這是初探最優傳輸 OT (Optimal Transport) 的第三篇, 聊一下應用和 toy example
OT 在 Machine learning 已有許多重要的應用, 例如大名鼎鼎的 “WGAN“ 就使用 EMD (Earth Mover’s Distance) 當 loss 來衡量 generator 產生的分布與目標資料分布兩者間的距離 (JSD 會有 support sets 無交集時的問題, 參考 “WGAN Part 2: 主角 W 登場“ 一文的說明)
還有 flow matching 裡針對一個 batch 可用 OT 找出訓練 conditional probability path 的配對, 這使得訓練更穩定. [筆記連結]
當然在 CV 領域, 已有許多成功的應用, 包含 point cloud mapping, graph 同構/對應, 等等.
更多範例可參考 POT 庫的 Examples gallery 頁面
不過文章前半段想先用另一個例子來說明 OT 的應用: 有關 doubly stochastic matrix (雙隨機矩陣)
再來簡單解釋一下, 求解 EOT 問題用的 Sinkhorn 迭代算法該怎麼微分. 如果是可微的 loss, 那就能結合到神經網路訓練中, 自然就打開了許多應用的可能.
最後本文會用一個 toy example 展示如何使用 EOT 當 loss, 讓 NN 模型學習從一個初始分布對應到目標分布.
DeepSeek 嘗試翻新 Residual Connections 的架構: mHC
26 年 1 月初看到消息說 DeepSeek 發表了一篇文章 “mHC: Manifold-Constrained Hyper-Connections [arxiv]”. 他們挑戰了多年來已成標準的 residual connection 架構, 並且在 DeepSeek-V3 架構中驗證.
請參考這部精彩的解說影片: How Residual Connections Are Getting an Upgrade [mHC]
其中 mHC 的一項關鍵技術是讓 weight matrix 滿足 doubly stochastic (雙隨機矩陣, 其每個行和列求和均為1) 的限制, 這使得訓練變得相當穩定
可能讀者會問 residual connection 訓練已經很穩定了, 說更穩定指的是什麼?
這就要說到之前有研究者想提升 residual connection 的能力而提出了 Hyper-connections [arxiv]
雖然能得到更好的模型表現, 但帶來的是訓練穩定性代價. 穩定性不好的原因仍然又回到的 residual connection 原本想改進的缺點, i.e. 由於 chain rule 造成的梯度消失或爆炸
因此這裡說的 mHC 穩定性提升是相對於 Hyper-connections 來說的 (這段我沒深入了解, 如有錯誤還請指正)
所以說了這麼多, mHC 到底與 OT (或 EOT) 的關聯是什麼?
答案是 ”將一個正矩陣轉成雙隨機矩陣” 這個問題恰恰就是 EOT 問題的一個特例
沒想到 OT 這種經典問題, 在最新 residual connection 架構的改進上發揮作用, 還真是有趣
什麼是雙隨機矩陣? 與 EOT 的對應關係?
我們把 “將一個正矩陣 $A$ 轉成雙隨機矩陣” 這句話用數學語言描述如下:
給定一個正矩陣 $A$, 我們想找到對角矩陣 $D_1, D_2$, 使得 $P = D_1 A D_2$ 是一個雙隨機矩陣 (即行和、列和均為 1)
現在回顧一下 OT 問題:
$$\begin{aligned}
\min_{P \in \mathbb{R}^{n \times m}} \langle P, C \rangle \quad & = \min_{P \in \mathbb{R}^{n \times m}} \quad \sum_{i=1}^n \sum_{j=1}^m P_{ij} C_{ij} \quad (\text{目標函數}) \\
\text{s.t.} \quad & \sum_{j=1}^m P_{ij} = a_i, \quad \forall i \in \{1, \dots, n\} \quad (\text{行約束}) \\
& \sum_{i=1}^n P_{ij} = b_j, \quad \forall j \in \{1, \dots, m\} \quad (\text{列約束}) \\
& P_{ij} \ge 0, \quad \forall i, j \quad (\text{非負約束})
\end{aligned}$$ Relax 成 EOT 問題後, 最佳解為:
$$\begin{align}
P^* = \text{diag}(u) \, K \, \text{diag}(v)
\end{align}$$ 稱 $K_{ij} = e^{-C_{ij}/\epsilon}$ 為 Gibbs Kernel, 且 $u,v$ 通過以下 Sinkhorn 演算法求得:
$$\begin{align}
u \leftarrow \frac{a}{Kv}, \quad v \leftarrow \frac{b}{K^T u}
\end{align}$$ 如果將來源分佈 $a$ 和目標分佈 $b$ 都定義為均勻分佈 ($a = b = \mathbf{1}/n$)
把正矩陣 $A$ 定義成 Gibbs Kernel $K$, i.e. $A\doteq K$.
式 (1) 解出來的 $P^*$ 正好就是雙隨機矩陣, 其中 $\text{diag}(u)\doteq D_1$, $\text{diag}(v)\doteq D_2$.
因此 ”將一個正矩陣轉成雙隨機矩陣” 這個問題確實就是 EOT 的一個特例
Sinkhorn 是一個迭代演算法, 怎麼做 Backpropagation?
