總結一下 (up to 2024-02-17) 目前學習的量化技術和流程圖, 同時也記錄在 github 裡.
更新: (2026-04-30) 新增 LLM Transformer 相關 PTQ 方法, 如: QuIP, QuIP#, SpinQuant.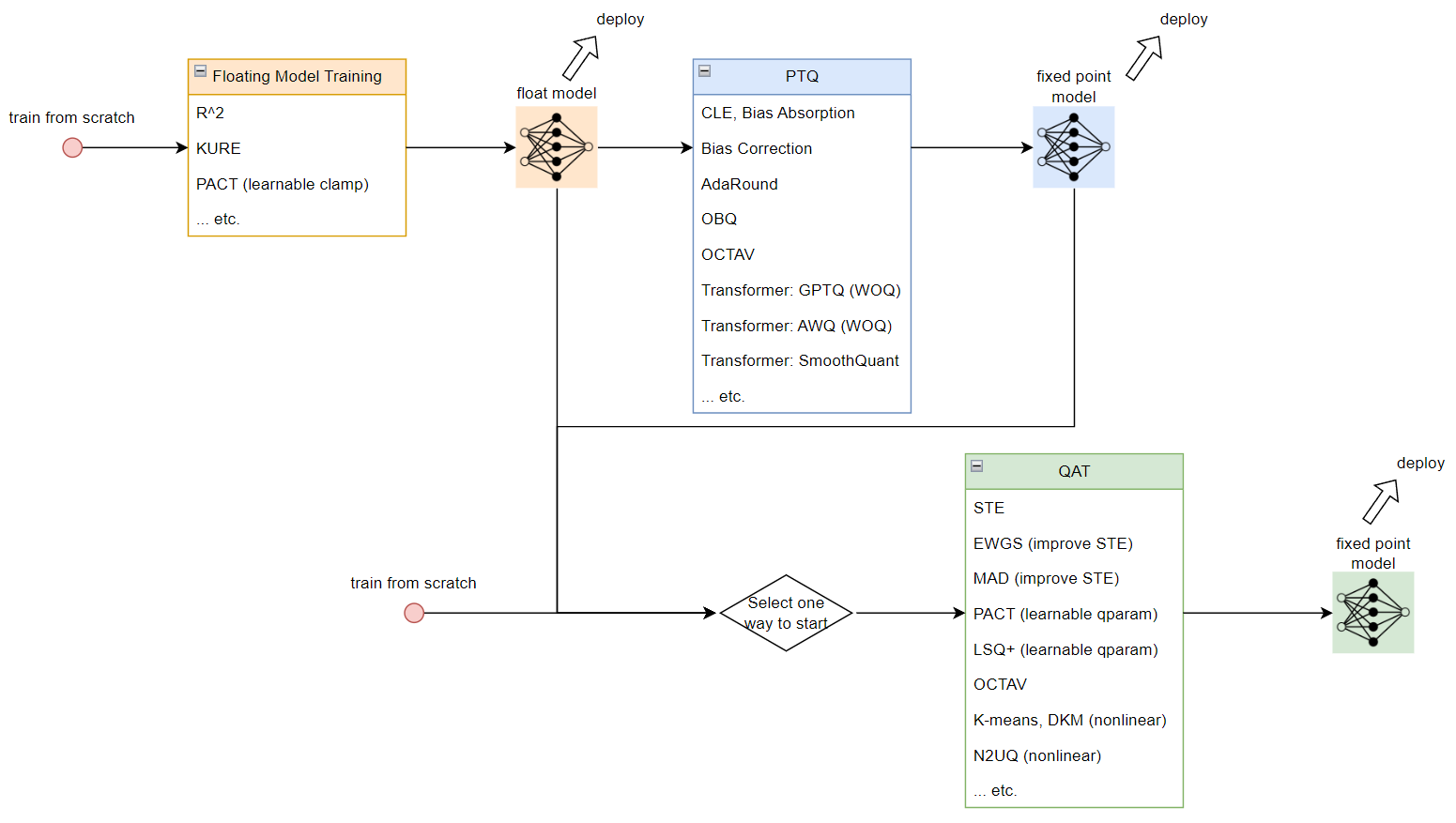 Post Training Quantization (PTQ) 稱事後量化. Quantization Aware Training (QAT) 表示訓練時考慮量化造成的損失來做訓練
Post Training Quantization (PTQ) 稱事後量化. Quantization Aware Training (QAT) 表示訓練時考慮量化造成的損失來做訓練
為了得到 fixed point model 可以對事先訓練好的 float model 做 PTQ 或 QAT, 或是直接從 QAT 流程開始
同時 QAT 也可以用 PTQ 來初始化訓練. 如果要從 float model 開始做量化的話, 可以考慮在訓練 float model 時就對之後量化能更加友善的技術 (如 R^2, KURE, PACT)
接著對每個技術點盡量以最簡單的方式解說. 如果對量化還不是那麼熟悉, 建議參考一下文章後半段的”簡單回顧量化”
量化技術和流程
Floating Model Training
這階段主要是讓訓練出來的 floating model 有利於之後量化的技術
- R^2 [paper]: 認為 outliers 愈少, 愈有利於後面的量化或壓縮. 提出了 3 種 regularization losses.
