這是初探最優傳輸 OT (Optimal Transport) 的第一篇, 聊一下這是什麼問題以及傳統利用 Linear Programming 的解法
[備註 1]:圖片改自此 jupyter notebook: wasserstein-notebook/Wasserstein_Kantorovich.ipynb
[備註 2]:在離散情況下 Earth Mover’s Distance (EMD) / Optimal Transport / Wasserstein distance 指同一件事情, 文章在不混淆情況下有時會混用
什麼是 Earth Mover’s Distance (EMD) 推土機距離?
Earth Mover’s Distance (EMD) 有一個很形象的描述叫做推土機距離.
想像兩個機率分布 ($P_s$, $P_t$) 是形狀不同的兩個土堆. 將源分布 $P_s$ 改造成目標分布 $P_t$ 所需的最小搬運代價即為 EMD.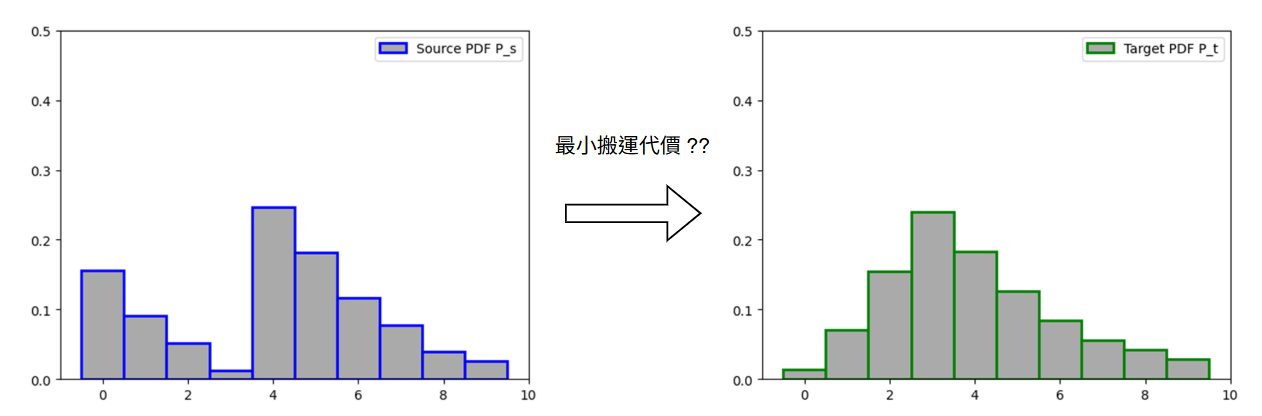
搬運代價直覺上這麼定義: 代價 = 搬運質量 $\times$ 搬運距離. 所以單位質量的代價就是搬運距離, 代價矩陣畫出來如下圖左: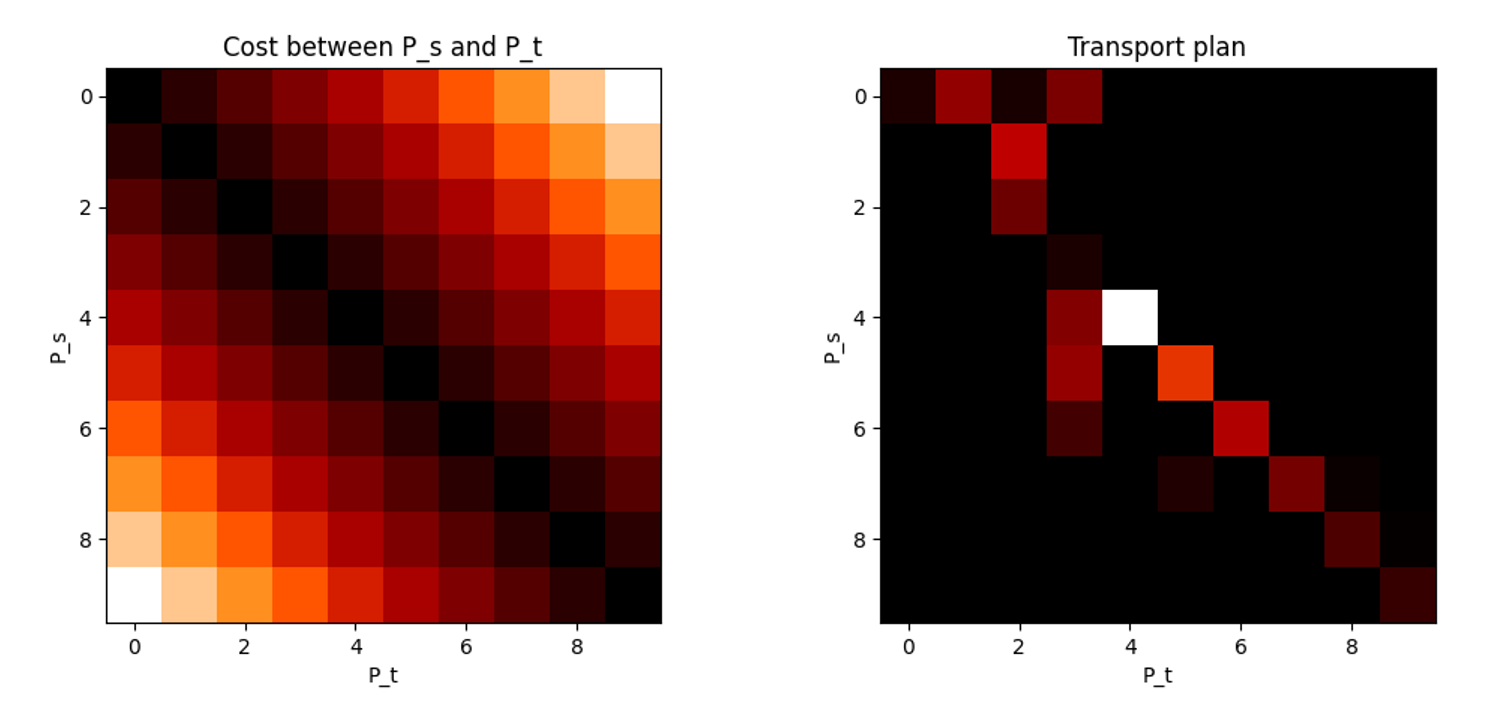 而上圖右則顯示最佳搬運計畫, 以傳輸矩陣的方式表達, 其中矩陣的 $(i,j)$ 的值表示要把 $P_s$ 在 index $i$ 搬運多少土到 index $j$ 的位置. 整個搬運完後就變成目標分布 $P_t$.
