不打算長篇大論, 精簡聊一下 SpinQuant 這篇論文, 來杯咖啡 ☕ 開始吧.
從前面一篇 blog “隨機旋轉的量化魔法: 去去極值走” 我們知道隨機旋轉可以把 outlier 去除, 或甚至旋轉矩陣直接針對 loss 用學的 (本篇 SpinQuant 的作法, 使用 Cayley SGD 去學)
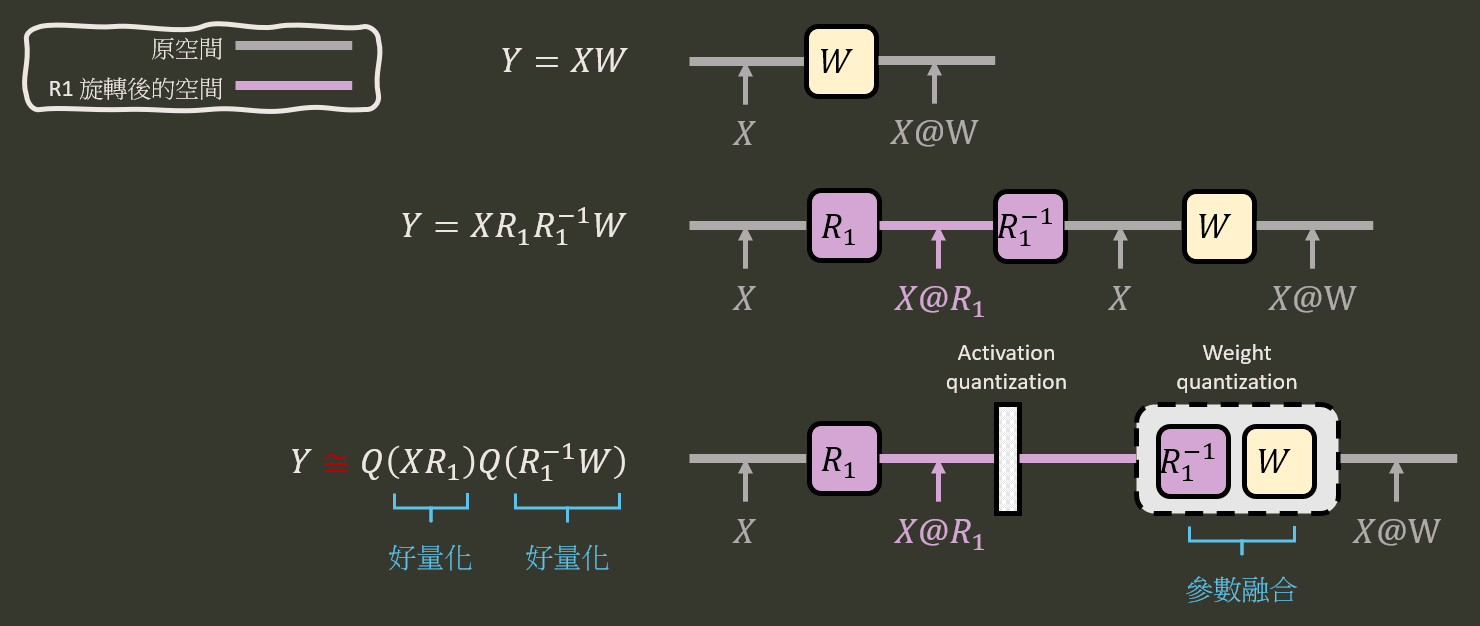
針對一個簡單的線性層 $Y=XW$ (這裡使用右乘), 我們使用一個正交矩陣 $R$ 同時對 input activation $X$ 和 weight $W$ 旋轉, 讓他們同時好量化:
$$\begin{align}
Y &=XW=(XR)(R^TW) \\
&\approx Q(XR)Q(R^TW)
\end{align}$$ 其中 $Q(\cdot)$ 表示量化 op. 對照參考下圖應該不難理解
 那麼接著來看看 SpinQuant 全架構的旋轉量化圖
那麼接著來看看 SpinQuant 全架構的旋轉量化圖
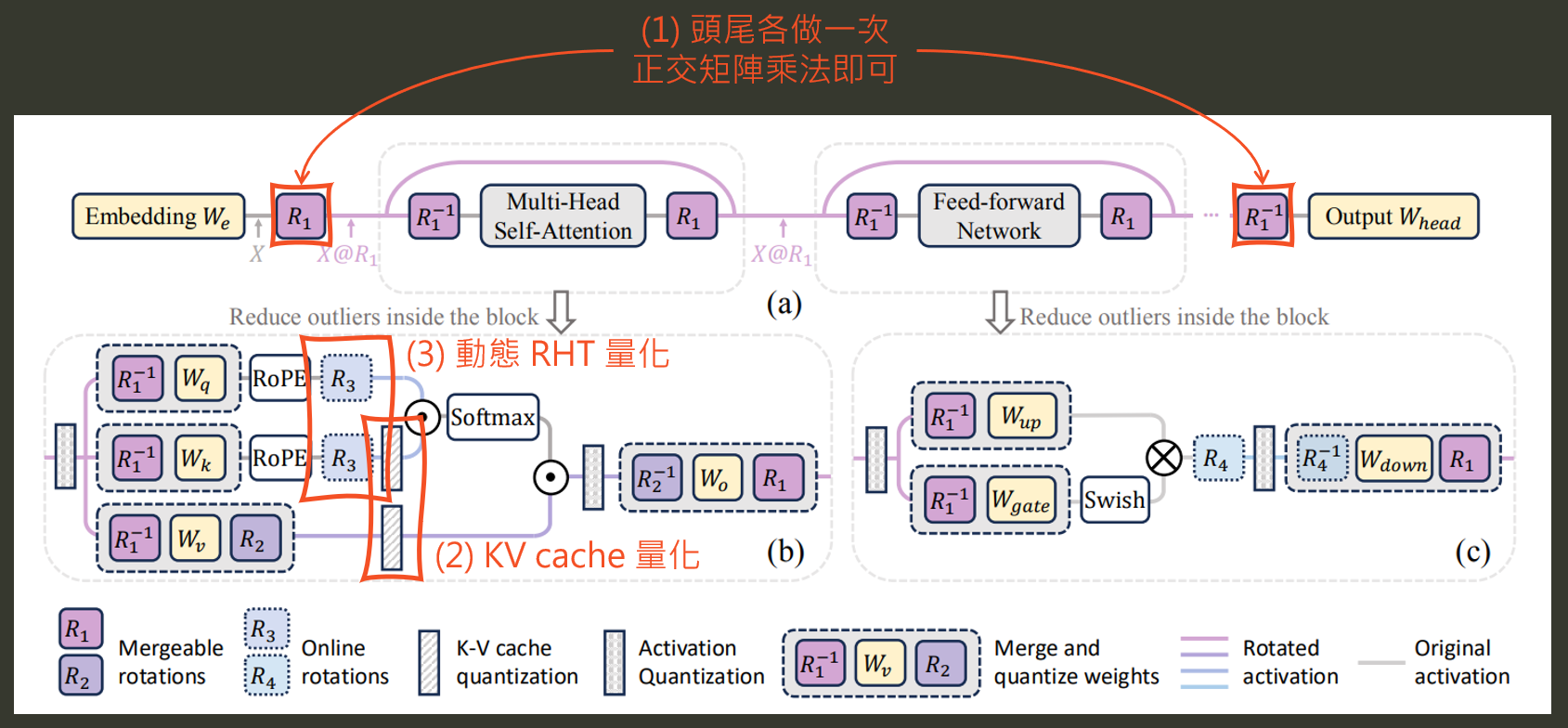 共有 4 種旋轉矩陣 $\{R_1,R_2\}$ 是事先用 Cayley SGD 透過 calibration data 學出來的, 而 $\{R_3,R_4\}$ 則是隨機選擇一個 Random hadamard Transform 矩陣 (選好後固定下來):
