這是初探最優傳輸 OT (Optimal Transport) 的第二篇, 聊一下背後的數學理論
接續上一篇引導出 EMD 是什麼以及什麼情況下我們需要 EMD 而非 KL or JSD 距離後, 我們最後說到 EMD 的兩個缺點: 不夠有效率以及無法微分
本篇我們介紹 EOT (Entorpic Optimal Transport)
EOT 將 EMD 問題 relax 後, 雖然只能找到逼近解, 但卻能利用一個更有效率且可微分的 Sinkhorn 演算法來求解.
我們將著重在數學理論部分, 從而理解 EOT 及 Sinkhorn 演算法的本質內涵.
最後再介紹一個重要的變形, Partial OT, 可以不用所有的 “土堆” 都要搬運, 只匹配部分.
[備註]:在離散情況下 Earth Mover’s Distance (EMD) / Optimal Transport / Wasserstein distance 指同一件事情, 文章在不混淆情況下有時會混用
背景:傳統最優傳輸的困境
在傳統最優傳輸 (Standard OT) 中, 我們試圖尋找一個傳輸矩陣 $P$, 以最小化將分佈 $a$ 搬運到分佈 $b$ 的總成本.
$$\begin{align}
\min_{P \in \mathbb{R}^{n \times m}} \langle P, C \rangle \quad & = \min_{P \in \mathbb{R}^{n \times m}} \quad \sum_{i=1}^n \sum_{j=1}^m P_{ij} C_{ij} \quad (\text{目標函數}) \\
\text{s.t.} \quad & \sum_{j=1}^m P_{ij} = a_i, \quad \forall i \in \{1, \dots, n\} \quad (\text{行約束}) \\
& \sum_{i=1}^n P_{ij} = b_j, \quad \forall j \in \{1, \dots, m\} \quad (\text{列約束}) \\
& P_{ij} \ge 0, \quad \forall i, j \quad (\text{非負約束})
\end{align}$$ 其中變量定義如下:
$\circ$ 來源分佈:向量 $a \in \mathbb{R}^n_+$, 且 $\sum_{i=1}^n a_i = 1$.
$\circ$ 目標分佈:向量 $b \in \mathbb{R}^m_+$, 且 $\sum_{j=1}^m b_j = 1$.
$\circ$ 代價矩陣: $C \in \mathbb{R}^{n \times m}$, 其中 $C_{ij}$ 為從 $i$ 搬到 $j$ 的單位成本.
$\circ$ 傳輸矩陣(決策變量): $P \in \mathbb{R}^{n \times m}$, $P_{ij}$ 表示來源第 $i$ 個土堆 ($a_i$) 要搬運多少量到目標第 $j$ 個土堆 ($b_j$).
這是一個標準的 線性規劃 LP (Linear Programming) 問題, 使用 Simplex mehod 方法可求解, 但仍面臨了計算效率 (相比於神經網路常用的 KL-divergence) 和不可微分兩個困難 (詳細參考前一篇文章)
熵正則化最優傳輸 (Entropic Optimal Transport, EOT)
解法:引入熵正則化
為了同時解決「速度」與「可微分性」, Marco Cuturi (2013) [pdf] 提出在目標函數中加入負熵正則項
新的目標函數 (Primal Problem):
$$\begin{align}
\min_{P \in \mathbb{R}^{n \times m}} \quad \mathcal{E}(P) = \sum_{ij} P_{ij} C_{ij} + \epsilon \sum_{ij} P_{ij} (\log P_{ij} - 1)
\end{align}$$ (註: 使用 $x(\log x - 1)$ 而非 $x \log x$ 是為了求導後的簡潔性, 兩者只差一個常數項, 不影響最優解位置)
其中 $\epsilon > 0$ 是正則化係數. 這將問題從線性規劃轉變為嚴格 Convex Optimization 問題.
約束條件為 $\sum_j P_{ij} = a_i$, $\sum_i P_{ij} = b_j$, 和 $P_{ij} \ge 0$.