- KURE [paper]: 使用 4th moments Kurtosis (KURE, KUrtosis REgularization) 來當 regularization 讓分佈接近 uniform, 同樣會有利於後面的量化.
- PACT [paper]: 使得 $l,u$ 這兩個 clipping 上下界能被學習, 限制數值範圍
PTQ
PTQ 是針對 float model 做量化的技術, 不需要 training data, 通常只需要些許的 calibration data 即可, 有些技術仍會需要算 gradients, 而有些不用, 甚至連 calibration data 都不用.
一般來說 PTQ 效果會比 QAT 差, 但速度比 QAT 快多了, 同時針對 LLM 這種大模型 QAT 成本太高都只能使用 PTQ.
- CLE, Bias Absorption, Bias Correction [paper]: Qaulcomm DFQ (Data Free Quantization 技術), 詳見 [blog]
- AdaRound [paper]: weight 量化時 (式 (1)) 的 rounding (四捨五入) 不一定是最佳的, 找出使用 floor 或 ceil 的最佳組合來取代全部都用 rounding 的方式
- OBQ (Optimal Brain Quantization) [paper]: 對於 weights 在 quantize 其中一個元素後還要調整其他元素, 使得 quantization 對 output activatyions 的 re-construction error 最小.
- OCTAV (Optimally Clipped Tensors And Vectors)[paper]: 找出最佳的 scale $S$ 使得 quantization MSE 最小 (式 (4)), 詳見[blog1, blog2]
- Transformer GPTQ (WOQ) [paper]: 基於 OBQ 的技術來針對 Transformer 做些改進和加速. Weight-Only-Quantization (WOQ)
- Transformer AWQ (WOQ) [paper]: 對 input activations 值域特別大的那些 channels 做 scaling 處理, 這樣能維持 LLM 的效果, 詳見筆記 [blog]. Weight-Only-Quantization (WOQ)
- Transformer SmoothQuant [paper]: 透過一些等價的轉換將 activations 的 scale 縮小並放大 weights 的 scale, 使得 activations 變的較容易 quant 而 weights 仍然容易 quant. 詳見筆記 [blog]
- Transformer QuIP, QuIP# [paper QuIP], [paper QuIP#]: 利用隨機正交矩陣旋轉後能將 outliers 打散的特性 (筆記”隨機旋轉的量化魔法: 去去極值走“), 使得 LLM 的 PTQ 在 W4A4KV4 等級的量化表現仍維持非常好. 同時 QuIP# 提出使用隨機阿達馬轉換 (Randomized Hadamard Transform, RHT) 這種特殊的正交矩陣做加速, 好處是矩陣的元素只有 $\{-1, +1\}$, 所以計算過程甚至不需要進行浮點數的乘法運算.
- Transformer SpinQuant [paper], [blog]: 作者發現 QuIP/QuIP# 由於使用隨機正交矩陣, 最好和最差的表現仍差異較大. 因此直接針對 loss function 使用 Cayley SGD [blog] 優化旋轉矩陣, 由於直接優化且剃除隨機性, 在 2-bits weight 情況下甚至十分接近 float model 表現!
