為了學習 TF2.x 只好把以前練習的一些 projects 重寫一次, 但後來時間斷斷續續的, 所以只做了一部分. 總之先記錄一下目前的練習進度吧.
CTC Model and Loss
CTC model 是一個 decoder 部分為簡單的 (independent) linear classifer 的 seq2seq model. 因此 input frame 有 $T$ 個, 就會有 $T$ 個 output distribution vectors.
正常來說 (ex: ASR) output token 數量 $N<T$, 所以會有 alignment 問題. 以往的 alignment (HMM) 強迫每個 frame index 都需對應到一個 phone’s state, 但 CTC 允許對應到 “空” 的 state (null or blank). 這讓 CTC 的 alignment 比 HMM 更有彈性.
RNN-T 是另一種比 CTC 更有彈性的 alignment 表達方式.
CTC 的 gradient 可以非常有效率的用 dynamic programming 求得 (forward/backward 演算法, 下圖). 因此採用 gradient-based optimization 方法就很合適.
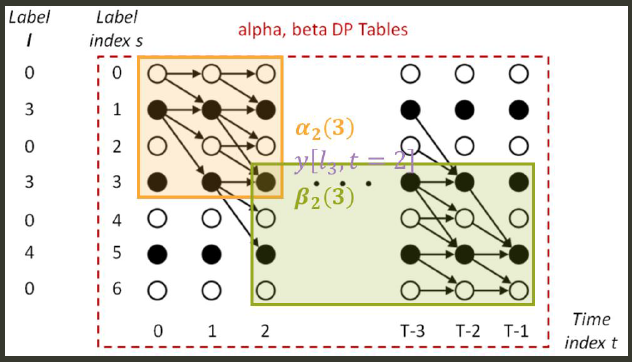
本文會詳細介紹上面提到的幾點. Decoding 部分不介紹.
Exp of Adversarial Domain Adaptation
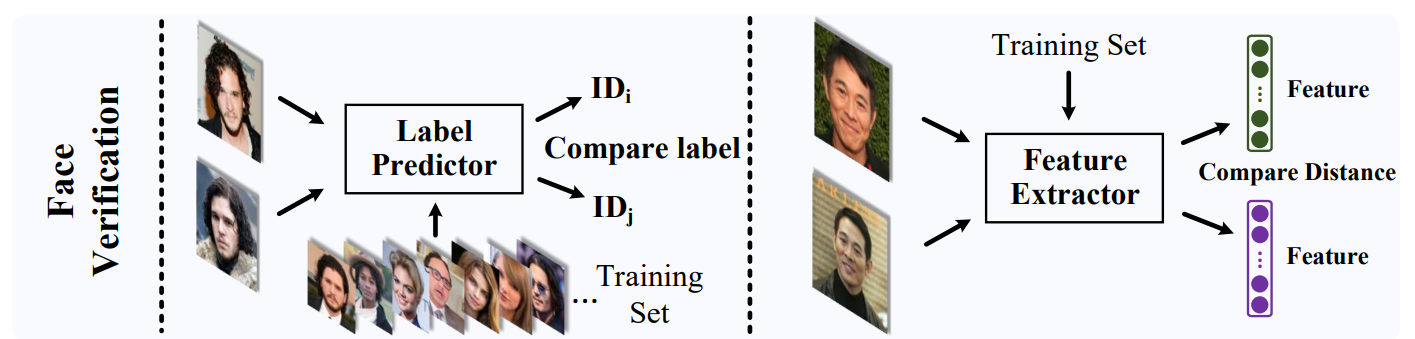
Domain Adaptation 是希望在 source domain 有 label 但是 target domain 無 label 的情況下, 能針對 target domain (或同時也能對 source domain) 進行分類任務. “Adversarial” 的意思是利用 GAN 的 “對抗” 想法: Label predictor 雖然只能保證 source domain 的分類. 但由於我們把 feature 用 GAN 消除了 domain 之間的差異, 因此我們才能期望這時候的 source domain classifier 也能作用在 target domain.
這篇文章 張文彥, 開頭的圖傳達的意思很精確, 請點進去參考.