解 EOT 使用 Sinkhorn 式 (2) 迭代求解, 但如果要當成 NN 的 loss 必須要能微分
這就要回答一個問題: 在 PyTorch 或 TensorFlow 中, 計算圖(Computation Graph)是怎麼穿過 for 迴圈的?
最常用的方法為展開迴圈 (Unrolling the Iterations)
基本上把 Sinkhorn 的每一步迭代看作是神經網絡的一層, 如果迭代 $K$ 次就相當於一個 $K$ 層深的 Recurrent Neural Network (RNN), 這就是當年 Backpropagation Through Time (BPTT) 的做法.
這樣做的優點是實作簡單, 只要寫個 for loop, AutoGrad 就可以處理.
但缺點是記憶體消耗, 必須儲存 $K$ 次迭代的所有中間變量. 如同 RNN 一樣, 如果迭代太多次可能會有梯度消失或爆炸的問題
因此通常實務上我們只迭代較少的次數 (例如 10 或 20 次), 只要能得到一個不錯的梯度就好
mHC 才發布沒多久, 1~2周後馬上就有一篇論文針對迭代次數來改進, mHC-lite: You Don’t Need 20 Sinkhorn-Knopp Iterations [arxiv]. 這究竟是什麼瘋狂的速度阿…
Toy Example
最後用 toy example 來感受一下 EMD 或是 EOT 這種 loss 的作用
使用開源庫 POT (Python Optimal Transport) [website], 或 GeomLoss [website].
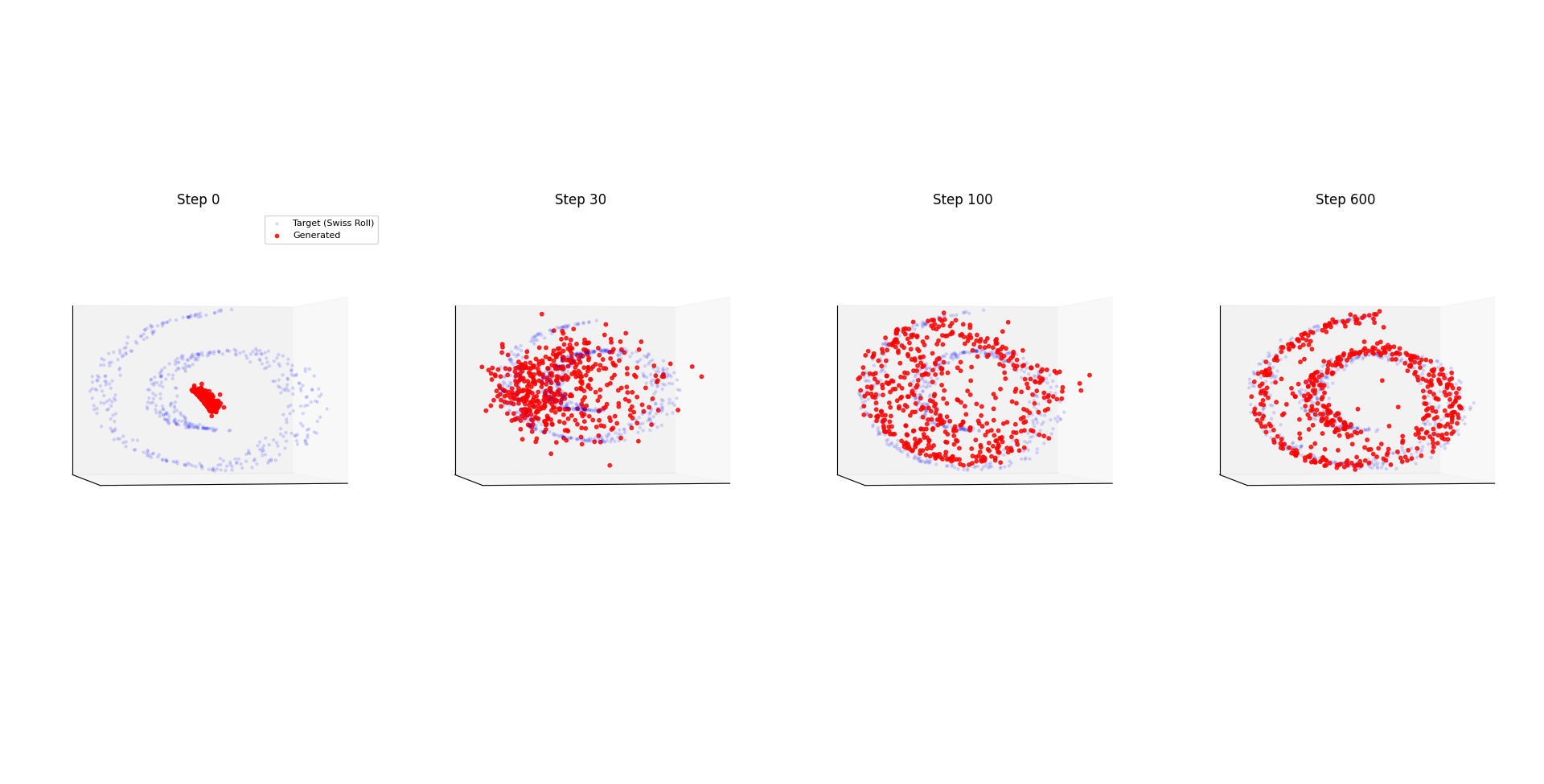
我們模擬從一個初始高斯分布 $x\in\mathbb{R}^3, x \sim \mathcal{N}(0,I)$.