QAT
一般來說透過插入 fake-quant op (不清楚的話參見 “簡單回顧量化” 裡的說明) 使得在訓練時能感知到量化的誤差
- STE (Straight Through Estimator): 在做量化時 clip and round 這兩個運算不可微分, 為了能 back propagation 假裝沒有這兩個不可微分的 ops. 這是最常見和標準的 QAT 技巧.
- EWGS [paper]: 由於多個 floating 值會對應到同一個 quantized 值, 使得這些不同的 floating 值因為 STE 的原因都使用相同的 gradients, EWGS 改善了這點. 論文的 figure 1 圖示很清楚.
- MAD [in OCTAV paper]: 改善了 STE 對於 clipping op 的 under estimate 問題, 詳見論文裡的 figure 3 and appendix C.
- PACT [paper]: 使得 $l,u$ 這兩個 clipping 上下界能被學習, 限制數值範圍. 可以放在 QAT 過程中使用.
- LSQ+ [paper]: 使得 $S,Z$ 這兩個 qparam 能被學習, 詳見筆記 [blog]
- OCTAV (Optimally Clipped Tensors And Vectors)[paper]: 找出最佳的 scale $S$ 使得 quantization MSE 最小 (式 (4)), 詳見[blog1, blog2]. 除了上面 PTQ 做之外, 也可放在 QAT 過程中.
- K-means [paper], DKM [paper]: 屬於 nonlinear 量化, 利用 Kmeans 求出代表性的 codebook. DKM 為進一步改進的方法.
- N2UQ [paper]: 屬於 nonlinear 量化, 讓量化區間變成可學的 (固定的量化區間就是線性量化).
簡單回顧量化
量化就是將 float $X$ 用有限個點來表示, 如下圖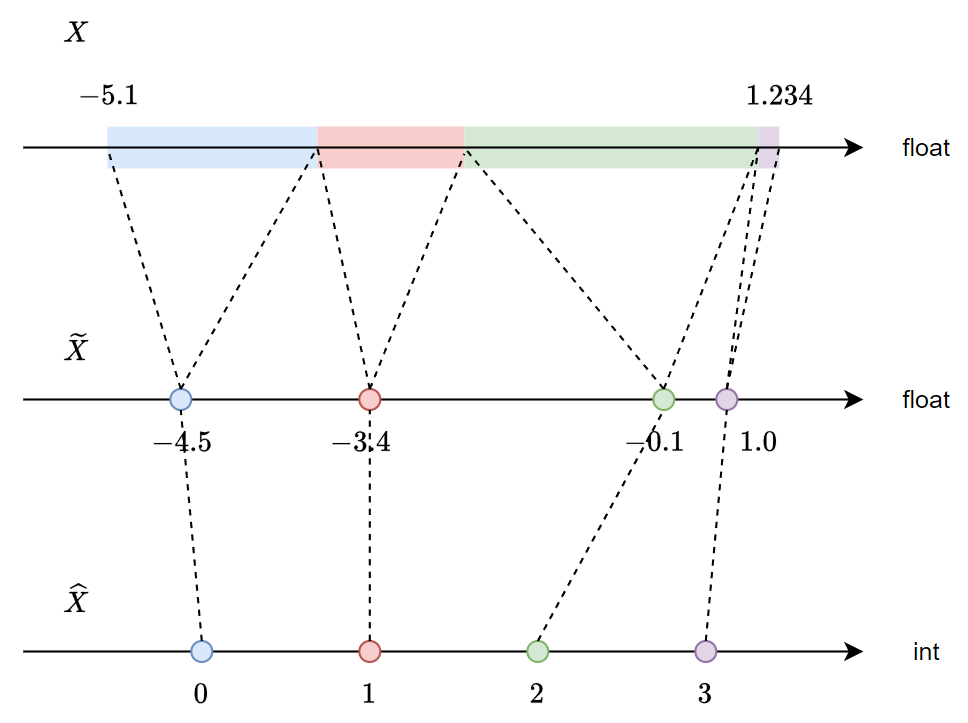 $\tilde{X}$ 的 4 個點對應到原來的 $X$ 可以看到是很不規則的, 或是說非線性
$\tilde{X}$ 的 4 個點對應到原來的 $X$ 可以看到是很不規則的, 或是說非線性
如果說這有限個點採用”線性”的對應方式, 則我們可以寫成下面式子對應關係:
$Z,S$ 分別稱為 zero point 和 scale, 而 $l,u$ 是 clipping 的 lower and upper bound.
