接續上一篇: 讀 Flow Matching 前要先理解的東西 (建議先閱讀)
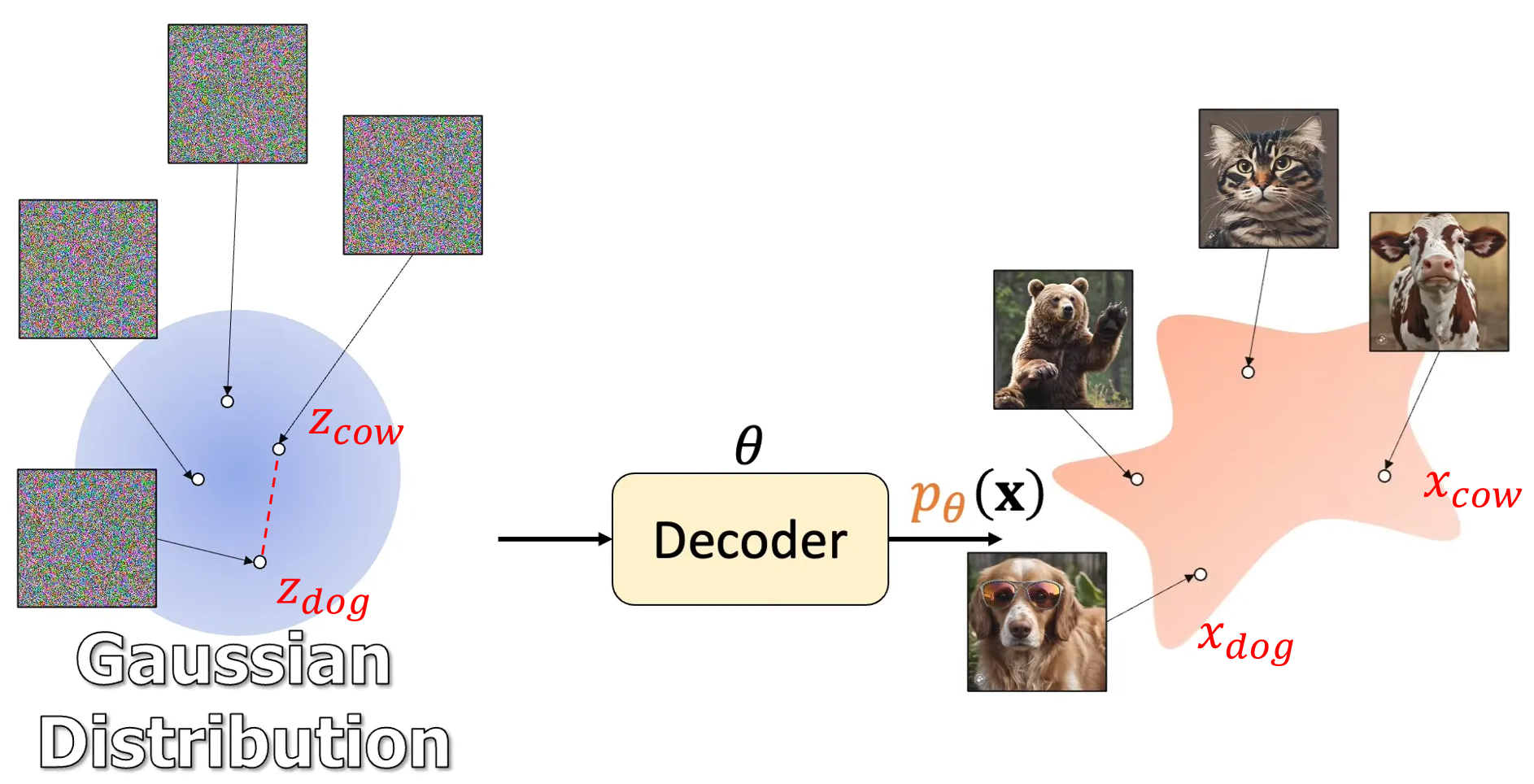
Flow matching 模型在時間 $t=0$ 的時候從常態分佈出發 $p_0(x)=\mathcal{N}(0,I)$, 隨著時間變化其 pdf, 例如時間 $t$ 時的 pdf 變化成為 $p_t(x)$, 直到時間 $t=1$ 時希望變成接近目標分佈 $q(x)$, 即希望 $p_1(x)\approx q(x)$.