這樣轉換後, 雖然不再是線性規劃問題了, 但仍然是凸優化問題 (convex optimization)
解凸優化問題第一步就是先寫出 Lagrangian function
求解:寫出 Lagrangian 求解最佳化問題
引入 Lagrange Multiplier: $\alpha \in \mathbb{R}^n$ (行約束), $\beta \in \mathbb{R}^m$ (列約束) 和 $\lambda\in\mathbb{R}^{mn}$ (非負約束) 寫出 Lagrangian function:
$$\begin{aligned}
\mathcal{L}(P, \alpha, \beta, \lambda) = & \sum_{ij} P_{ij} C_{ij} + \epsilon \sum_{ij} P_{ij} (\log P_{ij} - 1) \\
& + \sum_i \alpha_i (a_i - \sum_j P_{ij}) + \sum_j \beta_j (b_j - \sum_i P_{ij}) -\sum_{ij}\lambda_{ij}P_{ij}
\end{aligned}$$ 計算 gradient 並令其為 $0$, i.e. $\nabla_P\mathcal{L}=0$:
$$\begin{align}
\frac{\partial \mathcal{L}}{\partial P_{ij}} = C_{ij} + \epsilon (\log P_{ij} + 1 - 1) - \alpha_i - \beta_j - \lambda_{ij} = 0 \\
\Longrightarrow \epsilon \log P_{ij} = \alpha_i + \beta_j + \lambda_{ij} - C_{ij} \\
\Longrightarrow P_{ij} = \exp\left( \frac{\alpha_i + \beta_j + \lambda_{ij} - C_{ij}}{\epsilon} \right) \\
\end{align}$$ 根據 K.K.T. conditions 的 complementarity slackness (KKT 筆記) 我們知道一定會滿足:
$$\begin{align*}
\lambda_{ij}P_{ij}=0
\end{align*}$$ 從 (8) 可以看出 $P_{ij}>0$, 因此得到 $\lambda_{ij}=0$. (8) 去掉 $\lambda_{ij}$ 後得到
$$\begin{align}
P_{ij} = \exp\left( \frac{\alpha_i}{\epsilon} \right) \cdot \exp\left( -\frac{C_{ij}}{\epsilon} \right) \cdot \exp\left( \frac{\beta_j}{\epsilon} \right)
\end{align}$$ 令 $u_i = \exp(\alpha_i / \epsilon)$, $v_j = \exp(\beta_j / \epsilon)$, and $K_{ij} = \exp(-C_{ij} / \epsilon)$ 代入上式
我們可以推導出最優解 $P^*$ 必須具備的形式:
$$\begin{align}
\boxed{P^*_{ij} = u_i K_{ij} v_j}
\end{align}$$ 稱 $K_{ij} = e^{-C_{ij}/\epsilon}$ 為 Gibbs Kernel, 則:
$$\begin{align}
P^* = \text{diag}(u) \, K \, \text{diag}(v)
\end{align}$$ 這意味著最優傳輸矩陣 $P^*$, 本質上就是將一個基於幾何距離計算出的核矩陣 $K$, 經過對角縮放 (Diagonal Scaling) 後得到的.
Sinkhorn 演算法和收斂討論
為了得到 $P^*$ (最優傳輸矩陣), 我們必須解出 $u$ 和 $v$. Sinkhorn 演算法就是醫個高效的迭代求解步驟
利用邊緣分佈約束: ($\odot$ 表示 elementwised 相乘)
$\circ$ 行約束 (2): $P \mathbf{1} = a \implies u \odot (Kv) = a$
$\circ$ 列約束 (3): $P^T \mathbf{1} = b \implies v \odot (K^T u) = b$
這直接導出了 Sinkhorn 演算法 的迭代步驟
$$\begin{align}
u \leftarrow \frac{a}{Kv}, \quad v \leftarrow \frac{b}{K^T u}
\end{align}$$
要說明為什麼 (12) 會收斂, 就不得不涉及到一些 convex optimization 的知識了.
PS: 很好的整理 primal and dual problem: CMU lecture
一般我們稱原來的最佳化問題為 primal problem (對應 (1) 到 (4) 的式子)
寫出 Lagrangian function $\mathcal{L}(P,\alpha,\beta)$ 後 (注意到因為 $\lambda=0$ 所以省略), 先定義 Lagrange dual function $g$ 為:
$$\begin{aligned}
g(\alpha,\beta, \lambda)\doteq\inf_{P}\mathcal{L}(P,\alpha,\beta, \lambda)
\end{aligned}$$ 稱如下的問題為 dual problem (可以證明必定為 concave problem 不管原本 primal problem 是否為 convex problem):
$$\begin{aligned}
\max_{\alpha,\beta, \lambda}\quad & g(\alpha,\beta, \lambda) \\
\text{s.t.}\quad & \lambda\leq0
\end{aligned}$$ (註): $\alpha,\beta$ 對應到 primal problem 為等式的約束條件, 所以在 dual problem 沒有限制
由於我們已知 $\lambda=0$, 所以 dual problem 只剩下
$$\begin{align}
\max_{\alpha,\beta}\quad & g(\alpha,\beta)
\end{align}$$ 再由於 dual problem (13) 是 concave 優化問題, 當 primal problem 是 convex 問題的時候, 兩個問題的最佳解會相等, i.e. dual gap 為 0. 換句話說解出 dual 的 $\alpha^*$ 和 $\beta^*$ 等同於解出 primal 的 $P^*$.
