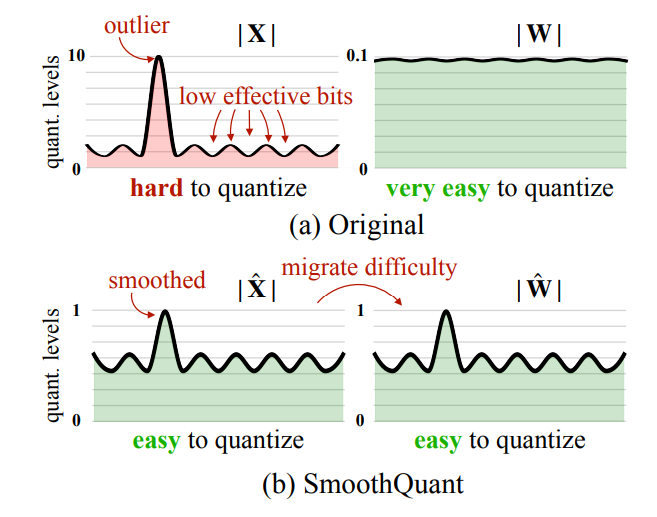
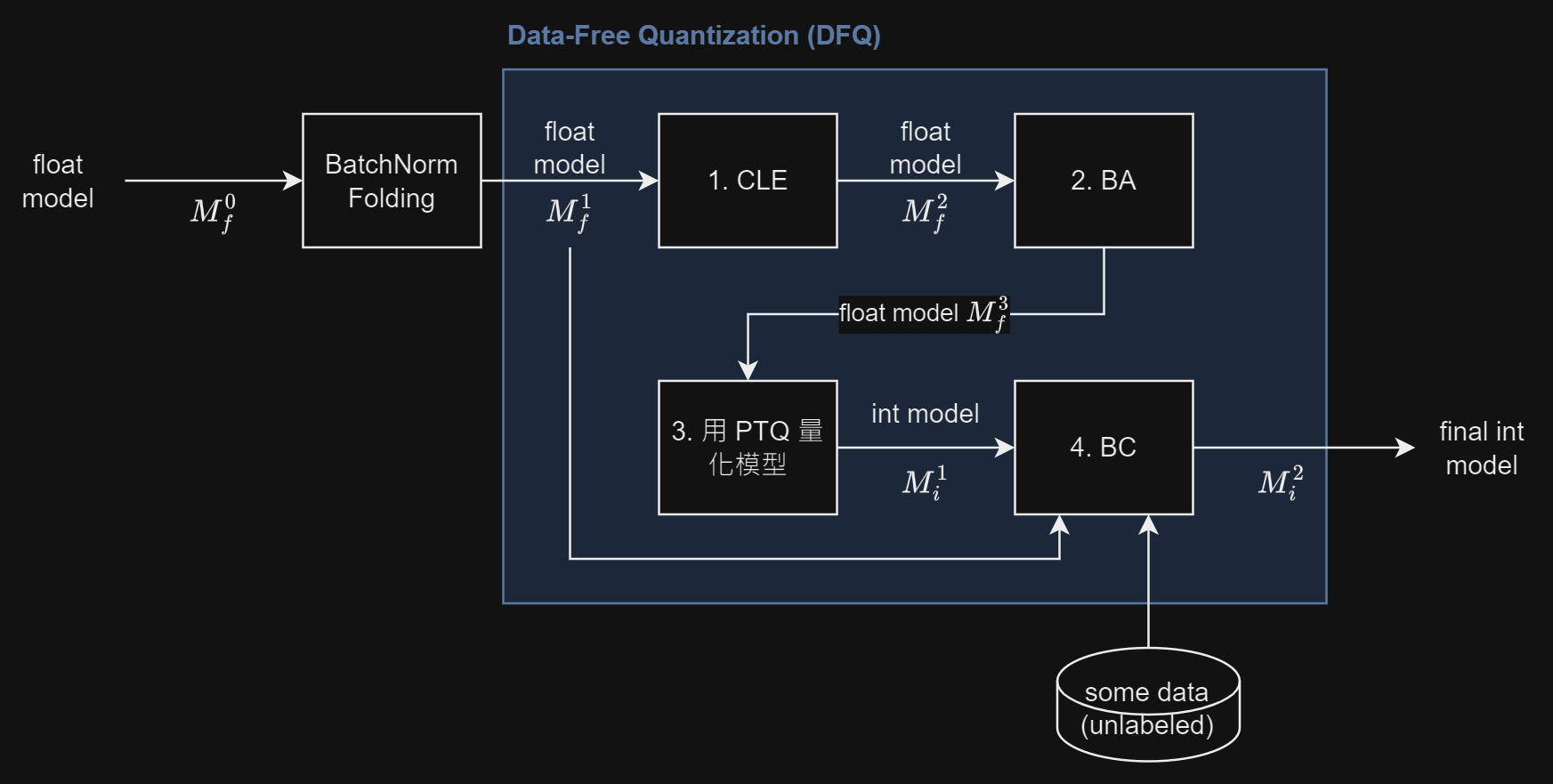
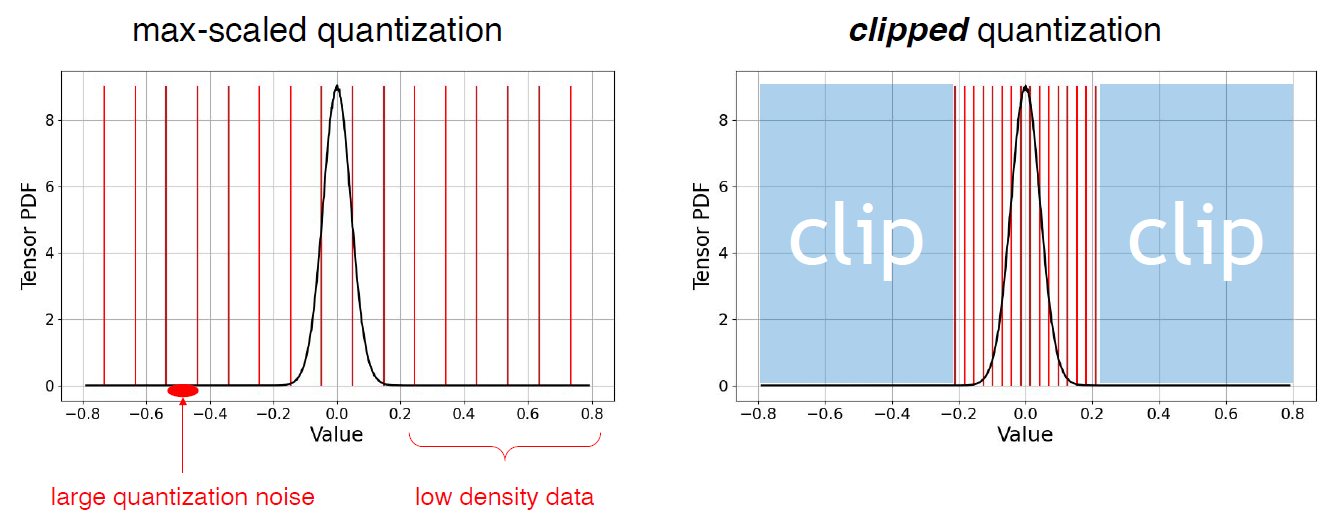
總結一下 (up to 2024-02-17) 目前學習的量化技術和流程圖, 同時也記錄在 github 裡.
更新: (2026-04-30) 新增 LLM Transformer 相關 PTQ 方法, 如: QuIP, QuIP#, SpinQuant.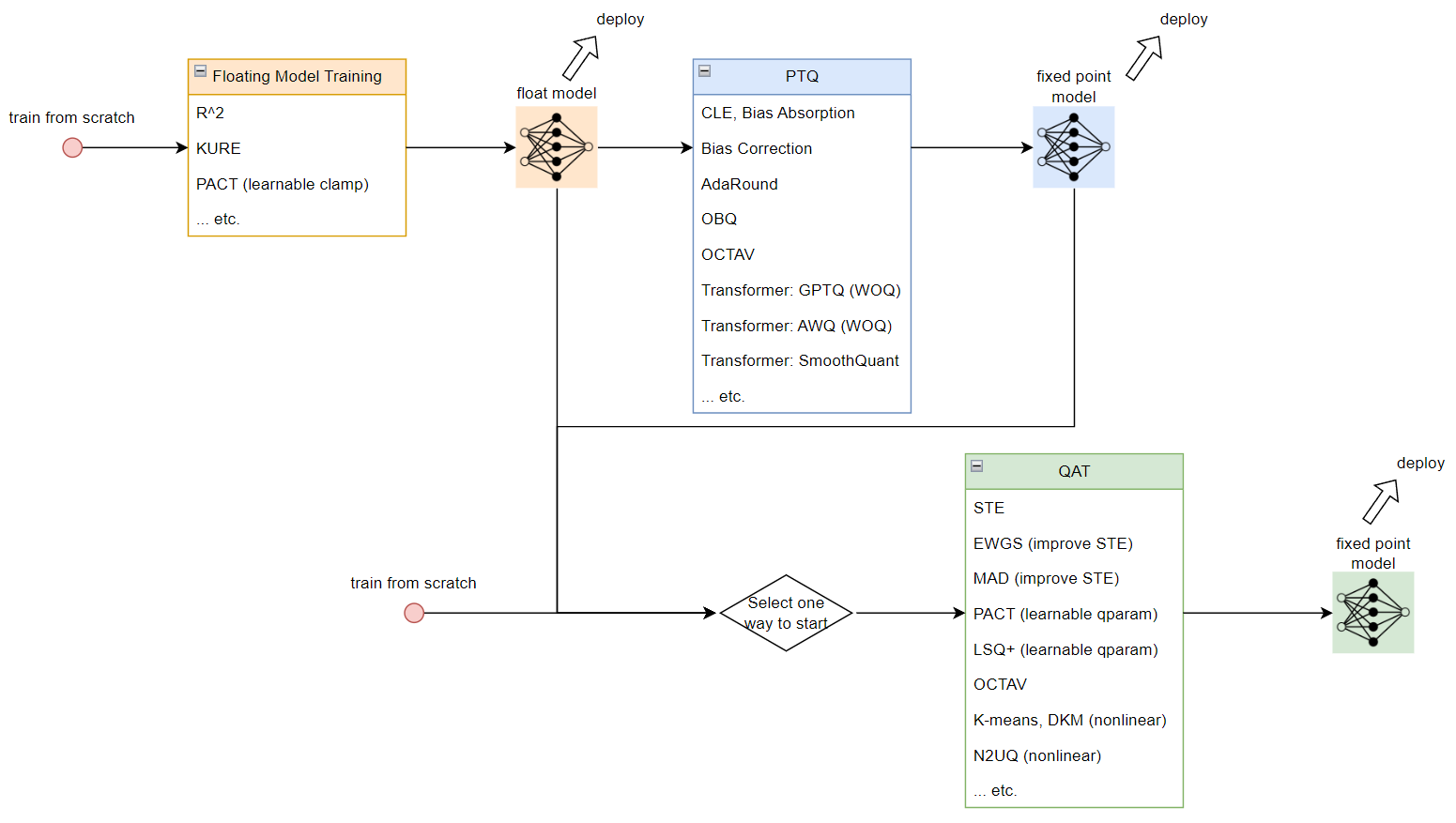 Post Training Quantization (PTQ) 稱事後量化. Quantization Aware Training (QAT) 表示訓練時考慮量化造成的損失來做訓練