而上圖右則顯示最佳搬運計畫, 以傳輸矩陣的方式表達, 其中矩陣的 $(i,j)$ 的值表示要把 $P_s$ 在 index $i$ 搬運多少土到 index $j$ 的位置. 整個搬運完後就變成目標分布 $P_t$.
下圖展示根據最佳搬運計畫從源分布到目標分布的土堆搬運情況: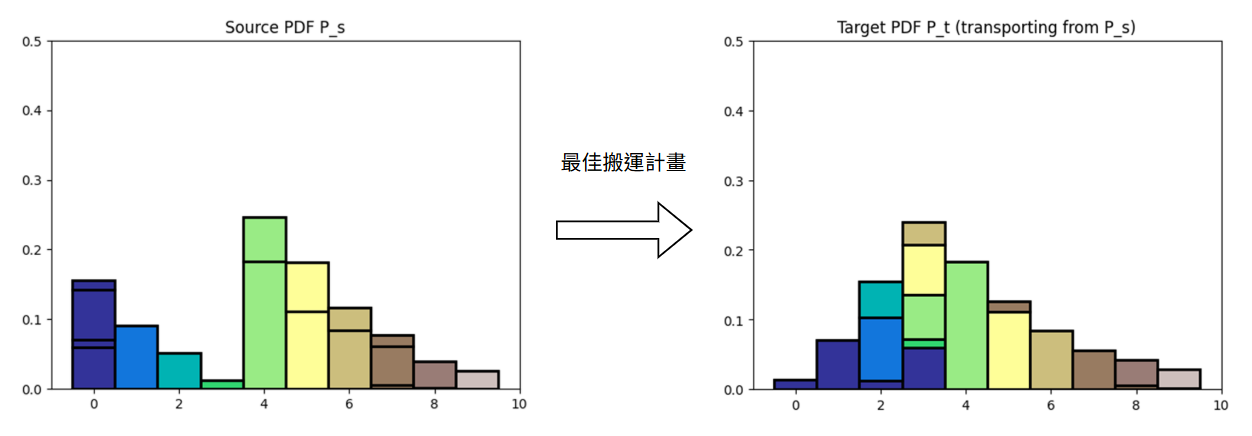
我們為什麼需要 EMD 距離?
我想藉由兩方面來說明什麼情況下需要 EMD 距離, 或是 Optimal Transport (OT) 距離
$\circ$ “幾何感知“ 的需求 (Geometry Awareness)
$\circ$ 兩個分佈的 Support (支撐集) 不重疊
“幾何感知” 的需求 (Geometry Awareness)
一般來說我們最常用 KL-divergence 來計算兩個分布的距離
如果我們的問題是分類任務, 假設是一隻 ”狗” 的圖片好了, 此時模型預測成 “貓” 跟預測成 “飛機”
這兩種錯誤在分類任務中沒有區別, 因此當標籤之間沒有幾何關係, KL 就足夠好了
再看另一個情況, 假設我們要生成人臉, 正確答案的眼睛在座標 (10, 10), 而模型生成兩種眼睛位置分別是 (11, 11) 和 (100, 100).