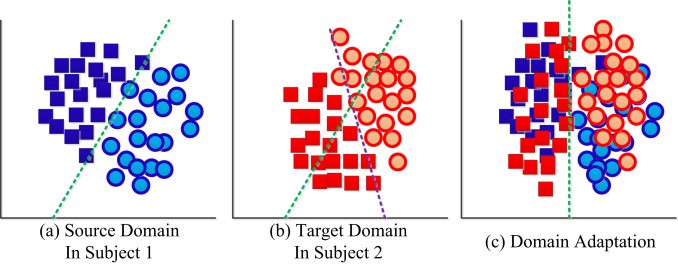
接著嘗試複現了一次 Domain-Adversarial Training of Neural Networks 的 mnist(source) to mnist_m(target) 的實驗.
Framework of GAN
說來汗顏, 自從17年三月筆記完 WGAN 後, 就沒再碰 GAN 相關的東西了. 惡補了一下 李宏毅GAN 的課程和其他相關資料, 因此筆記一下.
MMGAN(最原始的GAN), NSGAN(跟MMGAN差別在 G 的 update 目標函式有點不同), f-GAN, WGAN, ADDA (Adversarial Discriminative Domain Adaptation), infoGAN, VAE-GAN 等… 這些全部都是 follow 下面這樣的 framework:
$$\begin{align} Div\left(P_d\|P_G\right) = \max_D\left[ E_{x\sim P_d} D(x) - E_{x\sim P_G}f^*(D(x)) \right] \\ G^*=\arg\min_G{Div\left(P_d\|P_G\right)} + reg(G) \\ \end{align}$$其中 $P_d$ 為 real data pdf, $P_G$ 為 generator 產生的 data pdf. $f^*$ 帶入不同的定義會產生不同的 divergence, 這之後會再說明.
式 (1) 定義了 $P_G$ 與 $P_d$ 的 divergence, 其中這個 divergence 的值為藉由解這個最佳化問題求得的.
式 (2) 表示要找的 $G$ 就是 divergence 最小的那個. Divergence 最小 ($=0$) 同時也表示 $P_G=P_d$ (生成器鍊成). 如果同時考慮 regularization term, $reg(G)$, 則會有很多變化產生, 如 ADDA, infoGAN, VAE-GAN…
我們接著來看 MMGAN, NSGAN, f-GAN, WGAN, ADDA, infoGAN, VAE-GAN 這些怎麼 fit 進這個框架.
Notes for (conditional/cross-)Entropy, Mutual-information, ...
整理下 entropy 的一些東西, 不然久沒看老是忘記.
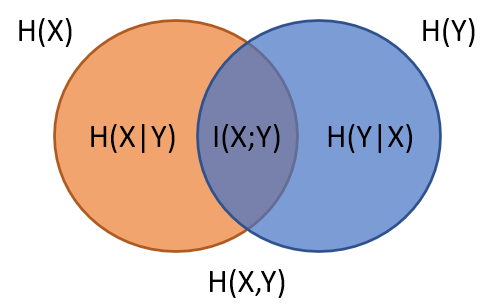
- Entropy of a r.v. $X$: $H(X)$
- Conditional Entropy of $Y$ given $X$: $H(Y|X)$
- Cross(Relative) Entropy of two pdf, $p$ and $q$: $D(p\Vert q)$
- Mutual Information of two r.v.s: $I(X;Y)$
文章會明確定義每一項, 然後在推導它們之間關係的同時會解釋其物理意義.
最後其實就可以整理成類似集合關係的圖 (wiki)
Determinant of Covariance Matrix
筆記 covariance matrix $R$ 的 determinant 意義以及他的 bound. 這是在讀 Time-delay estimation via linear interpolation and cross correlation 時的 appendix 證明. 覺得有用就筆記下來.
開門見山, $det(R)$ 可以想成 volumn (等於所有 eigenvalues 相乘), 然後 upper bound 就是所有對角項元素相乘.
$$\begin{align} det(R)=\prod_i \lambda_i \leq \prod_i r_{ii} \end{align}$$$\lambda_i$ 是 i-th eingenvalue.