而 Sinkhorn 演算法的迭代步驟 (12) 其實就是用塊坐標上升 (Block Coordinate Ascent) 方法解 dual problem (13).
最後因為 dual problem (13) 是 concave 優化問題, Block Coordinate Ascent 能保證收斂.
用 Sinkhorn Divergence 修正偏差
雖然 EOT 計算快且可微, 但引入的正則化項 $\epsilon$ 使得我們「自己到自己」的傳輸代價不為零:
$$\begin{align*}
OT_\epsilon(a, a) \neq 0
\end{align*}$$ 為了修正這個問題, 這篇文章提出用 Sinkhorn Divergence 減去由 $\epsilon$ 帶來的擴散偏差
定義新的損失函數:
$$\begin{align}
S_\epsilon(a, b) = OT_\epsilon(a, b) - \frac{1}{2} OT_\epsilon(a, a) - \frac{1}{2} OT_\epsilon(b, b)
\end{align}$$ 論文就沒特別去閱讀了, 著名的 POT (Python Optimal Transport) package 有實作了這個 loss:ot.bregman.empirical_sinkhorn_divergence [doc]
Partial Optimal Transport (部分最優傳輸)
在現實世界的數據中, 我們很少能遇到 “兩個分佈總質量完全相等” 或者 “每一個點都必須找到對應” 的完美情況
舉個圖像匹配 (Image Matching) 例子, 圖像 A 有一隻狗, 圖像 B 也有那隻狗但背景完全不同, 我們只希望匹配狗的部分, 可以忽略背景
以數學定義來說, 標準 OT 要求 $\sum P_{ij} = \sum a_i = \sum b_j$
Partial OT 則放寬了此限制, 只需要設定一個目標傳輸總質量 $m$, $0 < m \le \min(\sum a, \sum b)$.
整個優化問題變成: [ref]
$$\begin{align}
\min_P \langle P, C \rangle \quad & = \min_P \quad \sum_{ij} P_{ij} C_{ij} \quad (\text{目標函數}) \\
\text{s.t.} \quad & \sum_j P_{ij} {\color{orange}{\leq}} a_i, \quad \forall i \quad (\text{行約束}) \\
& \sum_i P_{ij} {\color{orange}{\leq}} b_j, \quad \forall j \quad (\text{列約束}) \\
& P_{ij} \ge 0, \quad \forall i, j \quad (\text{非負約束}) \\
& {\color{orange}{\sum_{ij}P_{ij}=m}}, \quad (\text{總質量約束})
\end{align}$$ 注意到與原始 OT 問題 (1)~(4) 有幾個差異, 除了 (19) 設定的搬運總質量之外
$\circ$ 式 (16) 行約束的 $\leq$ 表示搬走的量不能超過 Source 擁有的, 也表示 Source 不必都要搬動, 甚至可以不保留, i.e. 當 $\sum_{j}P_{ij} < a_i$ 時表示 $a_i$ 有些土 “消失了”.
$\circ$ 式 (17) 列約束的 $\leq$ 表示接收的量不能超過 Target 能容納的, 也表示 Target 不必都要接收, 也可以不用接收滿指定的上限, i.e. 當 $\sum_{i}P_{ij} < b_j$ 時表示 $b_i$ 沒有被填滿.