此時兩種錯誤就有好壞之分了. 使用 EMD 知道從 (11, 11) 搬運到 (10, 10) 的代價比起從 (100, 100) 要小的多, 因此 (11, 11) 會是比較好的預測.
兩個分佈的 Support (支撐集) 不重疊
我們考慮兩個常見的 distribution distance, KL divergence 和 JSD (Jensen-Shannon Divergence).
先看 KL divergence:
$$\begin{align*}
D_{KL}(P \parallel Q) = \int_{x \in \text{supp}(P)} p(x) \log \frac{p(x)}{q(x)} dx
\end{align*}$$ 當兩個分布 $P,Q$ 的 support sets 不重疊, 意思是對一個 $x$ 來說, 如果一個分布的 density $>0$ 則另一個分布的 density 一定 $=0$.
此時很容易看到 $D_{KL}=\infty$, loss 失去作用了.
這種 support 不重疊的情況可能比我們想得更容易發生, 尤其在高維度的分布情況下.
換一個 distance, JSD (Jensen-Shannon Divergence) 來觀察
JSD 的定義是基於 KL 散度的對稱化版本:
$$\begin{align*}
JSD(P \parallel Q) = \frac{1}{2} D_{KL}(P \parallel M) + \frac{1}{2} D_{KL}(Q \parallel M)
\end{align*}$$ 其中 $M = \frac{1}{2}(P+Q)$.
當兩個分布 $P,Q$ 的 support sets 不重疊時, $JSD=\log(2)$, 是個 constant, loss 也失去作用了.
而 EMD 或 OT 根據他們的定義, 先天上就不會有這種限制.
EMD 的數學描述和線性規劃求解
用數學正式描述一下 EMD 問題, 首先定義變量:
$\circ$ 來源分佈:向量 $a \in \mathbb{R}^n_+$, 且 $\sum_{i=1}^n a_i = 1$.
$\circ$ 目標分佈:向量 $b \in \mathbb{R}^m_+$, 且 $\sum_{j=1}^m b_j = 1$.
$\circ$ 代價矩陣: $C \in \mathbb{R}^{n \times m}$, 其中 $C_{ij}$ 為從 $i$ 搬到 $j$ 的單位成本.
$\circ$ 傳輸矩陣(決策變量): $P \in \mathbb{R}^{n \times m}$, $P_{ij}$ 表示來源第 $i$ 個土堆 ($a_i$) 要搬運多少量到目標第 $j$ 個土堆 ($b_j$).
目標是最小化總傳輸成本:
$$\begin{align}
\min_{P \in \mathbb{R}^{n \times m}} \langle P, C \rangle =\min_{P \in \mathbb{R}^{n \times m}} \quad & \sum_{i=1}^n \sum_{j=1}^m P_{ij} C_{ij} \quad (\text{目標函數}) \\
\end{align}$$ 並滿足邊緣分佈約束:
$$\begin{align}
\begin{aligned}
\text{s.t.} \quad & \sum_{j=1}^m P_{ij} = a_i, \quad \forall i \in \{1, \dots, n\} \quad (\text{行約束}) \\
& \sum_{i=1}^n P_{ij} = b_j, \quad \forall j \in \{1, \dots, m\} \quad (\text{列約束}) \\
& P_{ij} \ge 0, \quad \forall i, j \quad (\text{非負約束})
\end{aligned}
\end{align}$$ 很明顯地這是一個標準的 線性規劃 LP (Linear Programming) 問題. (目標函數、約束都是線性方程式)
可使用 scipy.optimize.linprog 來求解, 範例請參考 Wasserstein_Kantorovich.ipynb
求解 LP 有一個經典有名的 Simplex mehod 方法
由於 LP 的目標函式為線性, 對應到下圖左的等高線 (紅色直線), 箭頭方向表示 loss 往下降的方向
且 LP 約束都是線性約束, 對應到下圖左橘色區塊反應了線性約束形成的 feasible space.