Post Training Quantization (PTQ) 稱事後量化. Quantization Aware Training (QAT) 表示訓練時考慮量化造成的損失來做訓練
為了得到 fixed point model 可以對事先訓練好的 float model 做 PTQ 或 QAT, 或是直接從 QAT 流程開始
同時 QAT 也可以用 PTQ 來初始化訓練. 如果要從 float model 開始做量化的話, 可以考慮在訓練 float model 時就對之後量化能更加友善的技術 (如 R^2, KURE, PACT)
接著對每個技術點盡量以最簡單的方式解說. 如果對量化還不是那麼熟悉, 建議參考一下文章後半段的”簡單回顧量化”

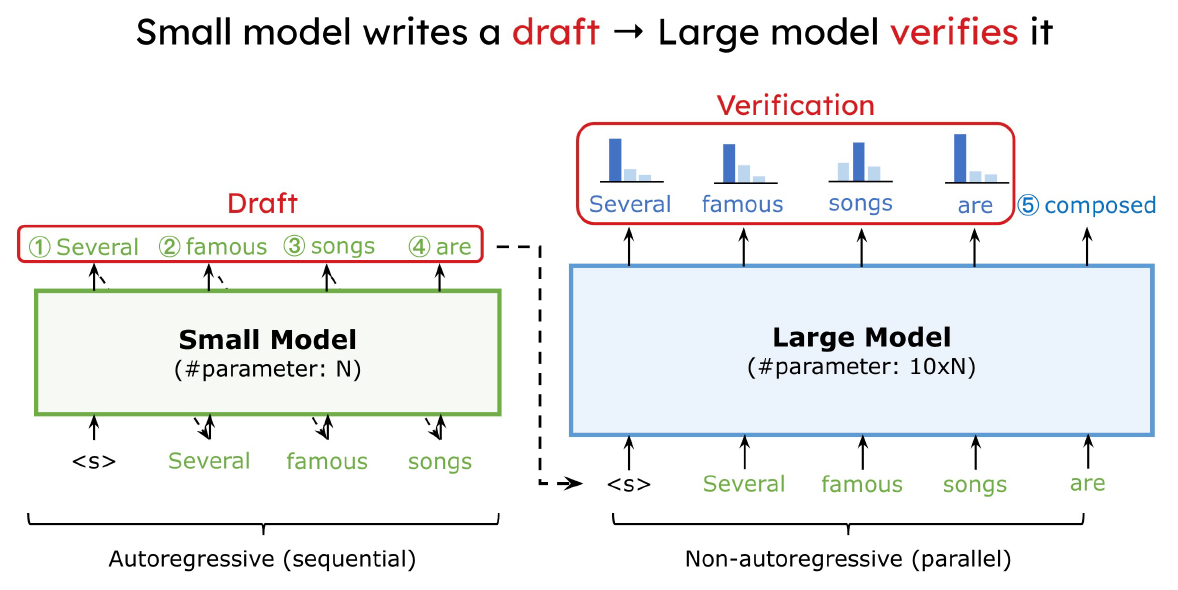 利用 small model 先提出一些 draft tokens, 然後用 large model 來驗證. 如果大部分都接受, 直覺上可以省去很多 large model 的呼叫次數, 因此加速. 方法十分簡單, 不過其實魔鬼藏在細節裡, 跟原本只使用 large model 的方法比較有幾個問題要回答:
利用 small model 先提出一些 draft tokens, 然後用 large model 來驗證. 如果大部分都接受, 直覺上可以省去很多 large model 的呼叫次數, 因此加速. 方法十分簡單, 不過其實魔鬼藏在細節裡, 跟原本只使用 large model 的方法比較有幾個問題要回答: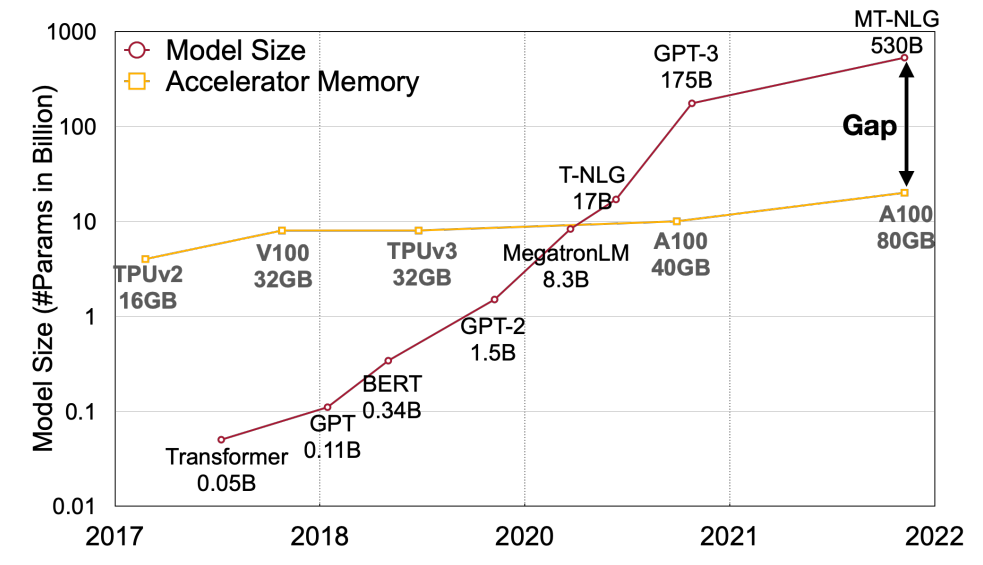 如何降低 memory 使用量將變的很關鍵, 因此 Activation-aware Weight Quantization (AWQ) 這篇文章就專注在 Weight Only Quantization (WOQ), 顧名思義就是 weight 使用 integer 4/3 bits, activations 仍維持 FP16.
如何降低 memory 使用量將變的很關鍵, 因此 Activation-aware Weight Quantization (AWQ) 這篇文章就專注在 Weight Only Quantization (WOQ), 顧名思義就是 weight 使用 integer 4/3 bits, activations 仍維持 FP16.