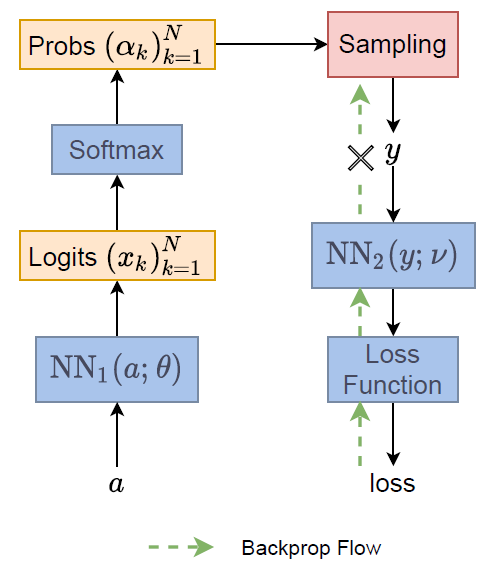
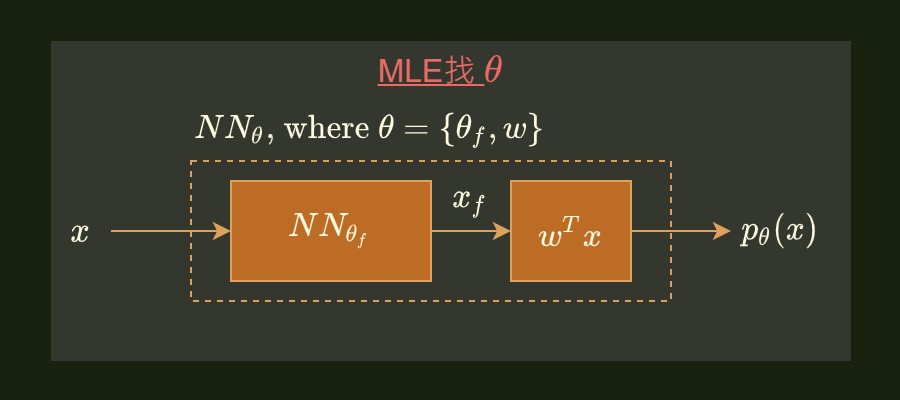
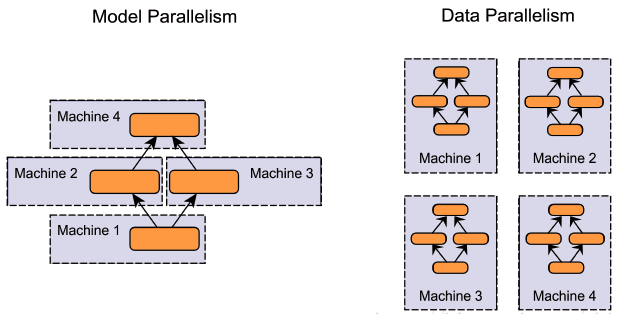
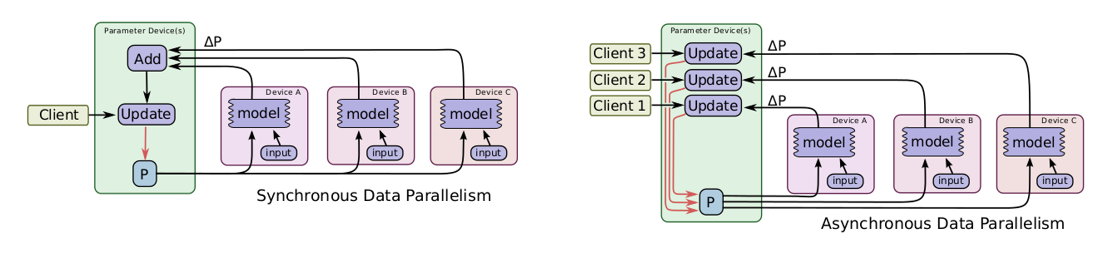
Coursera Stochastic Processes 課程筆記, 共十篇:
- Week 0: 一些預備知識
- Week 1: Introduction & Renewal processes
- Week 2: Poisson Processes
- Week3: Markov Chains
- Week 4: Gaussian Processes (本文)
- Week 5: Stationarity and Linear filters
- Week 6: Ergodicity, differentiability, continuity
- Week 7: Stochastic integration & Itô formula
- Week 8: Lévy processes
- 整理隨機過程的連續性、微分、積分和Brownian Motion