事實上只要 $R$ 是 square matrix, 則 $|det(R)|$ 等於用每個 row vector 做出來的 “平行六面體” 的體積 [ref]
以下筆記論文中證明 $det(R)$ 的 upper bound, 從這個 bound 我們也能看出物理意義.
TF Notes (6), Candidate Sampling, Sampled Softmax Loss
NN 做分類最後一層通常使用 softmax loss, 但如果類別數量很大會導致計算 softmax 的 cost 太高, 這樣會讓訓練變得很慢. 假如總共的 class 數量是 10000 個, candidate sampling 的想法就是對於一個 input $x$ 採樣出一個 subset (當然需要包含正確的 label), 譬如只用 50 個 classes, 扣掉正確的那個 class, 剩下的 49 個 classes 從 9999 個採樣出來. 然後計算 softmax 只在那 50 個計算. 那麼問題來了, 這樣的採樣方式最終訓練出來的 logits 會是對的嗎? 它與未採樣前 (full set) 的 logtis 有何對應關係?
SphereFace Paper Study and Implementation Notes
SphereFace: Deep Hypersphere Embedding for Face Recognition 使得訓練出來的 embeddings 可以很好的使用 cosine similarity 做 verification/identification. 可以先網路上搜尋一下其他人的筆記和討論, 當然直接看論文最好.
一般來說我們對訓練集的每個人用 classification 的方式訓練出 embeddings, 然後在測試的時候可以對比兩個人的 embeddings 來判斷是否為同一個人. 使用 verification 當例子, 實用上測試的人不會出現在訓練集中, 此情形稱為 openset 設定.
Adaptive Filters 簡介 (2) Fast Convolution and Frequency Domain
上一篇說明了 time domain 的 adaptive filters, 由於是 sample-by-sample 處理, 因此太慢了不可用, 真正可用的都是基於 frequency domain. 不過在深入之前, 一定要先了解 convolution 在 input 為 block-by-block 的情況下如何加速. 本文內容主要參考 Partitioned convolution algorithms for real-time auralization by Frank Wefers (書的介紹十分詳盡).
Convolution 分類如下: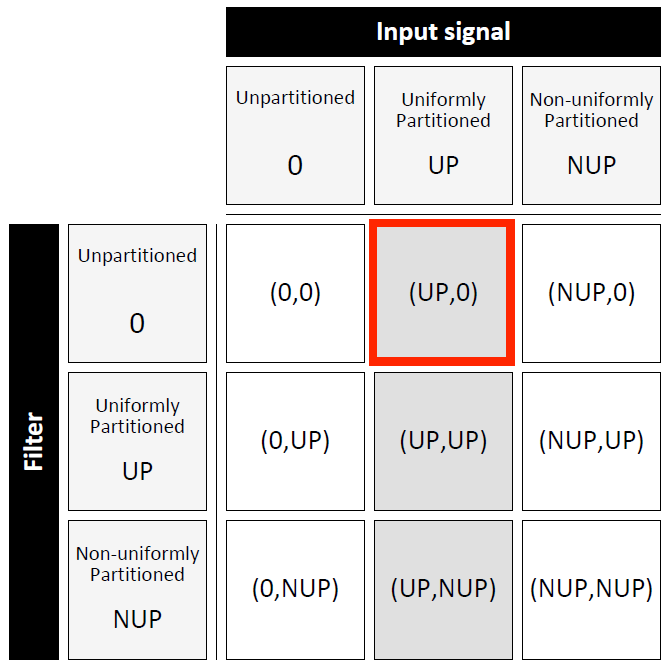
我們就針對最常使用的情形介紹: Input (UP) and Filter (0).
這是因為實際應用 input 是 infinite length, 所以需要 block-by-block 給定, 而 filter 通常都是 finite length, 可以選擇不 partition, 或 uniformly partitioned 以便得到更低的延遲效果.
針對 block-based input 的 convolution, 我們有兩種架構:
- OverLap-and-Add (OLA)
- OverLap-and-Save (OLS)
Adaptive Filters 簡介 (1) Time Domain
粗略筆記 time domain adaptive filters, frequency domain adaptive filters 會在下一篇筆記. 應用以 Acoustic Echo Cancellation (AEC) 來說明.
Motivation
直接使用 wiki. AEC 要解決的是如下的情形