共有 4 種旋轉矩陣 $\{R_1,R_2\}$ 是事先用 Cayley SGD 透過 calibration data 學出來的, 而 $\{R_3,R_4\}$ 則是隨機選擇一個 Random hadamard Transform 矩陣 (選好後固定下來):
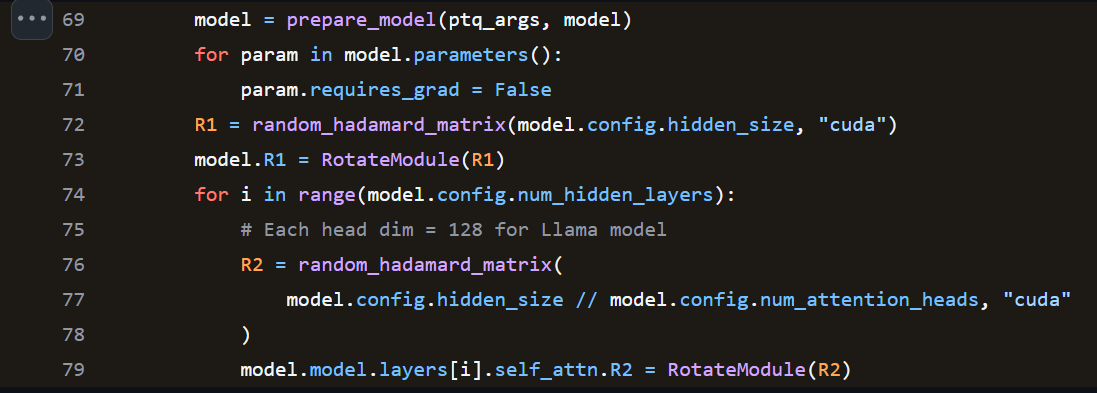
- 注意到 $R_1$ 是所有 attention layers 共同 share 的, 而 $R_2$ 則是每層 layers 都有自己的參數. (參考官方 codes: line 69~79)
- 只有頭尾需要做一次 $R_1$ 和 $R_1^{T}$ 的矩陣乘法就好, 中間的空間都已經是經過 $R_1$ 旋轉後的空間
- $R_3$ 同時作用在 query $q$ 和 key $k$, 這是因為正交矩陣 “保內積”, i.e. $\langle q,k \rangle = \langle Rq,Rk \rangle$.
雖然我們之前已經探討過隨機旋轉就夠好了, 數學保證了有很大的機率不會有 outliers (QuIP 論文)
但 SpinQuant 論文提到 $\{R_1,R_2\}$ 直接用學的更穩定: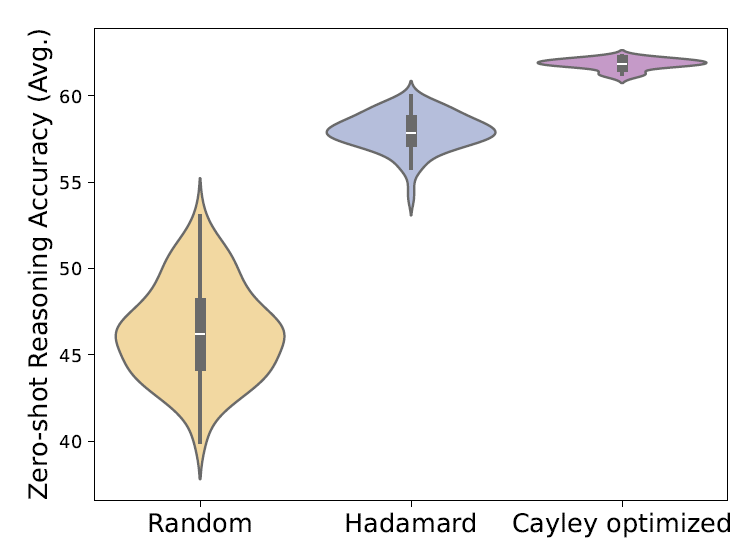
另外還記得 26 年 4 月 Google 發表 TurboQuant, 壓縮推論需要的記憶體需求, 直接讓記憶體類股的股價下跌這件事嗎?
這也跟旋轉量化有關, 其中有一步也是利用隨機旋轉矩陣 (論文裡稱 PolarQuant)
有趣的是, 可以證明隨機旋轉後, 投影到的每個維度互相獨立且必為 Beta 分佈.
既然已知必定為 Beta 分布, 那就可以事先決定好最佳的量化參數了.
利用這種做法 (加其他步驟) Google 對 KV cache 做到極大的量化!
最後再補充另一種量化技術稱 PrefixQuant, 也是針對 KV-cache 壓縮.
他們觀察到如同 attention sink 的現象, outliers 都集中在某些無意義的 tokens, 那麼將這些 token 的 kv cache 獨立出來當成 prefix tokens 並保留全精度. 其他所有 tokens 都可以很好的量化了.
從這也可以看到 PrefixQuant 是 token-wise level, 而非 SpinQuant/QuIP/AWQ 的 channel-wise level 的量化方法.
LLM PTQ 真的愈來愈神了, 原本我認為 PTQ 無法做到多好的刻板印象看來要更新更新
真的太神了, 不禁想再感嘆一次~