因此 LP 問題的最佳解就一定在端點 vertex 的位置. (只給結論)
Simplex method 就提出從 vertex 出發沿著 edge 往 loss 低的方向走到下一個 vertex, 重複直到最佳解出現. 見下圖右.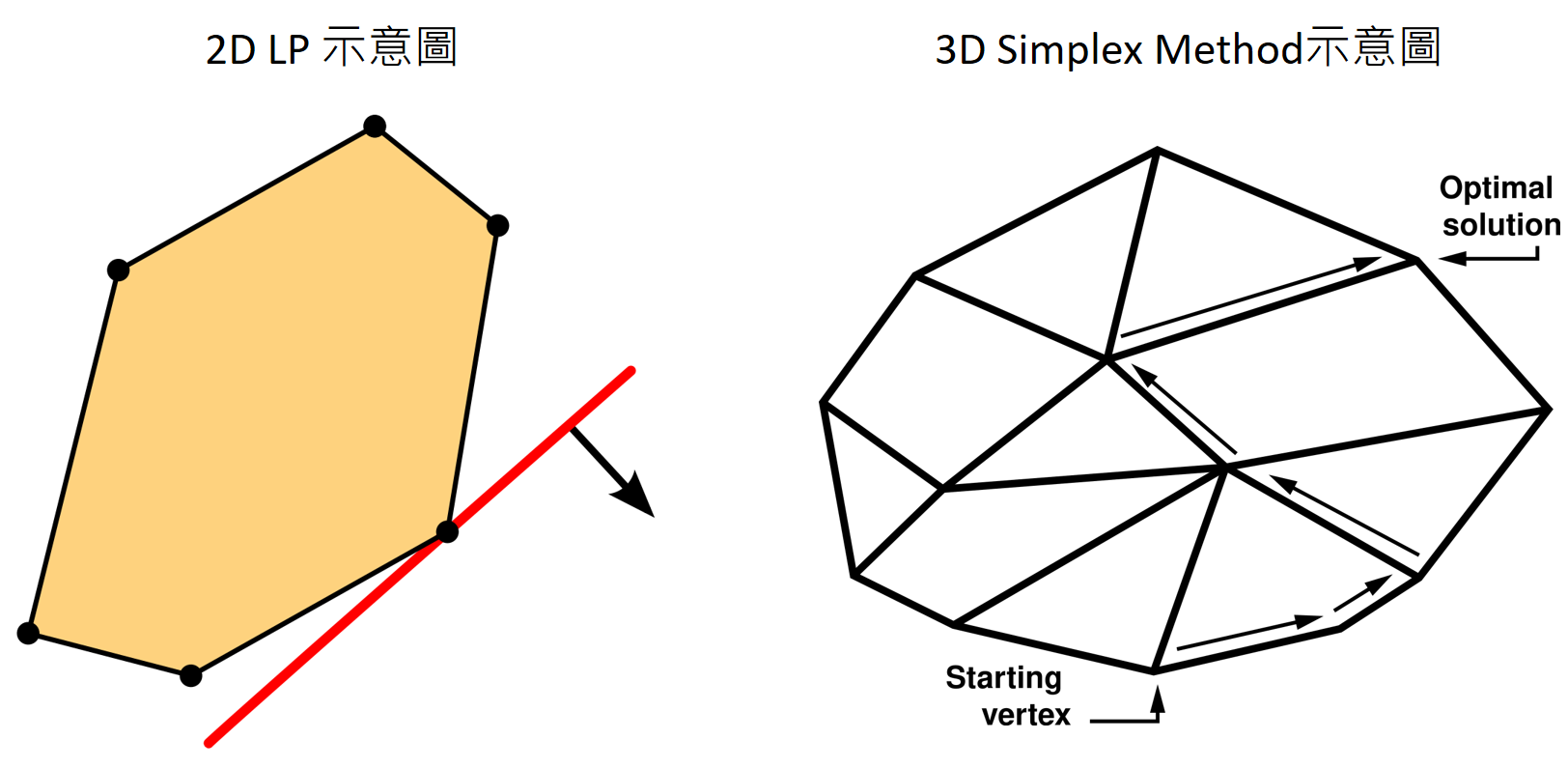
LP 和 Simplex method 雖然很優美, 不過仍有兩個比較大的缺點:
- 計算昂貴:Simplex method 雖然在平均情況是多項式時間, 但在訓練資料很大的情況下, 算一次 loss 就要跑一次 simplex method, cost 還是太大 (相比於神經網路常用的 KL-divergence).
- 不可微分與不穩定:最優解通常位於多胞形的頂點 (稀疏解). 當輸入數據微小變動時, 解可能會從一個頂點跳到另一個頂點, 導致梯度不連續, 無法應用於神經網路的反向傳播.
下一篇介紹的 Entropic Optimal Transport (EOT) 將作出改善
雖然 EOT 求解出來不會是最優傳輸解, 它會是一個模糊化的逼近結果. 但擁有計算便宜 (相較 Simplex method) 和可微分的優點, 在 OT 問題上會是很重要的做法.