看完本文會知道什麼是 fake quantization 以及跟 QAT (Quantization Aware Training) 的關聯
同時了解 pytorch 的 torch.ao.quantization.fake_quantize.FakeQuantize 這個 class 做了什麼
Fake quantization 是什麼?
我們知道給定 zero ($z$) and scale ($s$) 情況下, float 數值 $r$ 和 integer 數值 $q$ 的關係如下:
$$\begin{align} r=s(q-z) \\ q=\text{round_to_int}(r/s)+z \end{align}$$ 其中 $s$ 為 scale value 也是 float, 而 $z$ 為 zero point 也是 integer, 例如int8Fake quantization 主要概念就是用 256 個 float 點 (e.g. 用
int8) 來表示所有 float values, 因此一個 float value 就使用256點中最近的一點 float 來替換則原來的 floating training 流程都不用變, 同時也能模擬因為 quantization 造成的精度損失, 這種訓練方式稱做 Quantization Aware Training (QAT) (See Quantization 的那些事)
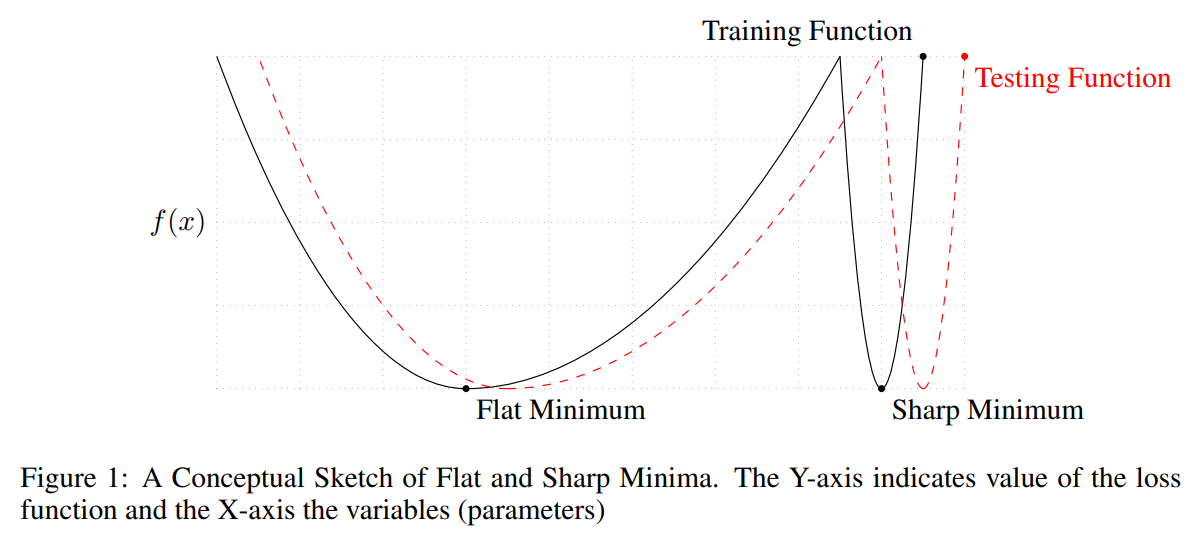 從圖可以容易理解到, 如果找到太 sharp 的點, 由於 test and train 的 mismatch, 會導致測試的時候 data 一點偏移就會對 model output 影響很大.
從圖可以容易理解到, 如果找到太 sharp 的點, 由於 test and train 的 mismatch, 會導致測試的時候 data 一點偏移就會對 model output 影響很大. 這也是目前一個普遍的認知: flat 的 local minimum 泛化能力較好.
這也是目前一個普遍的認知: flat 的 local minimum 泛化能力較好.