所以量化參數 quantization parameters (用 qparam 簡稱) 就是
$$\begin{align}
\text{qparam}=\{Z,S,l,u\}
\end{align}$$
- Quantization Meam Square Error (MSE): $$\begin{align}\mathbb{E}_X[(X-\tilde{X})^2] \end{align}$$
- Symmetric: $Z=0$ 時為對稱量化
- Dynamic: qparam 在 inference 時才去統計出
- Static: qparam 在 inference 之前就事先統計好
- Quantization Granuity [SongHan slide]:
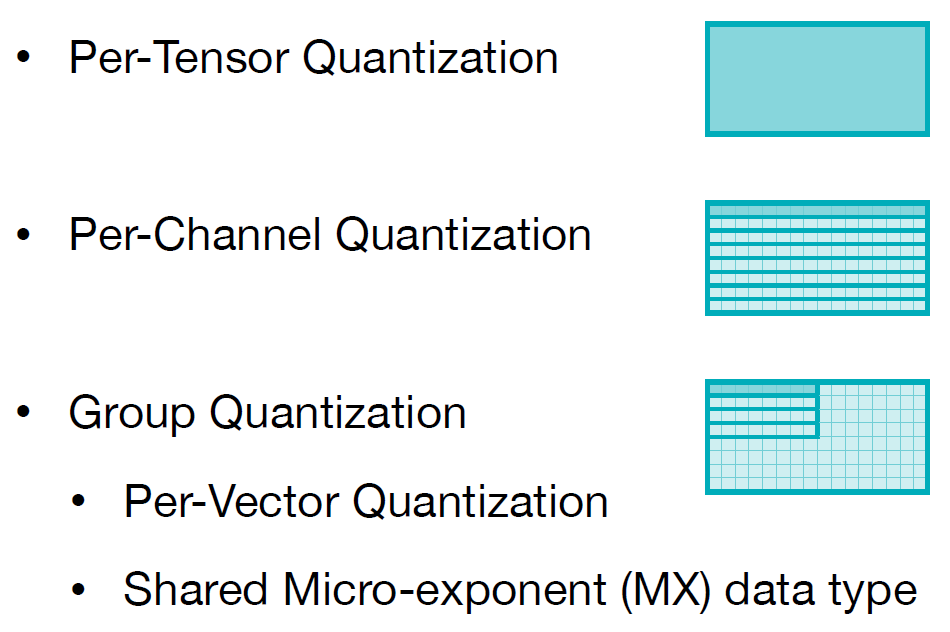
- per-tensor: 整個 weight or activation tensor 共用同一組 qparam
- per-channel: 同一個 channel 共用同一組 qparam, 例如以 convolution kernel 來說, 同一個 output channel 的 weights 共用同一組 qparam
- per-group: 常用在 LLM 的 Transformer, 通常以 64, 128 為一組共用 qparam
另外, 我們常說的 quant, de-quant, re-quant, fake-quant 可以用下圖來表示:
Model Compression Toolkits
以下蒐集一些重要的模型壓縮 repositories, 因此不限於量化, 有些還包含 pruning, NAS, distillation, 或圖優化等
- Microsoft Olive
- Microsoft NNI (Neural Network Intelligence): with NAS, Pruning, Quantization, Distilling
- OpenVino Neural Network Compression Framework (NNCF)
- Intel Neural Compressor: with NAS, Pruning, Quantization, Distillation
- Qualcomm AIMET: Quantization (DFQ and AdaRound, QAT), Model Compression (Spatial SVD, Channel pruning)
- NVidia TensorRT-LLM: optimize LLM (Transformer-based) models on NVidia GPU, using techniques such as Multi-query Attention (MQA), Group-query Attention(GQA), Paged KV Cache, SmoothQuant, GPTQ, AWQ, Speculative decoding, …
- Sony Model Compression Toolkit (MCT): Quantization with PTQ, GPTQ, QAT, Enhanced Post-Training Quantization (EPTQ). Structured Pruning