⚠️ [提醒]: 本篇難度可能偏高, 有些地方不會從頭開始解釋, 畢竟主要給自己筆記的, 請讀者見諒.
筆記動機是由於之前陸陸續續讀過 (連結為之前的筆記們):
- [Score matching]: Langevin dynamics 可以使用 score function ($\nabla\log p_{data}$) 來取 sample, 取出來的 sample 具有 $p_{data}$ 的分佈 (由 Fokker-Planck Equation 的定理可證). 因此我們要做的就是訓練一個 NN $s^\theta(x)\approx \nabla\log p_{data}(x)$, 這樣就能在 Langevin dynamics 中使用 $s^\theta$ 來對 $p_{data}$ 採樣了
- [Denoised diffusion model]: 訓練出能去噪 (denoise) 的 NN model (加高斯噪聲的過程稱 forward process, 去噪稱 backward). 由於無法直接做 MLE (Maximal Likelihood), 因此訓練目標函式改為優化 MLE 的 lower bound, 稱 ELBO (Evidence Lower Bound). 藉由訓練出的 denoised model, 一步一步還原乾淨資料.
- [Flow matching]: 從已知且容易採樣的 $p_{init}$ 採樣出初始 sample $x_0$, 根據學到的 vector field $u_t^\theta$ 來更新 trajectory $\{x_t\}_{0\leq t\leq1}$, 最終達到的 $x_1$ 滿足資料分布 $p_{data}$. 如何設計並訓練這樣的 vector field $u_t^\theta$ 可說是非常精彩, 也會用到物理中的 Continuity Equation (質量守恆).
我心理總認為這些東西應該有非常深刻的關聯 🤔, 但就是缺乏一個統一的框架來把這些觀念融合起來.
直到我看到 MIT 這門課程: Introduction to Flow Matching and Diffusion Models 的一些內容. (👍🏻 大推! 👍🏻)
簡直醍醐灌頂, 因此想筆記下來這個統一的框架. 正文開始

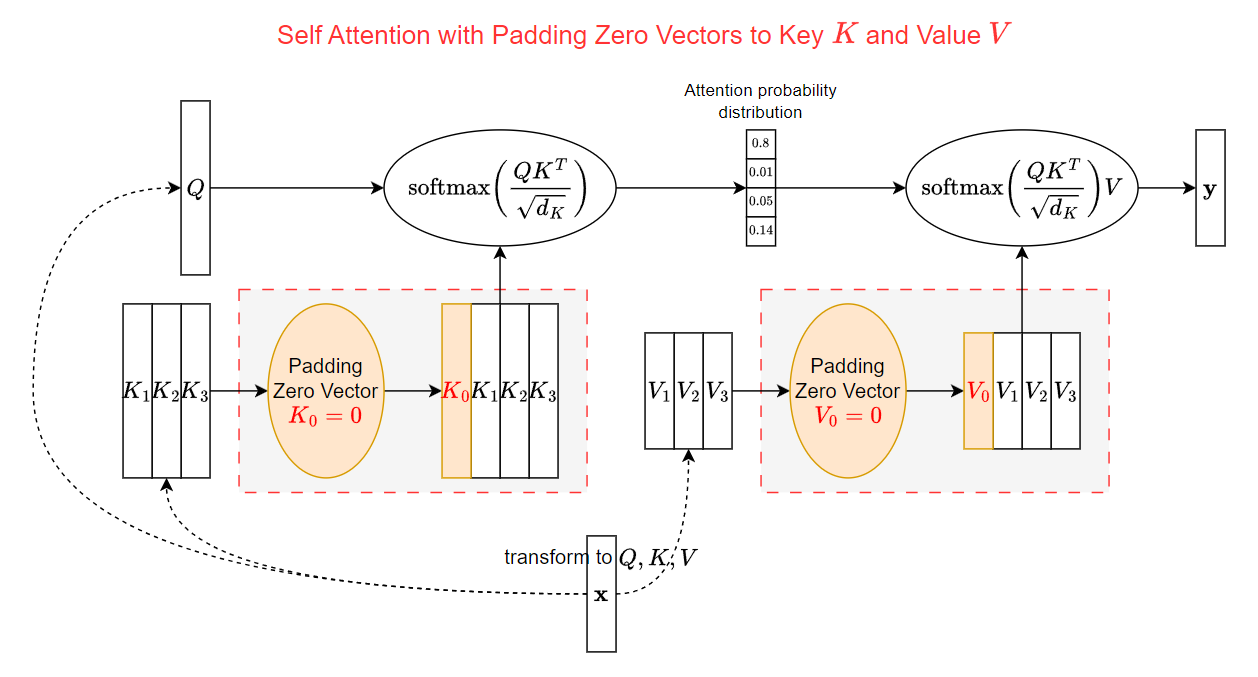 初次看到可能會很疑惑, 為啥要多 padding zero vectors? 本文就來解釋一下原因.
初次看到可能會很疑惑, 為啥要多 padding zero vectors? 本文就來解釋一下原因.
{kind=link}