Partial OT 主要有兩種解法: 1. 虛擬點法 (Dummy Points) 和 2. 熵正則化迭代法 (Entropic Partial OT)
這邊很簡略的描述一下這兩種做法
虛擬點法 (Dummy Points / Augmented Matrix)
觀察 partial OT 數學問題 (15)~(19) 其實與標準的 OT 問題 (1)~(4) 非常接近
如果能將不等式的條件變成等式, 應該就能視為標準 OT 問題了吧
基於這樣的想法, 如果我們在 Source 和 Target 各增加一個 “垃圾桶 (Dummy Node)”, 用來接收那些不被傳輸的質量, 這樣就能寫成等式條件了, 因此:
- 擴充 Source $a'$: 在 $a$ 後面加一個虛擬點, 質量為 $\sum b - m$. 其意義為 Target 沒收到的質量, 都由這個虛擬點給
- 擴充 Target $b'$: 在 $b$ 後面加一個虛擬點, 質量為 $\sum a - m$, 其意義為 Source 沒送出去的質量, 都丟到這個虛擬點
- 擴充代價矩陣 $C'$ 為: $$\begin{aligned}
C' = \begin{bmatrix}
C & 0 \\
0 & 0
\end{bmatrix} \quad \text{(擴充後的代價矩陣)}
\end{aligned}$$
- 原本的 $N \times M$ 區域維持 $C_{ij}$
- 新增的虛擬區域 (垃圾桶), 其搬運成本設為 0 (或者某個閾值, 視需求而定)
- 虛擬點對虛擬點 (右下角) 成本設為 0
構造好 $a', b', C'$ 後, 直接跑標準的 Sinkhorn Algorithm. 解出來的 $P'$ 取左上角 $N \times M$ 的部分, 就是 Partial OT 的解
嚴謹的數學推導請參考論文 Partial Optimal Transport with Applications on Positive-Unlabeled Learning [arxiv] 的 Appendix A.
POT 庫提供的函數為 ot.partial.partial_wasserstein [doc]
Entropic Partial OT
如果不使用虛擬點 (例如矩陣太大不想擴充), 可以修改 Sinkhorn 的迭代公式來適應不等式約束
這是基於 Benamou et al. (2015) 的論文: Iterative Bregman Projections for Regularized Transportation Problems [arxiv], 參閱 Chapter 5.1 段落和 Proposition 5 的算法.
目標函數 (Entropic Partial OT) 為:
$$\begin{aligned}
\min_{P \ge 0} \langle P, C \rangle - \epsilon H(P) \quad \text{s.t. } P\mathbf{1} \le a, P^T\mathbf{1} \le b, \sum P_{ij} = m
\end{aligned}$$ 原先的標準 Sinkhorn 是 $u = a / (Kv)$, 其中 Gibbs Kernel: $K = e^{-C/\epsilon}$.
在 Partial OT 中, 因為是不等式 ($\le$), 更新公式會變成:
- 更新 $v$ (列): 如果需求超過了 $b$ 就 clipping, 這裡的 1 是指乘法因子的上限, 具體推導與對偶變數有關 $v \leftarrow \min \left( \frac{b}{K^T u}, \ 1 \right)$
- 更新 $u$ (行): $u \leftarrow \min \left( \frac{a}{K v}, \ 1 \right)$
- 總質量重整 (Rescaling): 上面的更新不能保證總質量為 $m$, 需重新對 $P$ 做 scaling 縮放
這裡仍列一下論文的 Proposition 5. 算法更新步驟: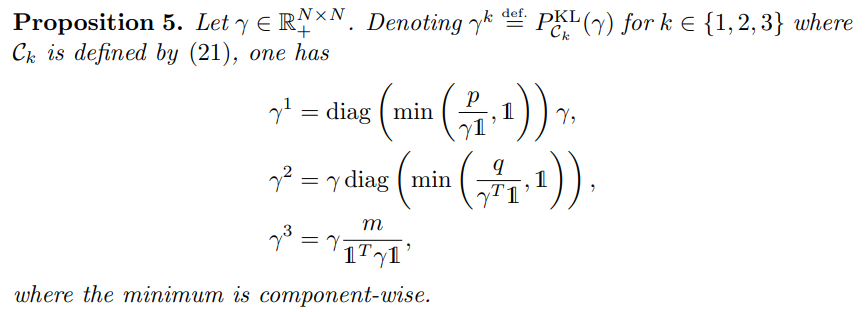
以及 POT 庫提供的函數為 ot.partial.entropic_partial_wasserstein [doc], [codes]
這段我就沒去看論文, 和研究 codes 了. 畢竟是 “初探” 😅
References
- POT (Python Optimal Transport) package: User guide (非常完整)
- Sinkhorn Distances: Lightspeed Computation of Optimal Transport [paper]
- Primal and Dual problems: CMU lecture, 講義 pdf: 11-dual-gen-scribed.pdf
- Learning Generative Models with Sinkhorn Divergences [arxiv]
- POT 的 partial OT problem [link]
- Partial Optimal Transport with Applications on Positive-Unlabeled Learning [arxiv]