用 NN $f_\theta:x\mapsto y_{pred}\in\mathbb{R}^3$ 學習如何轉變成一個 Swiss Roll 的分布
而 loss 就使用 EOT, 即 $\mathcal{L}=\text{EOT}(y_{pred},y_{gt})$ 其中 ground truth $y_{gt}$ 的點是從 Swiss Roll 分布採樣.
從下面動圖可以看到前面 iteration 的分布比較差, 因此 EOT loss 比較大
漸漸地訓練下去隨著 EOT loss 降低, NN 最後已經能 mapping 到 Swiss Roll 分布了
另一個 2D 範例圖結果如下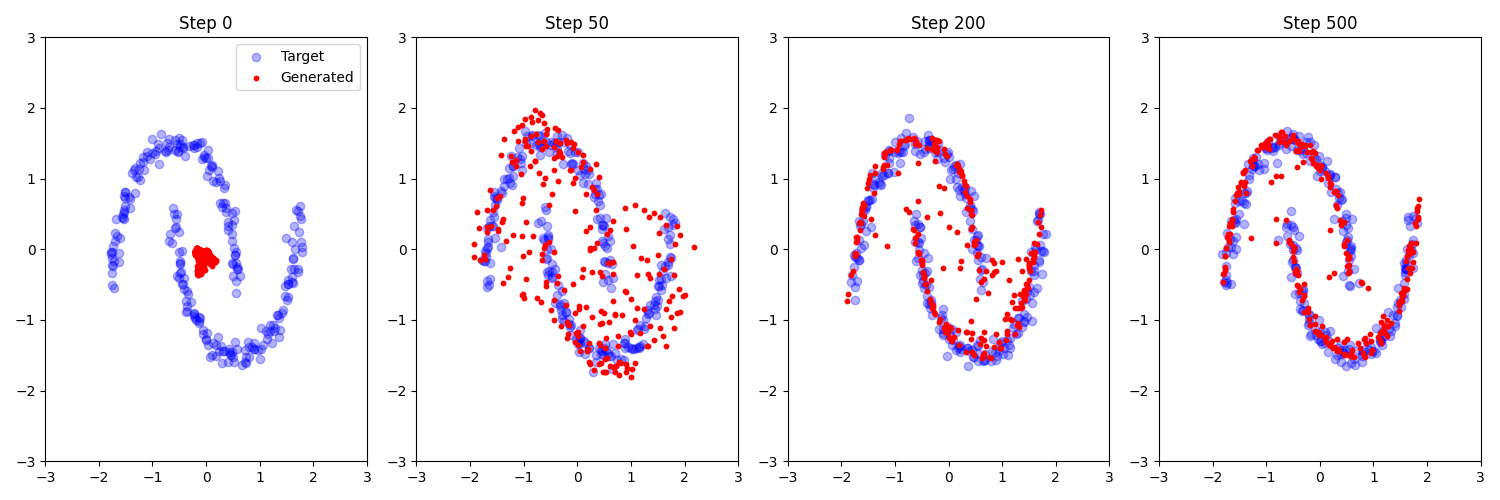
現在的 AI 能輕易產上面例子的 codes, 列出重點的 EOT loss, 完整 toy example codes:
▶️(點擊展開) EOT loss 程式碼片段
|
|
非常建議直接使用 ot.sinkhorn2 計算 EOT, 因為這些成熟的庫已經針對數值穩定性做了很多優化, 譬如會使用 log-domain、Sinkhorn Divergence 等技巧, 並且也優化了速度和對 CPU/GPU 的適配性.ot.sinkhorn2 的一個參數 reg 對應的是上一篇式 (5) 的 $\epsilon$, 如果愈小會愈接近原來的 OT sparse 解, 但也愈容易有數值不穩定狀況 (POT package 已經可以處理得很好), 所以通常需要將來源和目標分布做適當的歸一化會比較穩定, 或是將 $\epsilon$ 先從較大的值訓練起之後漸漸變小.
另外有關 Partial Optimal Transport (部分最優傳輸) 的實作函數, 再上一篇文章裡提到:
ot.partial.partial_wasserstein- 或是
ot.partial.entropic_partial_wasserstein這種使用Entropic 的 Sinkhorn 算法的
讀者可以自己跑跑看 POT 提供的範例, Examples gallery.
References
- mHC: Manifold-Constrained Hyper-Connections [arxiv]
- How Residual Connections Are Getting an Upgrade [mHC]
- mHC-lite: You Don’t Need 20 Sinkhorn-Knopp Iterations [arxiv]
- POT (Python Optimal Transport) package: User guide (非常完整)
GeomLoss[website]- toy example codes