蒸餾到 Qwen-1.7b,並通過 LoRA 實現,是極具實用價值的工程決策。
與 T2S 模組的介面
最終產生的 $e_{input}$ 會被當作一個普通的 Emotion Embedding,直接餵給 T2S 模組(取代原本由音檔提取的 $e$)。對 T2S 來說,它分不清楚這個向量是來自真實音檔,還是由 LLM「想像」出來的,它只負責將其還原為對應的韻律。
實驗數據和結論
以下是 IndexTTS2 論文的實驗數據重點與最終結論整理:
實驗設置 (Experimental Setup)
為了證明模型的強大,作者使用了大規模的數據和多個強力的 Baseline 進行比較:
- 訓練數據龐大:使用了總計 55,000 小時 的數據(30k 中文 + 25k 英文),主要來自 Emilia 數據集與內部購買的有聲書數據 。其中包含 135 小時 的高品質情感數據 。
- 強勁的對手 (Baselines):比較了目前市面上最強的 Zero-shot TTS 模型,包括:
- MaskGCT & F5-TTS (非自回歸 NAR 的代表) 。
- CosyVoice2 & SparkTTS (自回歸 AR 的代表) 。
- IndexTTS (v1) (作者團隊的前一代模型) 。
- 評估指標:
- 客觀指標:WER (字錯率)、SS (語者相似度)、ES (情感相似度) 。
- 主觀指標 (MOS):SMOS (相似度)、PMOS (韻律)、QMOS (音質)、EMOS (情感還原度) 。
關鍵實驗結果 (Key Results)
A. 基礎能力:全面領先,但在 WER 上略有取捨
在標準測試集(LibriSpeech, SeedTTS 等)上:
- 綜合表現:IndexTTS2 在大部分客觀指標上都達到了 SOTA 。
- 主觀聽感:在主觀評測中,IndexTTS2 幾乎在所有 Baseline 中勝出 。
- 與前代比較:相比 IndexTTS (v1),v2 在某些 WER 指標上略高(例如 SeedTTS-en),但換來的是更強的語者相似度 (SS) 和情感表現 。
B. 情感表現 (Emotional Performance):壓倒性勝利
這是本論文最大的亮點(見論文 Table 2):
- 數據證明:在情感測試集上,IndexTTS2 在所有主觀指標(SMOS, EMOS, PMOS, QMOS)都拿到了最高分 。
- 對手弱點:MaskGCT 和 F5-TTS 雖然音質好,但在情感表達(EMOS)上明顯不如 IndexTTS2 。
- 清晰度維持:雖然情感強烈時容易發音不清,但 IndexTTS2 透過 GPT Latent 增強,將 WER 控制在非常有競爭力的範圍 (1.883%),遠優於 MaskGCT (4.059%) 。
C. 時長控制 (Duration Control):精確度極高
驗證 $W{sem} = W{num}$ 機制的有效性(見論文 Table 4 & Figure 4):
- 誤差率極低:在指定時長生成的任務中,Token數量的誤差率小於 0.02% 。
- 伸縮自如:即使將語速強制縮放(0.75x 到 1.25x),WER 的增加也非常微小,且優於 MaskGCT 。
- 韻律優勢:在控制時長的情況下,IndexTTS2 的韻律表現 (PMOS) 依然優於非自回歸模型 (F5-TTS/MaskGCT) 。
D. 消融研究 (Ablation Studies):GPT Latent 的必要性
作者測試了移除 S2M 模組中的 GPT Latent Enhancement 會發生什麼事:
- 結果:移除後,WER 上升(發音變差),且所有主觀評分(MOS)都下降 。
- 結論:證明了引入 T2S 的 GPT Latent 對於在「高情感強度」下維持「發音清晰度」至關重要 。
論文結論 (Conclusion)
IndexTTS2 的結論非常有力,它宣稱解決了自回歸 TTS 長久以來的痛點:
- 首創的 AR 時長控制:它是第一個結合了「精確時長控制」與「自然生成」的自回歸 Zero-shot TTS 模型 。
- 解耦與情感 SOTA:透過 GRL 和多階段訓練,成功將情感與音色解耦,並在情感還原度上達到 SOTA 水準 。
- 應用價值:由於能精確控制時間且情感豐富,它非常適合用於自動配音 (AI Dubbing) 和影視解說等對「影音同步」有嚴格要求的場景 。