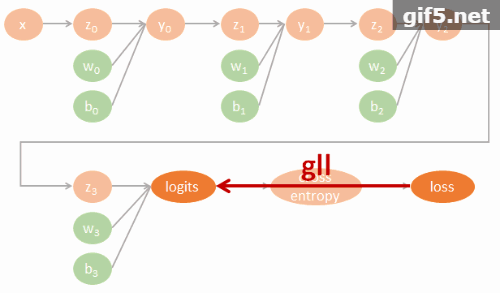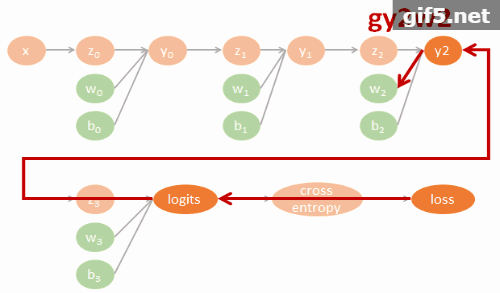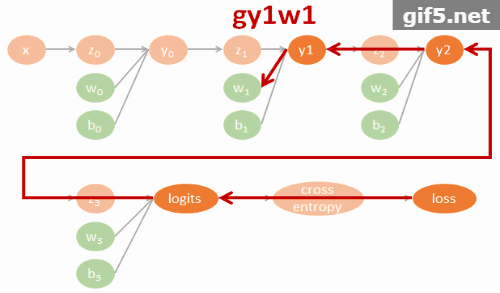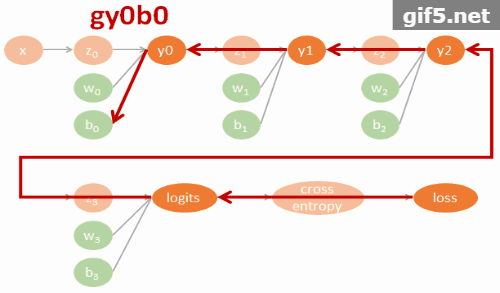
小筆記. Tensorflow 裡實作的 GRU 跟 Colah’s blog 描述的 GRU 有些不太一樣. 所以做了一下 TF 的 GRU 結構. 圖比較醜, 我盡力了… XD
TF 的 GRU 結構

u 可以想成是原來 LSTM 的 forget gate, 而 c 表示要在 memory cell 中需要記住的內容. 這個要記住的內容簡單講是用一個 gate (r) 來控制之前的 state 有多少比例保留, concate input 後做 activation transform 後得到. 可以對照下面 tf source codes.