整理下 entropy 的一些東西, 不然久沒看老是忘記.
- Entropy of a r.v. $X$: $H(X)$
- Conditional Entropy of $Y$ given $X$: $H(Y|X)$
- Cross(Relative) Entropy of two pdf, $p$ and $q$: $D(p\Vert q)$
- Mutual Information of two r.v.s: $I(X;Y)$
文章會明確定義每一項, 然後在推導它們之間關係的同時會解釋其物理意義.
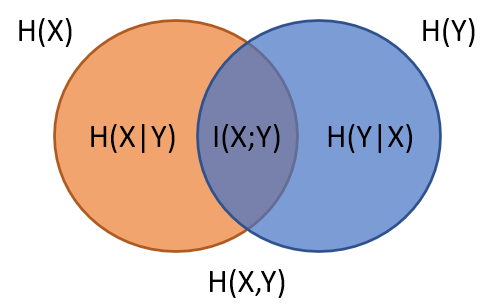
最後其實就可以整理成類似集合關係的圖 (wiki)