概念是頭尾 pdf 確定後, 中間這無限多種可能的 $p_t(x)$ 變化經過作者的巧妙設定, 讓學 vector field $u_t(x)$ 變的可能! (不學 pdf 而是學 vector field)
結果就是用 NN 學到的 $u_t(x)$ 可以讓 pdf 從開頭的常態分佈一路變化到最後的資料目標分佈 $q(x)$.
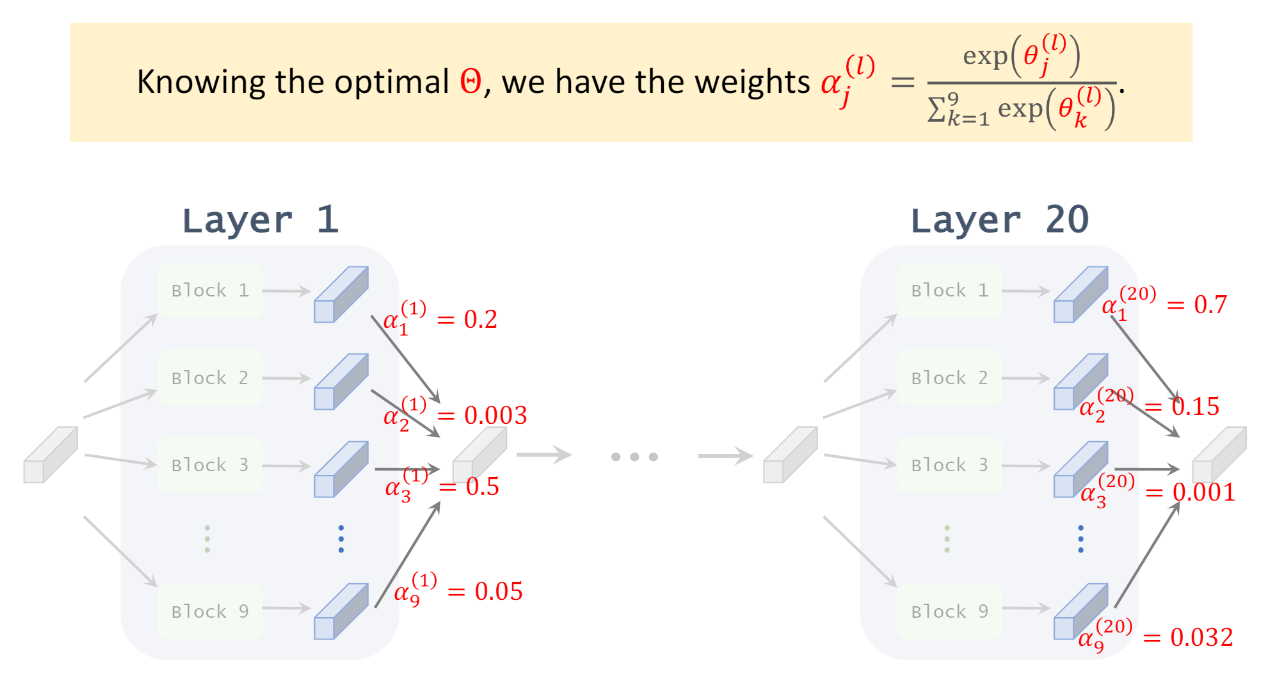 不過關鍵是怎麼找? 這樣聽起來似乎需要為每個 OPs 都配上對應可訓練的權重, 最後選擇權重大的那些 OPs? 以及怎麼訓練這些架構權重?
不過關鍵是怎麼找? 這樣聽起來似乎需要為每個 OPs 都配上對應可訓練的權重, 最後選擇權重大的那些 OPs? 以及怎麼訓練這些架構權重?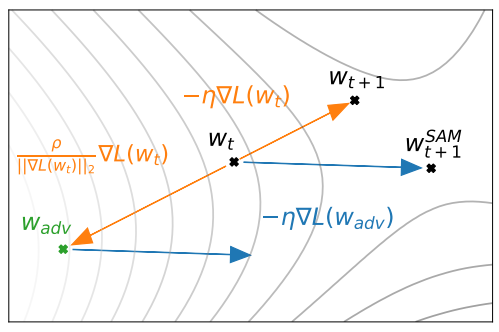 目前的 weight $w_t$ 的 gradient step 為
目前的 weight $w_t$ 的 gradient step 為